最近在做基于GPU的并行BitonicSort排序,中间用到了矩阵转置。觉得矩阵转置虽然简单,但一个好的矩阵转置优化却很好表达了GPU程序优化的几个基本要素。所以记录下。这里GPU接口还是用Directx11的DirectCompute,然后为了便于着重算法重点,这里我们只讨论HLSL的代码。
最简单的GPU矩阵转置大家应该可以想到了,就是把X和Y做一个对换。
//Matrix Transpose Code
StructuredBuffer<int> inData;
RWStructuredBuffer<int> outData;
[numthreads(TRANSPOSE_BLOCK_SIZE,TRANSPOSE_BLOCK_SIZE,1)]
void MatrixTranspose(uint3 Gid : SV_GroupID,
uint3 DTid : SV_DispatchThreadID,
uint3 GTid : SV_GroupThreadID,
uint GI : SV_GroupIndex)
{
if(DTid.x<g_iWidth&&DTid.y<g_iHeight)
{
uint2 XY = DTid.yx ;
outData[DTid.x* g_iHeight + DTid.y] = inData[DTid.y*g_iWidth+DTid.x];
}
}
但随机的读写对GPU来说效率很低,我们应该充分利用每个thread group的shared memory。对shared memory我的个人理解是每个thread group都有的一个专属高速cache,然后每个thread group只管自己的这块shared memory,对别的thread group的shared memory一无所知。thread线程对这块share memory的读写速度要比直接全局随机读写要快的多,所以我们应该好好利用shared momery来为我们的程序提速。
如何利用shared memory呢。一句话就是把数据分成不同的相对独立(或者暂时相对独立)的小块,分别载入各个thread group的shared memory中。然后再分别处理整合。
利用shared memory后的代码如下:
//Matrix Transpose Code
groupshared int transpose_shared_data[TRANSPOSE_BLOCK_SIZE*TRANSPOSE_BLOCK_SIZE];
[numthreads(TRANSPOSE_BLOCK_SIZE,TRANSPOSE_BLOCK_SIZE,1)]
void MatrixTranspose(uint3 Gid : SV_GroupID,
uint3 DTid : SV_DispatchThreadID,
uint3 GTid : SV_GroupThreadID,
uint GI : SV_GroupIndex)
{
if(DTid.x<g_iWidth&&DTid.y<g_iHeight)
{
transpose_shared_data[GI]=inData[DTid.y*g_iWidth+DTid.x];
}
GroupMemoryBarrierWithGroupSync();
if(DTid.x<g_iWidth&&DTid.y<g_iHeight)
{
uint2 XY = DTid.yx ;
outData[XY.y * g_iHeight + XY.x] = transpose_shared_data[GTid.y * TRANSPOSE_BLOCK_SIZE + GTid.x];
}
}
最后一个优化我大概知道是什么意思,但是细节我有点纠结,这个优化是是参考DirectxSDK的ComputeSort这个代码的。它意思是我们用高速的tranpose_shared_data的行,写入到慢速的随机读写显存outData的列。因为列数据在显存中是不连续的,那么写入不连续的数据就会比较慢,而且outData本来就慢,写入它不连续地址的显存就更加慢了。为此我们要用高速的tranpose_shared_data的列,写入到慢速的outData的行。
//Matrix Transpose Code
groupshared int transpose_shared_data[TRANSPOSE_BLOCK_SIZE*TRANSPOSE_BLOCK_SIZE];
[numthreads(TRANSPOSE_BLOCK_SIZE,TRANSPOSE_BLOCK_SIZE,1)]
void MatrixTranspose(uint3 Gid : SV_GroupID,
uint3 DTid : SV_DispatchThreadID,
uint3 GTid : SV_GroupThreadID,
uint GI : SV_GroupIndex)
{
if(DTid.x<g_iWidth&&DTid.y<g_iHeight)
{
transpose_shared_data[GI]=inData[DTid.y*g_iWidth+DTid.x];
}
GroupMemoryBarrierWithGroupSync();
if(DTid.x<g_iWidth&&DTid.y<g_iHeight)
{
uint2 XY=DTid.yx+GTid.xy-GTid.yx;
outData[XY.y*g_iHeight+XY.x]=transpose_shared_data[GTid.x*TRANSPOSE_BLOCK_SIZE+GTid.y];
}
}
注意加粗的uint2 XY=DTid.yx+GTid.xy-GTid.yx; 因为这里是用的transpose_shared_data的列,所以线程坐标和数据坐标是不一样了,所以要加上这么一个偏移。
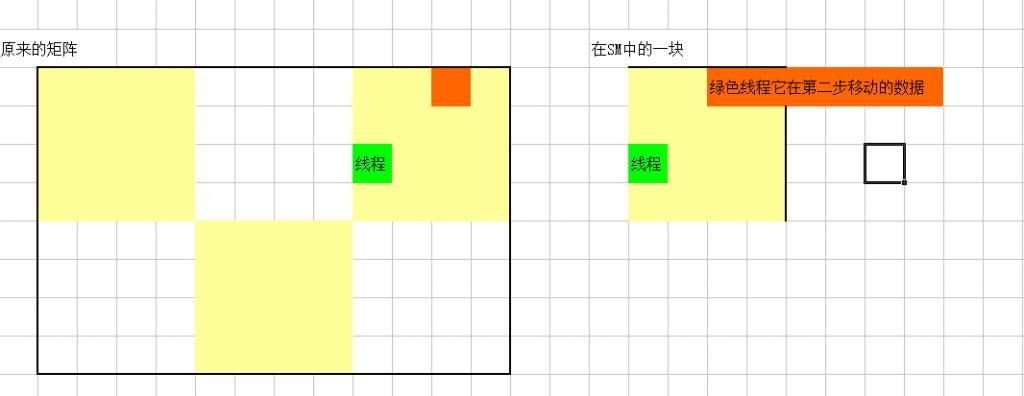

但是这个优化让我不明白的地方是既然所有的线程都是并发的,怎么会有所谓连续的问题呢。无论是用shared memory的行还是列,反正都是并行的,应该不存在所谓是行还是列,是否连续的问题啊。有点纠结。