最近需要造一部分数据,需要用到人名,与其用脚本生成一些随机组合的汉字,不如在网上爬一些看似真实的姓名,所以找来了姓氏大全的网站,网址:http://www.resgain.net/xsdq.html
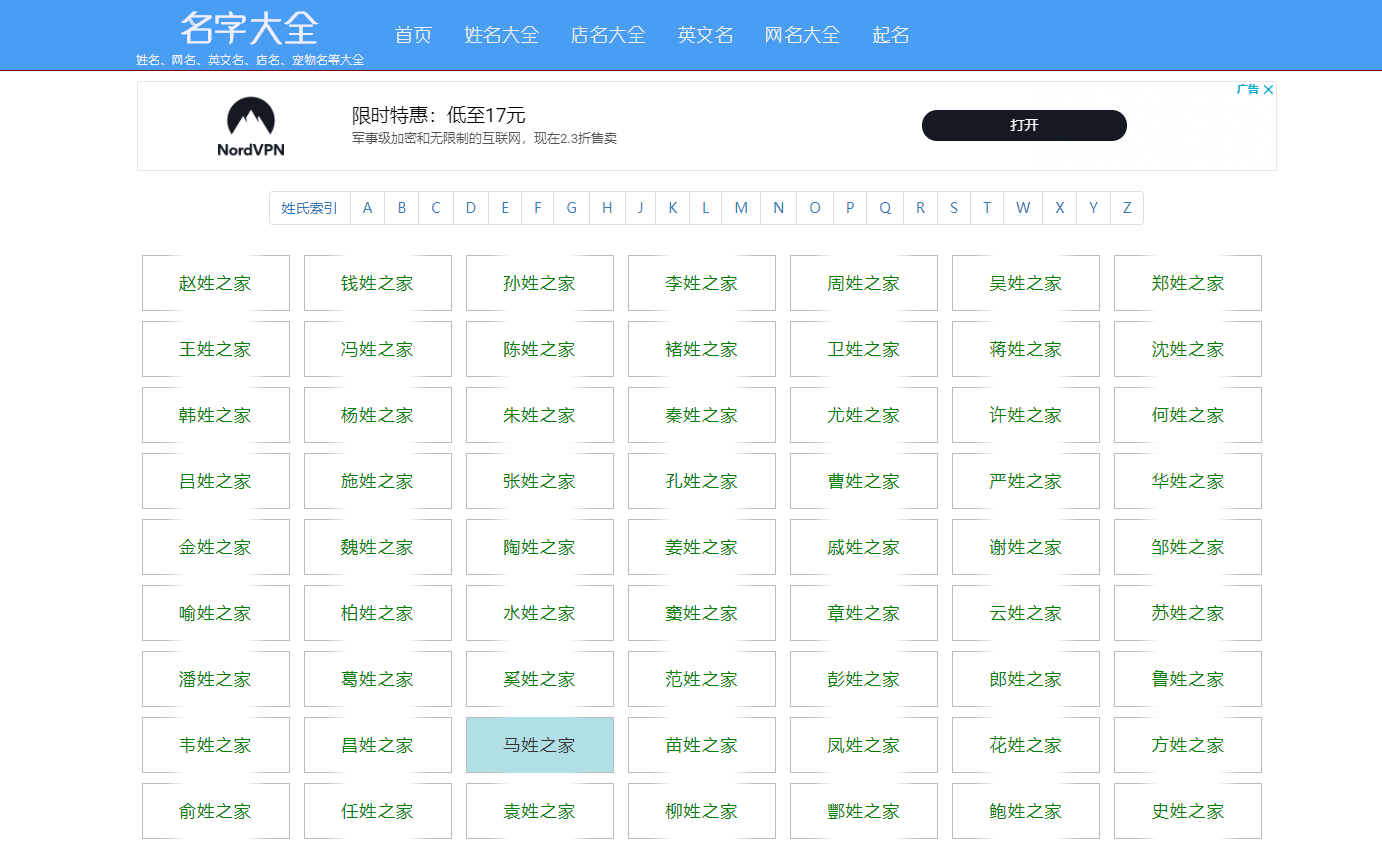
上图可以看到有很多不同的姓氏,每个姓氏(又是一个网页)里边有很多名字,这样轻轻松松就可以搞定一些真实的数据了,
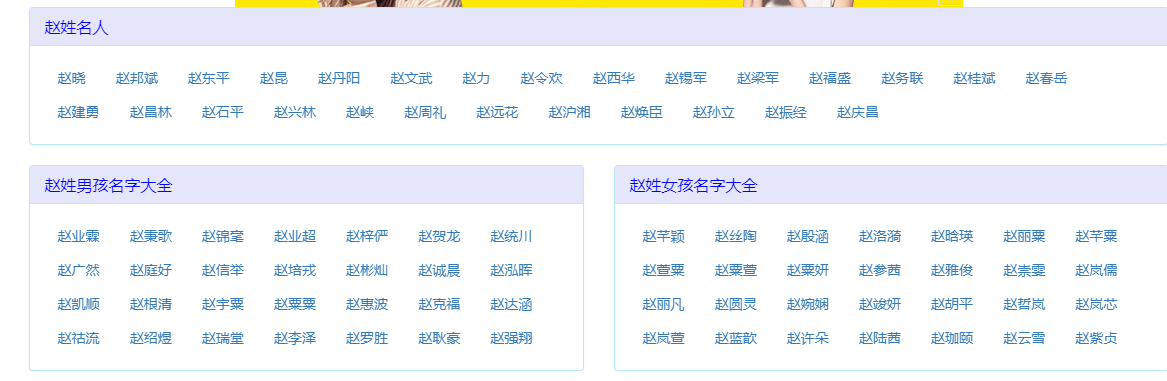
此时只需要获取名字即可。
用到的库有urllib2 bs4,首先就是用urllib2获取请求,然后用beautifulsoup将请求内容生成可分析对象,然后查找标签即可,很简单,上代码好了。
# -*- coding: utf-8 -*-
import urllib2
import sys
from bs4 import BeautifulSoup
reload(sys)
sys.setdefaultencoding("utf-8")
def get_name(url):
name_list = []
request = urllib2.Request(url) # 创建对名字大全网站get请求
result = urllib2.urlopen(request) # 发出请求
soup = BeautifulSoup(result.read(), 'html.parser') # 生成可分析对象
if soup.find_all("a",class_="btn btn2"):
for name in soup.find_all("a",class_="btn btn2")[:15]: # 遍历所有的姓氏链接,此处只获取前15个姓氏
url = 'http:' + name.attrs['href'] #找到姓氏链接,再次返回此函数
get_name(url)
elif soup.find_all('a',class_='btn btn-link'):
for name in soup.find_all('a',class_='btn btn-link')[:10]: #找到不同姓氏的名字,此处只获取每个姓氏的前10个
name_list.append(name.text)
# print name.text
return name_list
if __name__ == '__main__':
url = "http://www.resgain.net/xsdq.html"
get_name(url)