1. 全文检索介绍
1.1. 全文检索是什么
终于有时间来介绍一下之前学过的全文检索了。按照百度上的解释,全文检索的概念是:
全文检索是计算机程序通过扫描文章中的每一个词,对每一个词建立一个索 引,指明该词在文章中出现的次数和位置。当用户查询时根据建立的索引查 找,类似于通过字典的检索字表查字的过程。
通俗来说,全文检索就是分解查询条件的信息,然后查询出跟分解查询条件后的信息匹配的信息记录。最好的例子就是百度:
通过将查询条件“在你来之前我们已经是冠军了”分解成“在你来之前”、“已经是”、“冠军了”等信息再去匹配相关信息查询出来。这种搜索方式就是全文检索。
1.2. 全文检索和数据库查询有什么不同
看到这里,也许会有人会说全文检索和数据库查询都是查询,应该差别不大吧!
这其中的差别可以用下面表情包来表达了。





如果数据库能够很好地解决全文检索的问题,那就应该不会有lucene的出现了。数据库查询的方式比较古板,最多就是能前后匹配,限制比较大。
select xxx from xxx where xxx like ‘%在你来之前我们已经是冠军了%’
这样的语句查询条件多一个字和少一个子的查询结果差别比较大。而且当数据比较大,遇到上千万过亿的数据的时候,数据库查询的效率会比较低。
而全文检索恰好就是为了应对这种情况而诞生的。
全文检索可以处理上亿的数据而保持效率,并且搜索出来的结果会更智能。
2. Lucene介绍
Lucene是什么呢?为什么要介绍它呢?
因为Lucene是一套用于全文检索和搜寻的开源程序库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程序接口(API),能够做全文索引和搜寻,在Java开发环境里Lucene是一个成熟的免费开放源代码工具。
当然也可以用Solr和Elasticsearch来开发,但这里讲的是用lucene来开发,其它的就不展开了。不过值得一提的是,Solr和Elasticsearch都是基于Lucene开发的搜索引擎产品。
2.1. Lucene实现全文检索原理
这里简单说一下Lucene实现全文检索的原理:
Lucene技术可以类比构造一个数据库,但lucene是通过获取文本的信息,通过分词器分词建立索引构成索引库(类比数据库)。然后就可以通过lucene的查询对象去建立好索引的数据或者文档了。lucene中的一个document对应数据库的一条记录,而一个feild则对应数据库的一个字段。
注意:lucene适合对纯文本(txt)建立索引,理论上对doc,ppt,cls等也可以,但测试结果不佳。对pdf等文件应该使用poi等工具进行数据转换,再建立索引。
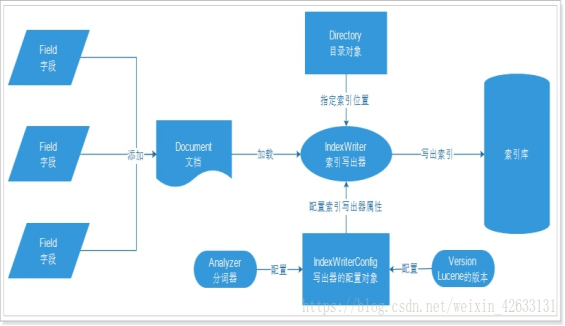
该图参考来自:https://blog.csdn.net/weixin_42633131/article/details/82873731
2.2. 分词器
分词器是lucene中用来对文本信息进行信息提取,建立索引的算法器。虽然lucene本身自备了几个分词器,但是只对英文有效,关于中文的效果都不算好。因此这里推荐一个中文分词器:IKAnalyzer
2.2.1. IKAnalyzer分词器
IK作为比较老派,且比较出名的中文分词器。分词效果好,并且可以拓展新词是个比较好的选择。
缺点是自从更新到2012版本后,就停止更新了。尽管有个说法是,IK分词器已经到达中文分词的瓶颈了,就是说这个产品已经很完美了,不需要再更新,后面无非是在拓展文件里面添加新词就可以了。但是,IK分词器只支持Lucene4版本,不支持后面版本的lucene, 若要支持高版本的lucene则需要对IK分词器进行源码修改。
最近在github看到有关的更新,详情可以查看:https://github.com/magese/ik-analyzer-solr
3. java引入Lucene8.1.0
3.1. 导入相关包
到官网下载Lucene的jar包:http://lucene.apache.org/
到github下载IKAnalyzer的jar包
需要导入的jar包如下:

同时也要引入IKAnalyzer的相关文件:
IKAnalyzer.cfg.xml
ext.dic
stopword.dic
3.1.1. IKAnalyzer.cfg.xml
IKAnalyzer.cfg.xml文件要放在src目录下,否则分词器会无法获取到拓展词或者停止词。该文件配置ext.dic和stopword.dic这两个文件的路径。
1 <?xml version="1.0" encoding="UTF-8"?> 2 3 <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> 4 5 <properties> 6 7 <comment>IK Analyzer 扩展配置</comment> 8 9 <!--用户可以在这里配置自己的扩展字典 --> 10 11 <entry key="ext_dict">ext.dic;</entry> 12 13 <!--用户可以在这里配置自己的扩展停止词字典--> 14 15 <entry key="ext_stopwords">stopword.dic;</entry> 16 17 </properties>
3.1.2. ext.dic
ext.dic是拓展词库,分词器会对拓展词库里面的词语不再分词。
3.1.3. stopword.dic
stopword.dic是停止词库,分词器会对将与停止词库匹配的词语过滤掉。
3.1.4. 分词测试
这里可以写一个方法测试分词效果:
1 import java.io.IOException; 2 import java.io.StringReader; 3 import org.wltea.analyzer.core.IKSegmenter; 4 import org.wltea.analyzer.core.Lexeme; 5 6 public class IkanalyzerTest { 7 8 private static void analysisString() { 9 10 String text="在你来之前我们已经是冠军了"; 11 12 StringReader sr = new StringReader(text); 13 14 IKSegmenter ik = new IKSegmenter(sr, true); 15 16 Lexeme lex=null; 17 18 try { 19 20 while((lex=ik.next())!=null){ 21 22 // System.out.print(lex.getLexemeText()+"|"); 23 24 System.out.println(lex.getLexemeText()); 25 26 } 27 28 } catch (IOException e) { 29 30 e.printStackTrace(); 31 32 } finally { 33 34 // 关闭流资源 35 36 if(sr != null) { 37 38 sr.close(); 39 40 } 41 42 } 43 44 } 45 46 47 public static void main(String[] args) { 48 49 analysisString(); 50 51 52 } 53 54 }
测试结果:
加载扩展词典:ext.dic
加载扩展停止词典:stopword.dic
在你
来
之前
我们
已经是
冠军