在此之前,我有写过一个.Net的分库,最近在做Java的项目,就顺便做出一个Java版本,这个项目源于我另外的一个业务项目,在这个业务项目中有分表(在一个数据库下有多张表),当时写了一套基于分表的帮助类,随着这个业务的的发展,基于分表的解决方案有一定的弊端,主要有两个:
1. 不能很好的扩展,在一个数据库下面有20张表,当业务繁忙的时候,数据库出现了压力(公司里面多个项目共用一个数据库服务器,有可能是其他项目影响了我的项目),这个时候想要扩展就比较麻烦了, 我可以将其中10张表迁移到另外的机器,同时我的代码路由算法就要改,其实将其中10张表迁移到另外服务器上,就已经类似于分库了。
2. 基于分表对业务的侵入性较高,我要先通过算法得到具体的表索引(即表的编号,比如user_15),然后要将整个索引和表前缀进行拼接才能得到真正的表名。
所以在开源分表分库的项目的时候,我对项目进行了升级,改为分库模式,即有多个数据库,每个数据库一张表,表名都一样,这样你就可以在mybatis中不需要再对表名进行修改。 降低了浸入性,同时也方便后续的扩展,你可以将这些数据库放在一台机器上,也可以在后续数据库服务器性能紧张的时候,将一部分数据库迁移到其他机器上。
最后说一下我当时为什么没有选择开源的解决方案,目前我知道的开源方案包括 sharding-jdbc ,mycat ,但是当时时间紧,任务重,研究熟悉部署这些项目,可能需要1-2天的时间,并且后续使用过程中,出了问题,还需要花时间排查,mycat 是基于分库的,所以并不适合我这个项目,而我的项目中,在操作数据库之前,已经可以知道具体要操作哪张表,对分表的操作也比较简单,但是要得到具体的表索引比较麻烦,是要经过多个key运算得到的,综合所有,我选择了自己写了一个。
项目比较简单,所有和分库相关的都在shardingcore中。 test是测试用的。

shardingcore的项目结构。
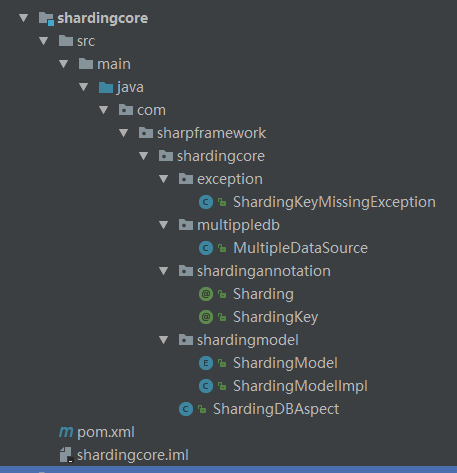
其中MultipleDataSource是为了实现切换数据库连接,这块代码是参考网上数据库读写分离的。
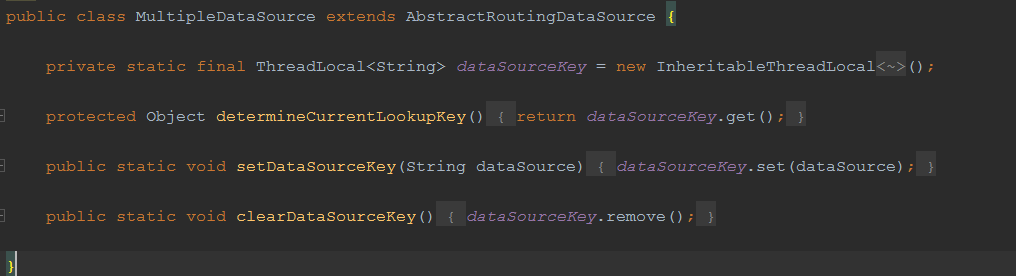
ShardingDBAspect是分库的核心代码。
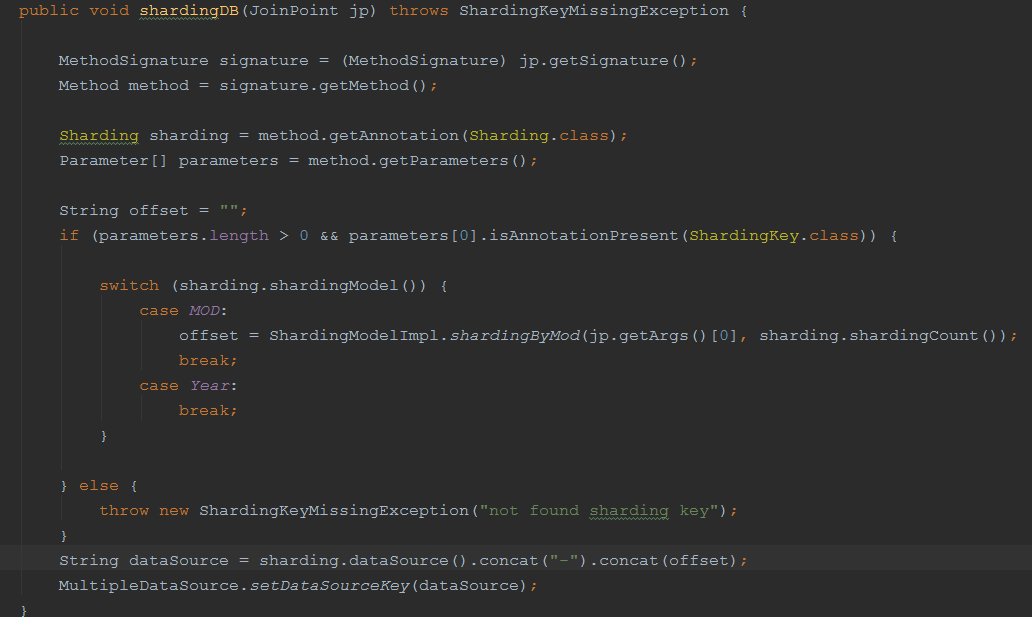
使用shardingcore
我们假设要对user进行分库,分3个库
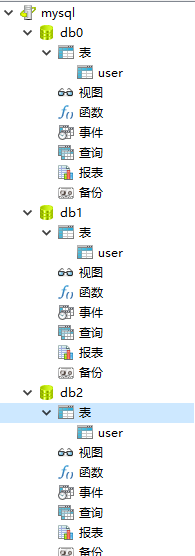
下面是test工程,比较简单就是操作数据库。

这里重点看一下UserDao,如果你想在项目中用到分库,只需要引入shardingcore,对于dao层的需要分库的方法,比如addUser方法,需要有两个地方需要修改,一个是通过@Sharding来标示出分库的基本信息。 ,第二个通过@ShardingKey来标示出要根据哪个参数来分库。其他的代码都不需要动。
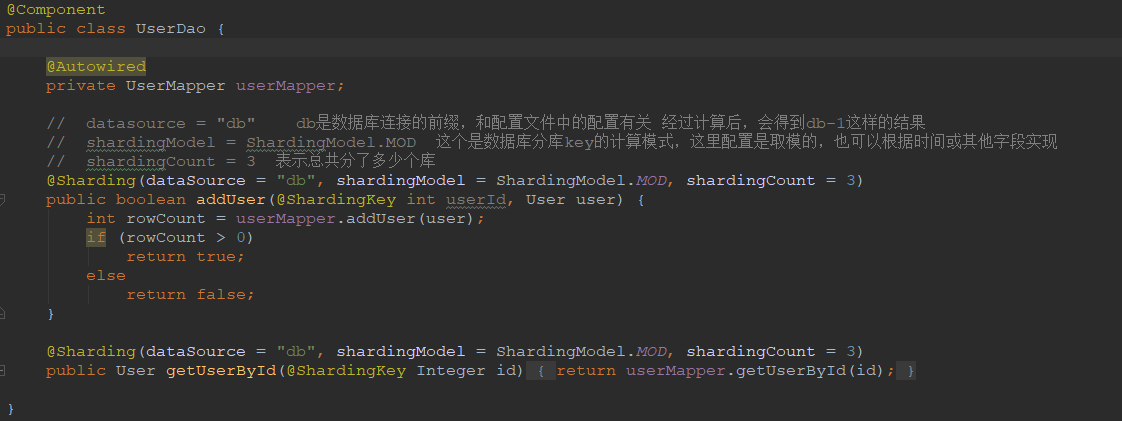
最后要对配置文件做一些修改。
<!-- aop配置,主要是拦截dao层的方法 --> <aop:config> <aop:pointcut expression="execution(public * com.sharpframework.test.repository.*Dao.*(..)) and @annotation(com.sharpframework.shardingcore.shardingannotation.Sharding)" id="shardingpoint"/> <aop:aspect id="adviceRespect" ref="sharding" order="1"> <aop:before pointcut-ref="shardingpoint" method="shardingDB"/> <aop:after pointcut-ref="shardingpoint" method="cleanshardingDB"/> </aop:aspect> </aop:config> <bean id="sharding" class="com.sharpframework.shardingcore.ShardingDBAspect"></bean> <!-- 因为会有多个数据库连接,所有会有一个抽象连接 配置可以从外部文件读取--> <bean id="db" class="com.alibaba.druid.pool.DruidDataSource" destroy-method="close" abstract="true"> <!-- 初始化连接大小 --> <property name="initialSize" value="${initialSize}"></property> <!-- 连接池最大数量 --> <property name="maxActive" value="${maxActive}"></property> <!-- 连接池最大空闲 --> <property name="maxIdle" value="${maxIdle}"></property> <!-- 连接池最小空闲 --> <property name="minIdle" value="${minIdle}"></property> <!-- 获取连接最大等待时间 --> <property name="maxWait" value="${maxWait}"></property> <property name="minEvictableIdleTimeMillis" value="60000"></property> <property name="testWhileIdle" value="true"></property> <property name="timeBetweenEvictionRunsMillis" value="45000"></property> <property name="validationQuery" value="select 'x'"></property> <property name="testOnBorrow" value="false"></property> <property name="defaultAutoCommit" value="false"></property> </bean> <!-- 数据库连接 --> <bean id="db-0" parent="db"> <property name="driverClassName" value="${user.db0.driver}"/> <property name="url" value="${user.db0.url}"/> <property name="username" value="${user.db0.username}"/> <property name="password" value="${user.db0.password}"/> </bean> <!-- 数据库连接 --> <bean id="db-1" parent="db"> <property name="driverClassName" value="${user.db1.driver}"/> <property name="url" value="${user.db1.url}"/> <property name="username" value="${user.db1.username}"/> <property name="password" value="${user.db1.password}"/> </bean> <!-- 数据库连接 --> <bean id="db-2" parent="db"> <property name="driverClassName" value="${user.db2.driver}"/> <property name="url" value="${user.db2.url}"/> <property name="username" value="${user.db2.username}"/> <property name="password" value="${user.db2.password}"/> </bean> <!-- 多数据源,注入到sqlSesionFactory,注意targetDataSources中key的名称,这里和@Sharding中dataSource 有关联 --> <bean id="multipleDataSource" class="com.sharpframework.shardingcore.multippledb.MultipleDataSource" primary="true"> <property name="defaultTargetDataSource" ref="db-0"/> <property name="targetDataSources"> <map> <entry key="db-0" value-ref="db-0"/> <entry key="db-1" value-ref="db-1"/> <entry key="db-2" value-ref="db-2"/> </map> </property> </bean>
下面是测试代码。
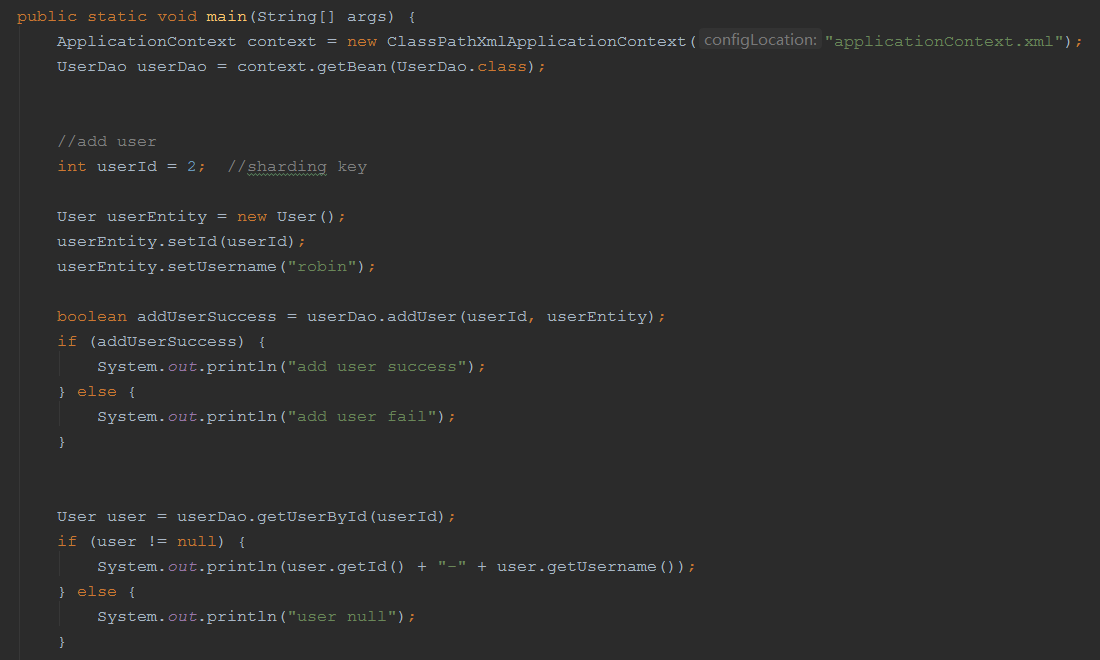
操作结果:

目前该项目已经开源,代码地址:https://github.com/zhaoyb/sharp-sharding
这个分库项目的原理就是抽象数据连接,当要操作数据库的时候根据指定的shardingkey计算出具体的数据连接,所以也就有了一定的限制,那就是在操作数据前,一定要知道具体要操作哪个库,其实对于分库分库的项目,大部分在执行sql语句前,就已经知道要操作哪张表,否则你就只能并行查所有的表。