1.文件读写
f.read() f.write() f.readlines()读取所有行(包括行结束符)作为字符串列表返回 f.writelines()接受一个字符串列表作为参数
在磁盘上读写文件的功能都是由操作系统提供的,现代操作系统不允许普通的程序直接操作磁盘,所以,读写文件就是请求操作系统打开一个文件对象(通常称为文件描述符),然后,通过操作系统提供的接口从这个文件对象中读取数据(读文件),或者把数据写入这个文件对象(写文件)。
1 #!/usr/bin/python3 2 3 f = open('F:/a.txt', 'r') 4 print( f.readline() ) #读取一行内容 5 print ( f.read() ) #读取全部内容 6 f.close() #文件对象会占用OS资源,使用完毕须关闭
文件读写可能产生IOError,为保证无论是否出错都能正确地关闭文件:
1 #!/usr/bin/python3 2 3 with open('F:/a.txt', 'r') as f: 4 print(f.read())
无论在这一段代码的开始,中间,还是结束时发生异常,都会执行清理的代码,文件仍会被自动关闭
以上是读取文本文件,并且是UTF-8编码的文本文件。要读取二进制文件,比如图片、视频等等,用'rb'模式打开文件,‘a’追加
要读取非UTF-8编码的文本文件,需要给open()函数传入encoding参数,例如,读取GBK编码的文件。
1 f = open('F:/gbk.txt', 'r', encoding='gbk')
2.StringIO
在内存中读写str
很多时候,数据读写不一定是文件,也可以在内存中读写。要把str写入StringIO,我们需要先创建一个StringIO,然后,像文件一样写入即可:
1 #!/usr/bin/python3 2 3 from io import StringIO 4 5 f = StringIO() 6 f.write('hello ') 7 f.write('chb') 8 print(f.getvalue())

3.BytesIO
StringIO操作的只能是str,如果要操作二进制数据,就需要使用BytesIO。BytesIO实现了在内存中读写bytes
1 #!/usr/bin/python3 2 3 from io import BytesIO 4 5 f = BytesIO() 6 f.write('中文'.encode('utf-8')) 7 print(f.getvalue())
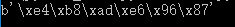
写入的不是str,而是经过UTF-8编码的bytes
4.操作文件和目录
操作文件和目录的函数一部分放在os模块中,一部分放在os.path模块中


1 import os 2 3 fileObject.seek(offset,whence) '''移动文件读取指针到指定位置 offset需要移动偏移的字节数 whence可选 4 默认值为0,0表示从文件开头开始算起,1表示从当前位置算起,2代表从文件末尾算起''' 5 file.tell() #返回当前在文件中的位置 6 7 os.chdir(tmpdir) #改变当前工作目录 8 os.getcwd() #返回当前工作目录 9 os.access(path,mode) #检验权限模式 10 '''mode: os.F_OK 测试path是否存在 11 os.R_OK 测试path是否可读 12 os.W_OK 测试path是否可写 13 os.X_OK 测试path是否可执行 14 ''' 15 os.chmod(path,mode) #用于更改文件或目录的权限 16 os.utime() #设置指定路径文件最后的修改和访问时间 17 18 os.path.abspath('.') #查看当前目录的绝对路径 19 os.path.join('F:/', 'python_code') #合并路径 20 os.path.splist('F:/a/b/c.txt') #路径拆分 21 os.path.splitext('') #得到文件扩展名 22 os.mkdir('F:/a/b') #创建一个目录 23 os.rmdir('F:/a/b') #删除一个目录 24 os.rename('a.txt', 'a.py') #对文件重命名 25 os.remove('a.py') #删除文件 26 27 os.listdir() #用于返回指定的文件夹包含的文件或文件夹名称 28 os.path.exists() #可以直接判断文件是否存在 29 os.path.isdir(path) #判断某路径是否为目录 30 os.path.isfile(path) #判断某路径是否为文件 31 32 #列出当前目录下的所有目录 33 [x for x in os.listdir('.') if os.path.isdir(x)] 34 35 #列出所有的.py文件 36 [x for x in os.listdir('.') if os.path.isfile(x) and os.path.splitext(x)[1]=='.py']
5.序列化
把变量从内存中变成可存储或可传输的过程,称之为序列化(永久性存储)
Python特定的序列化模块是 pickle
1 #!/usr/bin/python3 2 3 import pickle 4 5 d = dict(name = 'Chb', age = '21', score = 88) 6 f = open('F:/d.txt', 'wb') 7 pickle.dump(d, f) 8 f.close
把对象从磁盘读到内存时为反序列化
1 #!/usr/bin/python3 2 3 import pickle 4 5 f = open('F:/d.txt', 'rb') 6 print( pickle.load(f) ) 7 f.close
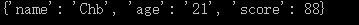
6.JSON
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
Python对象--------------->JSON格式
1 #!/usr/bin/python3 2 3 import json 4 5 d = dict(name = 'Chb', age = 21, score = 88) 6 print( json.dumps(d) ) #返回一个str 内容为标准的JSON

JSON格式-------------->Python对象
1 #!/usr/bin/python3 2 3 import json 4 5 json_str = '{"name": "Chb", "age": 21, "score": 88}' 6 print(json.loads(json_str))

Python3中关于编码与解码
Unicode为统一码(万国码),中文是gb2312
Python3中字符串类型str是以Unicode编码的,所以在Python3中看到多种语言文字的字符串而不会出现乱码
编码(encode)是用一种特定的方式对抽象字符(Unicode)转换为二进制形式(bytes),对bytes类型进行编码会报错
解码(decode)则相反(bytes--->Unicode),对str类型字符进行解码会报错
Python对于bytes类型的数据用带'b'前缀的单(双)引号表示
Python3中字符以Unicode的形式存储指的是在计算机内存当中,如要存储在硬盘里,必须以bytes形式存储
写入模式与写入内容的数据类型要匹配:如要以'w'模式写入,则要求写入的内容必须是str类型,如果以'wb'形式写入,则要求写入的内容必须是bytes类型
网页编码和文件编码差不多,如urlopen下载下来的网页如果已经read()的同时decoding('utf-8')解码过,那么写入时就必须以'w'的方式写入文件;如果只是read()而没有encoding('utf-8')进行解码过,那么写入时就必须以'wb'的方式写入文件
文本和字节序列
人类使用文本,计算机使用字节序列
一个字符串是一个字符序列
处理文本文件的最佳实际是“Unicode三明治”
bytes------>str 解码输入的字节序列
100%str 只处理文本
str--------->bytes 编码输出的文本
意思是:要尽早把输入(例如读取文件时)的字节序列解码成字符串,“肉片”(中间一层)是程序的业务逻辑,在这里只能处理字符串对象。在其他处理过程中,一定不能编码或解码。对输出来说,则要尽量晚地把字符串编码成字节序列