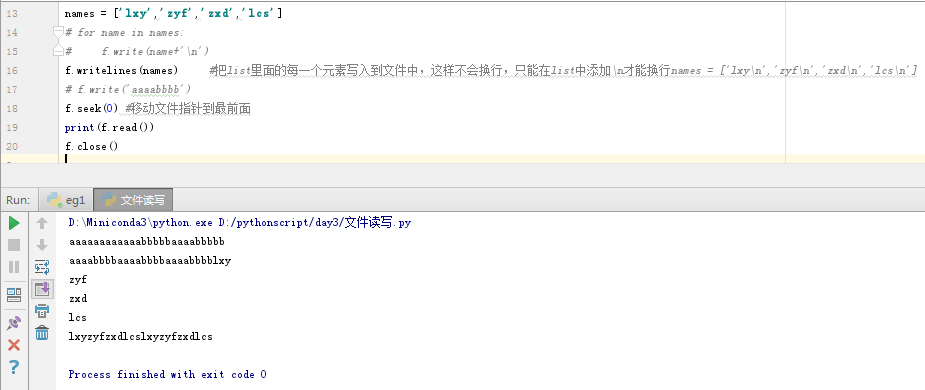
1、字符串常用方法
name1 = 'shuipingzuo'
print(name1.capitalize()) #将字符串首字母大写
print(name1.center(50,'*')) #将字符串居中,50表示整个字符串长度50,如果字符串本身不够50,则后后面定义的*号前后补齐
print(name1.count('i')) #查询指定字符串的次数
以上示例运行结果如下:
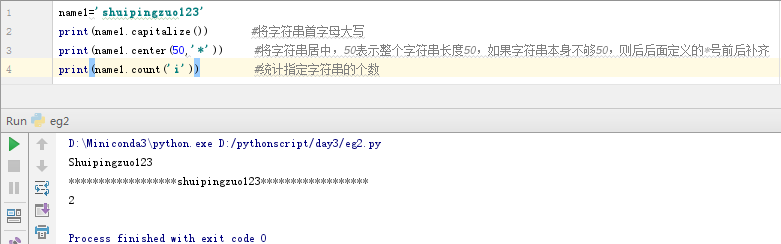
指定字符串以xxx开头或以xxx结尾的字符串方法:
name2 = '18612345678.jpg'
print(name2.endswith('.jpg')) #判断字符串是否以xxx开头,返回的是布尔类型结果,如果不是以这个结尾则返回False
print(name2.startswith('188')) #判断字符串是否以xxx结尾,返回的是布尔类型结果,如果不是以这个结尾则返回False
备注说明:布尔类型只有True或False,且在python中布尔类型首字母必须大写。
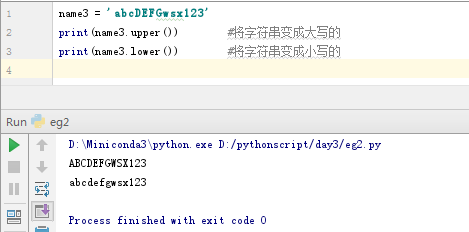
指定字符串转换为大写或小写的方法:
name3 = 'aaaUISDbbe'
print(name3.upper()) #将字符串变成大写的
print(name3.lower()) #将字符串变成小写的
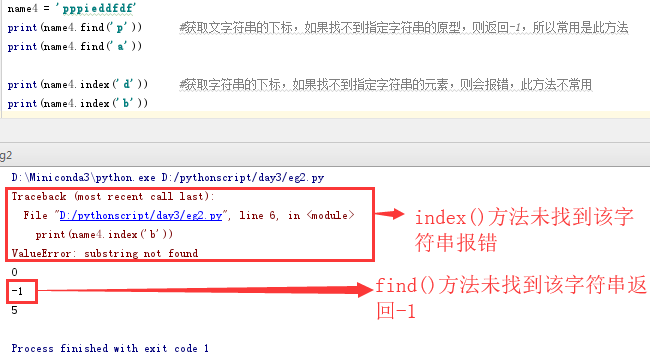
name4 = 'ppeqewwre'
print(name4.find('p')) #获取文字符串的下标,如果找不到指定字符串的原型,则返回-1,所以常用是此方法
print(name4.index('p')) #获取字符串的下标,如果找不到指定字符串的元素,则会报错,此方法不常用
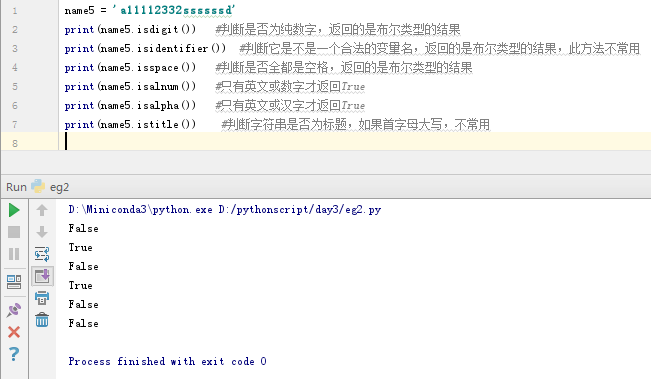
name5 = 'a11112332ssssssd'
print(name5.isdigit()) #判断是否为纯数字,返回的是布尔类型的结果
print(name5.isidentifier()) #判断它是不是一个合法的变量名,返回的是布尔类型的结果,此方法不常用
print(name5.isspace()) #判断是否全都是空格,返回的是布尔类型的结果
print(name5.isalnum()) #只有英文或数字才返回True
print(name5.isalpha()) #只有英文或汉字才返回True
print(name5.istitle()) #判断字符串是否为标题,如果首字母大写,不常用
name6 = ' aaabbb
cccd '
print('打印结果1:',name6.strip()) #去掉字符串两边指定的字符串,如果strip()的括号里为空,默认去掉两边的空格和换行符
print('打印结果2:',name6.lstrip()) #只去掉字符串左边指定的字符串
print('打印结果3:',name6.rstrip()) #只去掉字符串右边指定的字符串

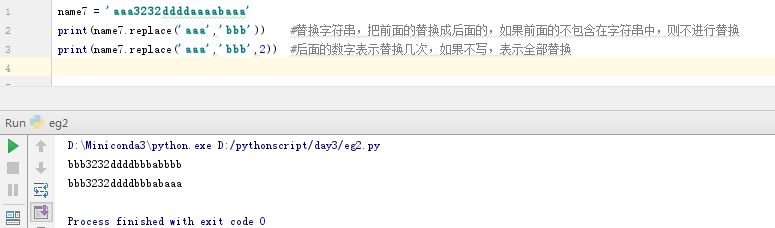
name7 = 'aaa3232ddddaaaabaaa'
print(name7.replace('aaa','bbb')) #替换字符串,把前面的替换成后面的,如果前面的不包含在字符串中,则不进行替换
print(name7.replace('aaa','bbb',2)) #后面的数字表示替换几次,如果不写,表示全部替换
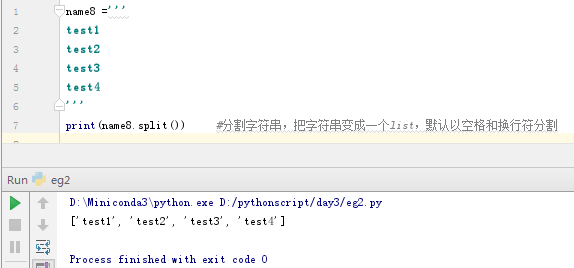
字符串分割:
name8 ='''
test1
test2
test3
test4
'''
print(name8.split()) #分割字符串,把字符串变成一个list,默认以空格和换行符分割
name9 = '''test1,test2,test3'''
print(name9.split(',')) #此方式如果是逗号分开字符串的,则如果直接使用splist()去分割的话,分割完list中只有一个元素,如果要分成三个,则以逗号作为分割符即可
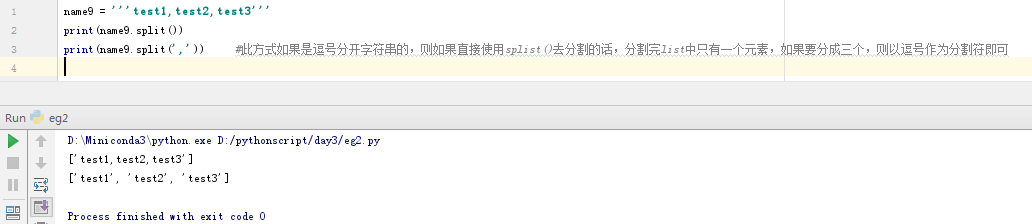
name10 = '5'
print(name10.zfill(2)) #将字符串前面补0,数字2表示字符串长度为2,如果字符串只有1位,则表示'05',如果字符串本来有2位,则长度已达到2位,此处不再补0;
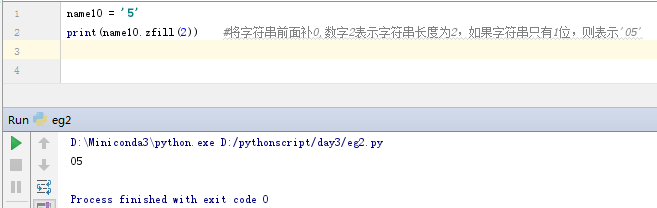
stus = ['test1', 'test2', 'test3', 'test4']
print('、'.join(stus)) #把list变成字符串的,以某个字符串连接,返回的是一个字符串;此示例中以顿号将字符串进行连接
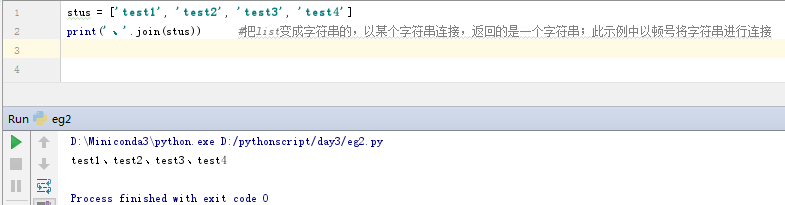
import string
print(string.ascii_letters) #获取26个大、小写英文字母
print(string.ascii_lowercase) #获取26个小写英文字母
print(string.ascii_uppercase) #获取26个大写英文字母
print(string.digits)
#获取0-9的数字
print(string.punctuation) #获取所有的特殊字符
列表与字符串进行for循环都是通过下表获取对应的元素值示例:
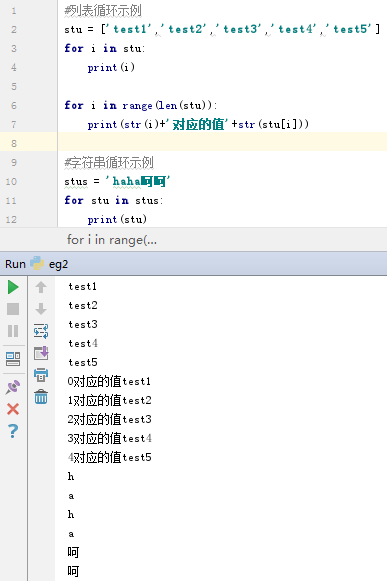
stu = ['test1','test2','test3','test4','test5']
for i in stu:
print(i)
for i in range(len(stu)):
print(str(i)+'对应的值'+str(stu[i]))
stus = 'haha呵呵'
for stu in stus:
print(stu)
2 、切片
切片也就是另一种方式获取列表的值,它可以获取多个元素,可以理解为,从第几个元素开始,到第几个元素结束,获取他们之间的值,格式是name:[1:10],比如说要获取name的第一个元素到第五个元素,就可以用name[0:6],切片是不包含后面那个元素的值的,记住顾头不顾尾;前面的下标如果是0的话,可以省略不写,这样写,name[:6],切片后面还有可以写一个参数,叫做步长,也就是隔多少个元素,取一次,默认可以不写,也就是隔一个取一次,切片操作也可以对字符串使用,和列表的用法一样。

import string
num = list(string.digits) #强制类型转换,将一个字符串强制转换为列表
print(num)
print(num[0:11:2]) #最后一个数字表示步长,隔几个取一次,默认不写是隔一个取一次
print(num[::-2]) #如果步长是负数,就从右往左开始取值,数值扔表示步长,默认是从左往右取值
# 步长为负
# 前面两个都不写:则取反
# 写第一个,第二个不写:从第一个向左取
# 写第二个,第一个不写:从第二个向左取
# 写两个:开始位置在结束位置的左侧:取不到
# 写两个:开始位置在结束位置右侧:从右往左取
3、元组
元组,也是一个list,但它是不可变的,即元组一旦创建好之后,就不能修改元组中的值;
#元组,元组也是一个list,但它是不可变的
cities = ('beijing','shanghai') #元组一旦定义好,就不能再变了
print(cities[0])
print(cities.count('beijing'))
print(cities.index('beijing'))

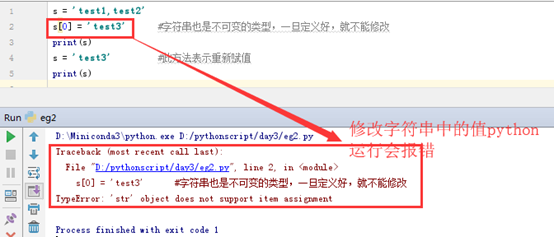
字符串也是一个不可变的类型,一旦定义好,就不能修改
s = 'test1,test2'
s[0] =
'test3' #字符串也是不可变的类型,一旦定义好,就不能修改
s = 'test3' #此方法表示重新赋值
s1 = 'abcEFGabc'
s1.replace('abc','') #如果使用此方法,必须将该修改赋值给一个新的变量,即s2 = s1.replace('abc','')
print(s1) #运行之后返回的s1值仍为abcEFGabc

列表可变的示例:
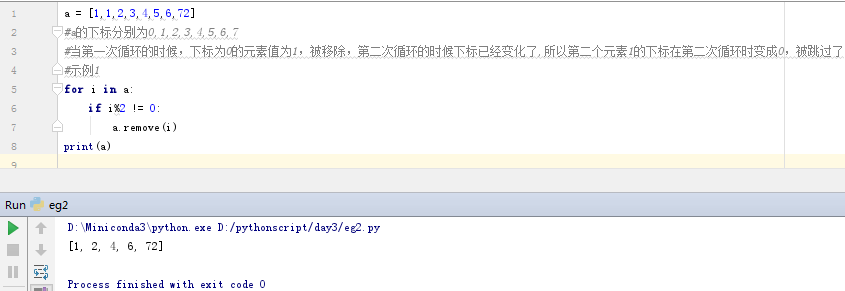
a = [1,1,2,3,4,5,6,72]
#a的下标分别为0,1,2,3,4,5,6,7
#当第一次循环的时候,下标为0的元素值为1,被移除,第二次循环的时候下标已经变化了,所以第二个元素1的下标在第二次循环时变成0,被跳过了
#示例1
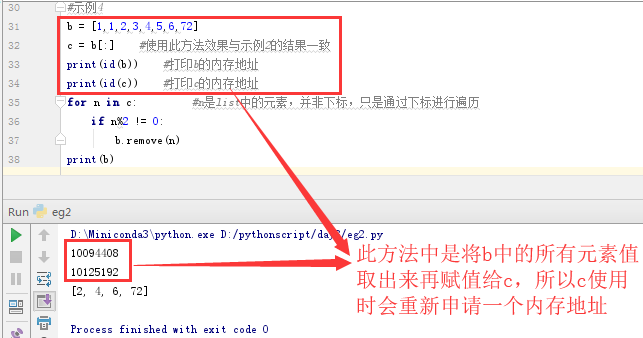
b = [1,1,2,3,4,5,6,72] #使用此方法可以将a中的两个元素1被删除掉了,b和a的值一样,在b中找到要删的值,再去a中找到那个值去删掉
#示例2
b = a #使用此方法仍然不会删除掉
#示例3
b = a[:] #使用此方法效果与示例1的结果一致
#
print(id(a)) #打印a的内存地址
print(id(b)) #打印b的内存地址
#
for i in b: #i是list中的元素,并非下标,只是通过下标进行遍历
if i%2 != 0:
a.remove(i)
print(a)
说明:由于上述代码有简化,按实际示例分别运行如下:


字符串不可变的示例:
a = 'haha'
b = a
print(id(a)) #打印a的内存地址
print(id(b)) #打印b的内存地址
a = 'asss'
print(id(a)) #打印a的内存地址
print(id(b)) #打印b的内存地址

#变量定义
#方法一:
a,b,c,d = 1,2,3,4
#方法二:
a = b = c = d = 0
#方法三:
a = 1
#示例1
a,b = 1,2
#不引入第三方变量的方式把a,b交换
#方法1:
b,a = a,b
print(a,b)

#方法2: 此方法是在较简单的运算中使用
a = 1
b = 2
a = a+b
b = a-b
a = a-b
print(a,b)

#非空即真,非0即真
#实现同样的功能,代码越少越牛逼
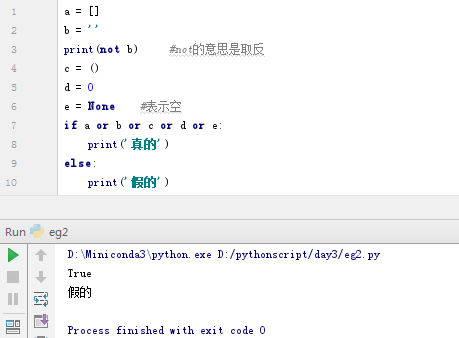
a = []
b = ''
print(not b) #not的意思是取反
c = ()
d = 0
e = None #表示空
if a or b or c or d or e:
print('真的')
else:
print('假的')
4、字典
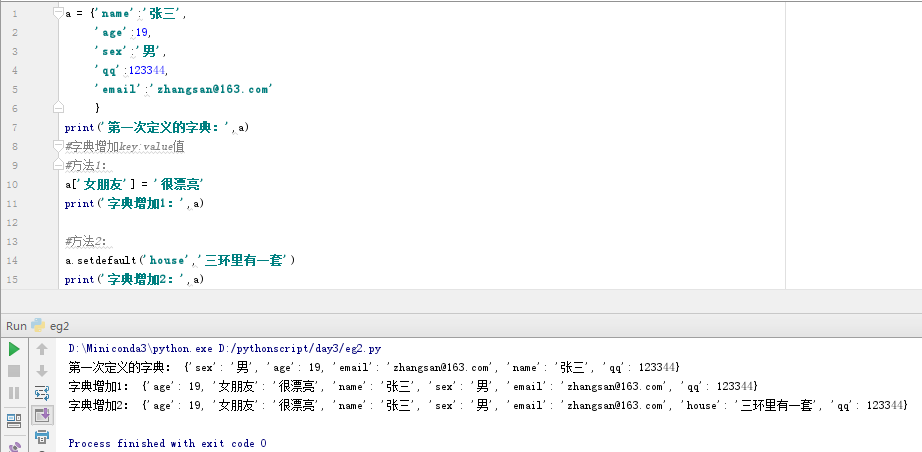
字典的定义使用{},大括号,每个值用逗号“,”隔开,key和value使用冒号“:”分隔;
字典是无序的,因为字典是通过key取值的,所有没有顺序,每次打印顺序都会变化;
字典存储是key:value格式存储的,字典里的key不能重复必须唯一;
#字典存储是key:value格式存储的,字典里的key不能重复必须唯一
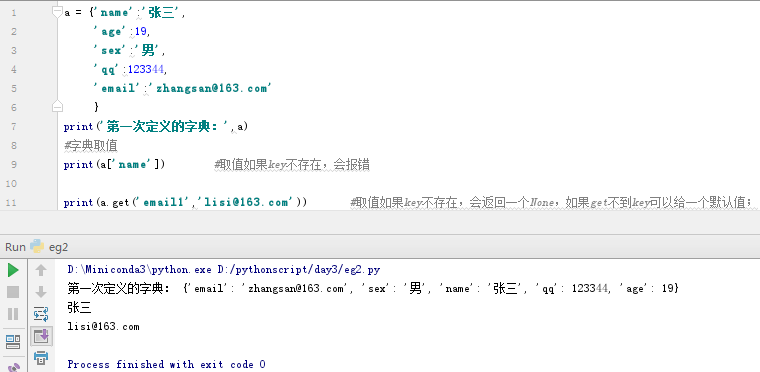
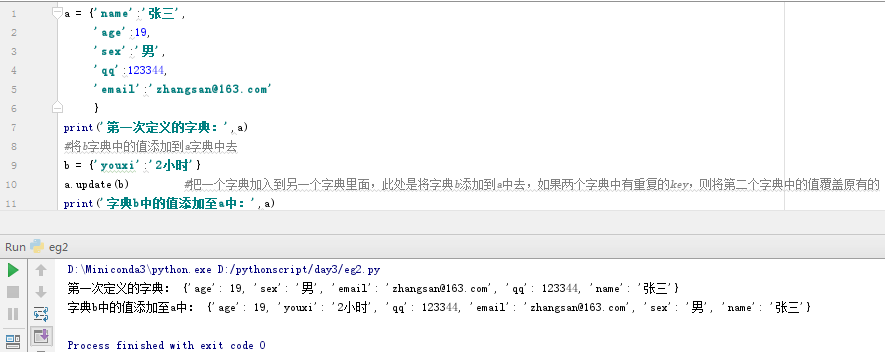
a = {'name':'张三',
'age':19,
'sex':'男',
'qq':123344,
'email':'zhangsan@163.com'
}
print(a)

#字典增加key:value值
#方法1:
a['女朋友'] = '很漂亮'
print('字典增加1:',a)
#方法2:
a.setdefault('house','三环里有一套')
print('字典增加2:',a)
#字典修改
a['age'] = 38 #字典中没有的话增加,有的话修改值
print(a)

#字典删除
#方法1:
a.pop('qq') #删除时,如果key不存在,会报错
print('字典删除1:',a)
#方法2:
a.popitem() #随机删除一个key
print('字典删除2:',a)
#方法3:
del a['age'] #删除时,如果key不存在,会报错
print('字典删除3:',a)

#字典取值
print(a['name']) #取值如果key不存在,会报错
print(a.get('email1','lisi@163.com')) #取值如果key不存在,会返回一个None,如果get不到key可以给一个默认值;
#将b字典中的值添加到a字典中去
b = {'youxi':'2小时'}
a.update(b) #把一个字典加入到另一个字典里面,此处是将字典b添加到a中去,如果两个字典中有重复的key,则将第二个字典中的值覆盖原有的
print('字典b中的值添加至a中:',a)
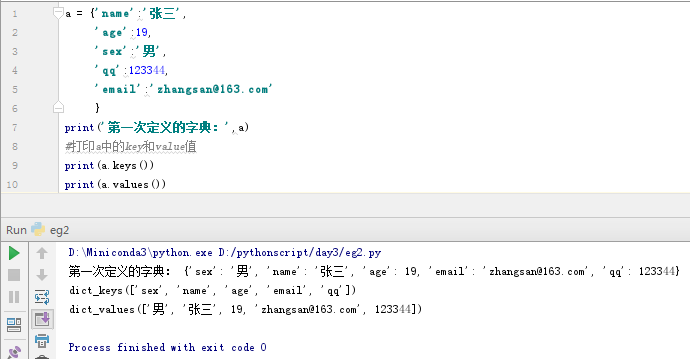
#打印a中的key和value值
print(a.keys())
print(a.values())
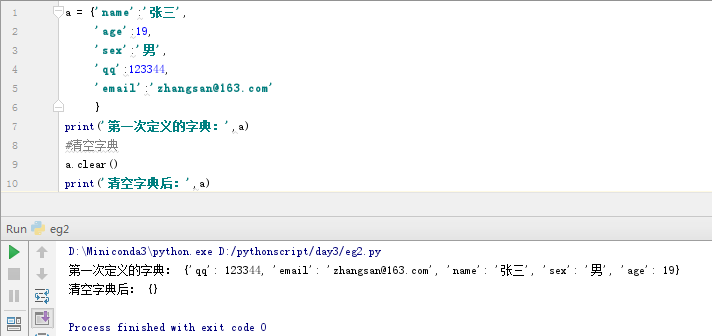
#清空字典
a.clear()
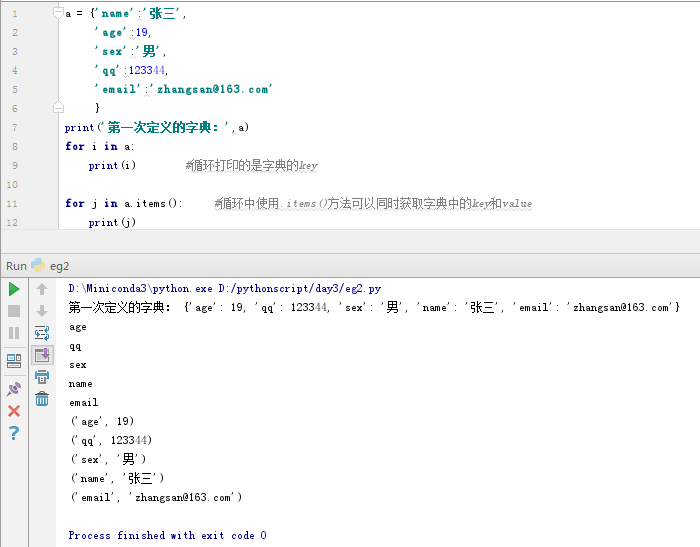
for i in a:
print(i) #循环打印的是字典的key
for j in a.items(): #循环中使用.items()方法可以同时获取字典中的key和value
print(j)
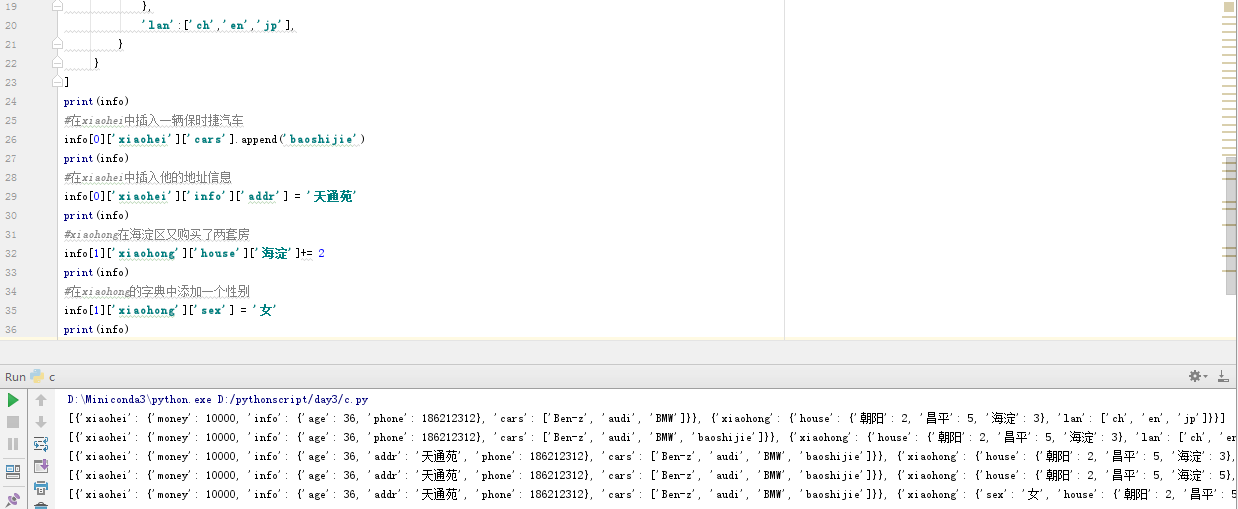
#多层列表字典取值示例
info = [
{
'xiaohei':
{
'money':10000,
'cars':['Ben-z','audi','BMW'],
'info': {
'phone':186212312,
'age':36}
}
},
{'xiaohong':
{
'house': {
'朝阳':2,
'海淀':3,
'昌平':5
},
'lan':['ch','en','jp'],
}
}
]
print(info)
#在xiaohei中插入一辆保时捷汽车
info[0]['xiaohei']['cars'].append('baoshijie')
print(info)
#在xiaohei中插入他的地址信息
info[0]['xiaohei']['info']['addr'] = '天通苑'
print(info)
#xiaohong在海淀区又购买了两套房
info[1]['xiaohong']['house']['海淀']+= 2
print(info)
#在xiaohong的字典中添加一个性别
info[1]['xiaohong']['sex'] = '女'
print(info)
获取字典的key和value的方法比较:
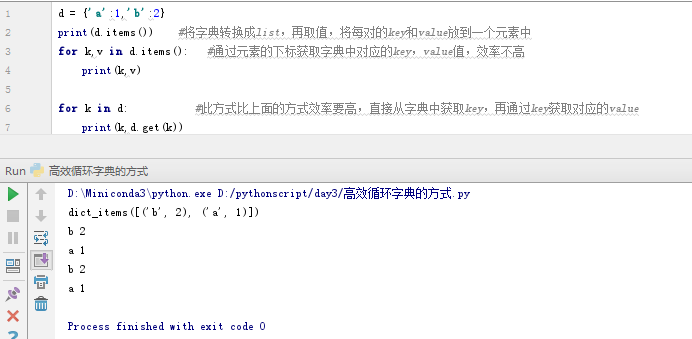
d = {'a':1,'b':2}
print(d.items()) #将字典转换成list,再取值,将每对的key和value放到一个元素中
for k,v in d.items(): #通过元素的下标获取字典中对应的key,value值,效率不高
print(k,v)
for k in d: #此方式比上面的方式效率要高,直接从字典中获取key,再通过key获取对应的value
print(k,d.get(k))
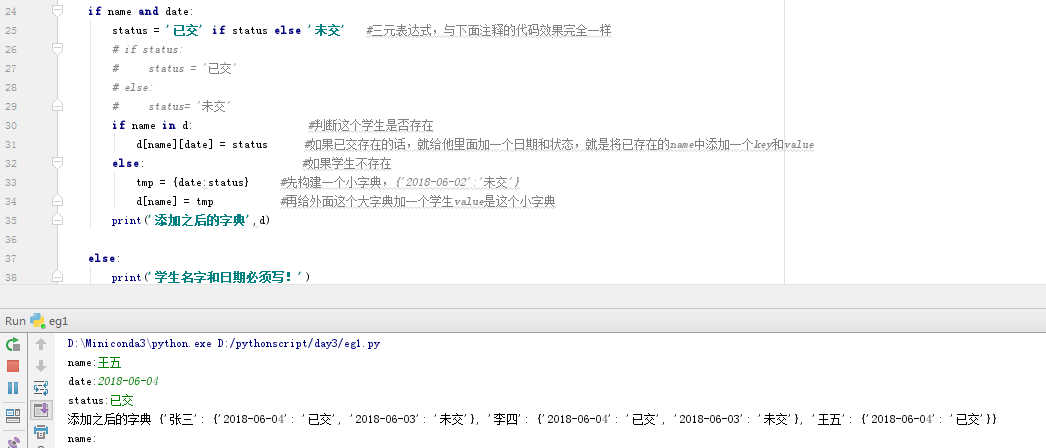
#示例
#记录学生是否交作业的小程序
#学生姓名
#日期
#状态
d = {
'张三':{
'2018-06-03':'未交',
'2018-06-04':'已交'
},
'李四':{
'2018-06-03': '未交',
'2018-06-04': '已交'
}
}
#1、判断名字和日期是否都填
#2、构造好一个字典key是date,value是status
#3、把构造好的字典和之前的字典合并到一起
for i in range(3):
name = input('name:').strip()
date = input('date:').strip()
status = input('status:').strip() #可以不写,如果不写的话,是未交
if name and date:
status = '已交' if status else '未交' #三元表达式,与下面注释的代码效果完全一样
# if status:
# status = '已交'
# else:
# status= '未交'
if name in d: #判断这个学生是否存在
d[name][date] = status #如果已交存在的话,就给他里面加一个日期和状态,就是将已存在的name中添加一个key和value
else: #如果学生不存在
tmp = {date:status} #先构建一个小字典,{'2018-06-02':'未交'}
d[name] = tmp #再给外面这个大字典加一个学生value是这个小字典
print('添加之后的字典',d)
else:
print('学生名字和日期必须写!')
status = '已交' if status else '未交' #三元表达式,与下面注释的代码效果完全一样
# if status:
# status = '已交'
# else:
# status= '未交'
5、文件读写
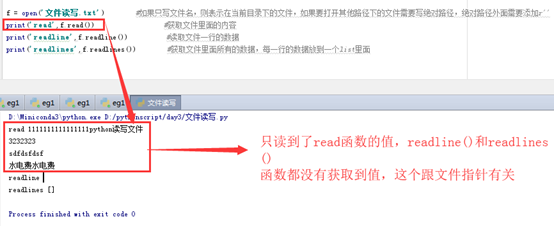
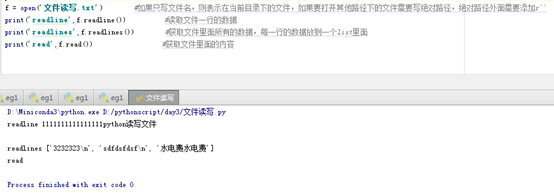
print('readline',f.readline()) #读取文件一行的数据
print('readlines',f.readlines()) #获取文件里面所有的数据,每一行的数据放到一个list里面
print('read',f.read()) #获取文件里面的内容
文件读取是有文件指针的概念,在不同的位置使用不同的read方法读取的值不一样;
只读模式(r)
1、 只能读,不能写,文件不存在会报错
只写模式(w)
覆盖以前文件里面的内容,不能读,文件不存在的话,会自动创建一个
读写模式(r+)
可以读写,打开不存在的文件也会报错
写读模式(w+)
只要和r有关的,文件不存在,肯定会报错
只要和w有关的,文件内容肯定会被清空
追加模式(a+)
能读、能写,不会清空以前的内容,文件不存在会创建;
移动文件指针(f.seek(0) #移动文件指针到最前面)