数据源:提取码: g6vv
写这篇文章的目的是通过实践加深数据分析流程的印象,方便以后忘记时快速回顾,文末附有自己写的数据分析报告。
数据来源CDNow网站的用户购买明细。一共有用户ID,购买日期,购买数量,购买金额四个字段
消费行业或者是电商行业一般是通过订单数,订单额,购买日期,用户ID这四个字段来分析的,基本上这四个字段就可以进行很丰富的分析。
分析步骤:先清洗好数据,然后从消费趋势、用户方向、订单方向分析数据所反映的问题
任务:缺失值的处理、数据类型的转化
任务:每月的消费总金额、每月的订单数、每月的销量、每月的消费人数
任务:用户消费金额和购买数量的描述统计、用户消费金额和购买数量的散点图、用户消费金额的分布图(二八法则)、用户购买数量的分布图、用户累计消费金额的占比
任务:用户第一次消费时间、用户最后一次消费时间、用户分层、用户购买周期
1.启动jupyter notebook,新建puython3文件
2.导入库并加载数据
1 import pandas as pd 2 import numpy as np 3 import matplotlib.pyplot as plt 4 from datetime import datetime 5 %matplotlib inline 6 plt.rcParams['font.family'] = ['sans-serif'] # 解决中文乱码 7 plt.rcParams['font.sans-serif'] = ['SimHei'] 8 # 设置显示图形用svg矢量格式, 9 %config InlineBackend.figure_format = 'svg' 10 11 columns = ['user_id','order_dt','order_products','order_amount'] # 为打开的文件指定列名(CDNOW_master.txt文件没有列名只有数据) 12 df = pd.read_table(r"C:/CHB/CDNOW_master.txt", names = columns, sep = 's+') # 文件CDNOW_master.txt以空格分隔,s+表示匹配任意空白符
3.用 head+info+describe 观察数据,看数据是否干净:有没有缺失值、数据类型是否正确(数据类型正确与否很重要,拿到数据需要首先看数据类型,以避免接下来出现数据类型问题,pandas数据类型转换)

没有缺失值,但有些数据类型不符合我们的分析要求:如order_dt应该是datetime64类型才对

用户平均购买2个商品,中位数在2个商品,75分位数在3个商品,说明绝大部分订单的购买量都不多。最大值在99个,数字比较高。
购买金额的情况差不多,大部分订单都集中在小额,说明有小部分用户会购买大量商品。
一般而言,消费类的数据分布,都是长尾形态。大部分用户都是小额,然而小部分用户贡献了收入的大头,俗称二八。
4. 把 order_dt 字段的数据类型转为datetime64,astype也可以将时间格式进行转换,比如[M]转化成月份,周是W。
1 df['order_dt'] = pd.to_datetime(df.order_dt,format = '%Y%m%d') # Y四位数的日期部分,y表示两位数的日期部分 2 df['month'] = df.order_dt.values.astype('datetime64[M]') # 衍生一个month字段用于接下来的分析(月份依旧显示日,只是变为月初的形式。)

1.先对数据按月分组,然后求出每月的销量并绘图
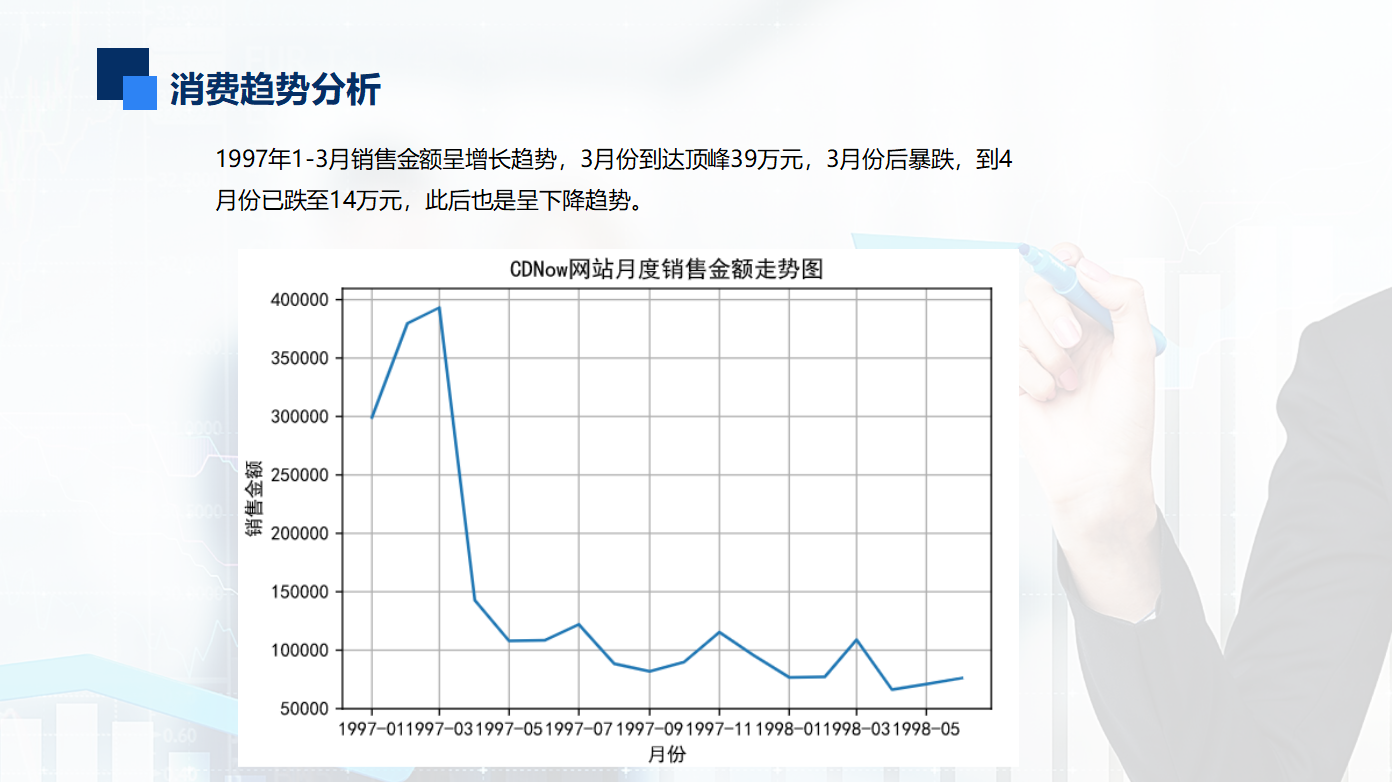
1 fig,axes = plt.subplots(1,1) 2 plt.plot(grouped_month.order_amount.sum()) 3 plt.title("CDNow网站月度销售金额走势图") 4 plt.xlabel("月份") 5 plt.ylabel("销售金额") 6 plt.grid(b = "true") 7 plt.savefig("month_amount.jpg")
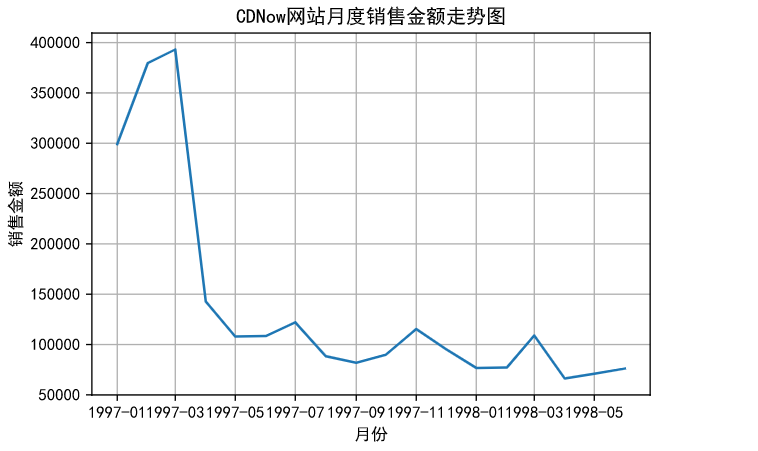
按月统计每个月的CD销量。从图中可以看到,前几个月的销量非常高涨。数据比较异常。而后期的销量则很平稳。
2.每月的消费总金额
1 fig,axes = plt.subplots(1,1) 2 plt.plot(grouped_month.order_products.sum()) 3 plt.title("CDNow网站月度销售量走势图") 4 plt.xlabel("月份") 5 plt.ylabel("销售量") 6 plt.grid(b = "true") 7 plt.savefig("month_products.jpg")

金额一样呈现早期销售额多,后期平稳下降的趋势。
3.每月的订单数
1 fig,axes = plt.subplots(1,1) 2 plt.plot(grouped_month.user_id.count()) 3 plt.title("CDNow网站月度订单量走势图") 4 plt.xlabel("月份") 5 plt.ylabel("订单量") 6 plt.grid(b = "true") 7 plt.savefig("month_count.jpg")
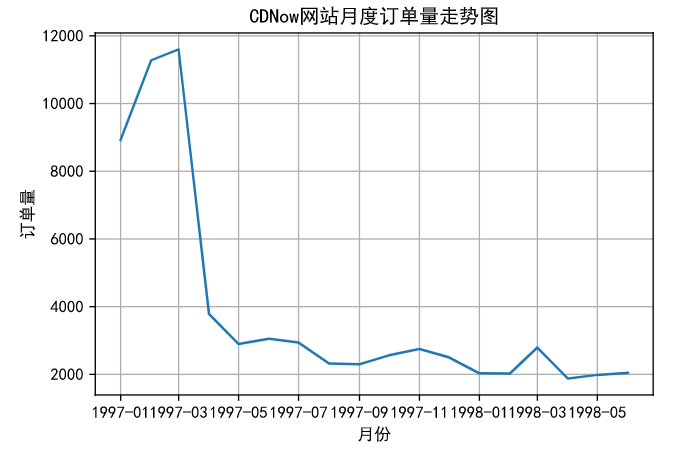
前三个月的消费订单数在10000笔左右,后续月份的消费人数则在2500人左右。
4.每月的消费人数(重复的不算)
1 fig,axes = plt.subplots(1,1) 2 plt.plot(df.groupby('month').user_id.nunique()) 3 plt.title("CDNow网站月度消费人数走势图") 4 plt.xlabel("月份") 5 plt.ylabel("消费人数量") 6 plt.grid(b = "true") 7 plt.savefig("month_people_count.jpg")

一样是前期消费人数多,后期平稳下降的趋势。
5.用数据透视表看每月数据的趋势
df.pivot_table(index = 'month', values = ['order_products','order_amount','user_id'], aggfunc = {'order_products':'sum','order_amount':'sum','user_id':'count'}).head()
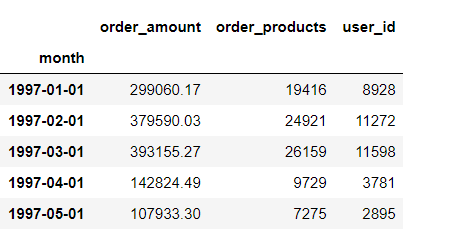
小结:每月的销量、销售金额、订单数和消费人数都是前三个月非常高,之后趋于平稳。
为什么会呈现这个原因呢?我们假设是用户身上出了问题,早期时间段的用户中有异常值,第二假设是各类促销营销,但这里只有消费数据,所以无法判断。
有时候我们也需要从个体来看这个人的消费能力如何,这里划分了五个方向如下:
1.先按用户分组,然后求用户消费金额和购买数量的描述统计
1 group_user = df.groupby('user_id') 2 group_user.sum().describe()
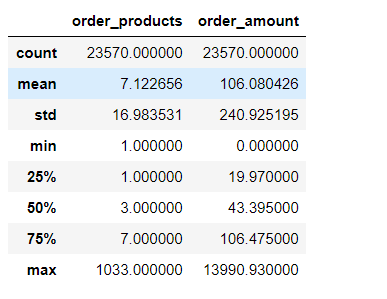
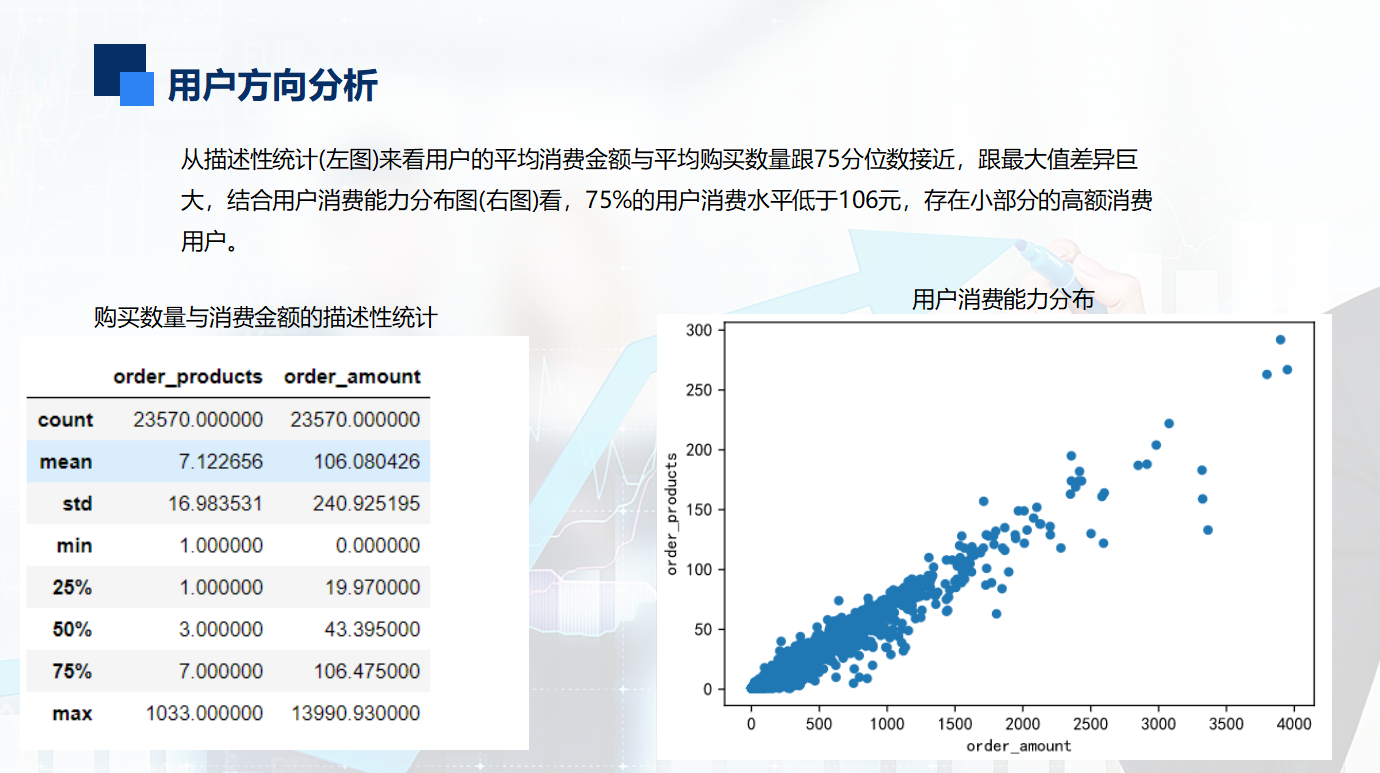
从用户角度看,每位用户平均购买7张CD,最多的用户购买了1033张。用户的平均消费金额(客单价)100元,标准差是240
结合分位数和最大值看,平均值才和75分位接近,肯定存在小部分的高额消费用户。
消费、金融和钱相关的数据,基本上都符合二八法则,小部分的用户占了消费的大头
2.用户消费金额和购买数量散点图
1 group_user.sum().query('order_amount < 4000'). plot.scatter(x = 'order_amount' , y = 'order_products') # query后面只支持string形式的值
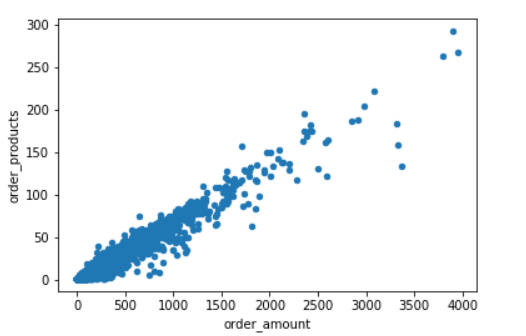
x轴是用户个人消费金额,y轴是用户个人购买数量,呈线性关系,因为这是CD网站的销售数据,商品比较单一,消费金额和购买数量挂钩。
这里把消费金额大于4000的点排除在外,因为从上面用户消费金额和消费次数的描述统计来看,大于4000已属于异常值了,而且也没多少个点,还不如排除在外,重点关注大部分用户的分布情况。
如果不设置条件,散点图如下图,显然上图好一点,上图已经够表达出分布规律了

3.用户消费金额的分布图(二八法则)
group_user.sum().order_amount. plot.hist(bins = 20) # bins = 20,就是分成20块,最高金额是14000,每个项就是700

x轴是消费金额,y轴是用户数,从上图直方图可知,大部分用户的消费能力确实不高,绝大部分用户集中在很低的消费档次(700)。高消费用户在图上几乎看不到,这也确实符合消费行为的行业规律。
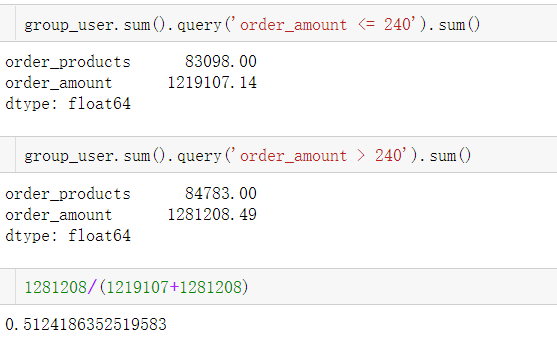
说大部分可能有点笼统,我们具体算一下有多少用户消费金额小于等于700,有多少用户消费金额大于700
group_user.sum().query('order_amount <= 700').count()

group_user.sum().query('order_amount > 700').count()

print("消费金额小于等于700的用户有: 23171位,占比: {:.2%}".format(23171/(23171+399)))
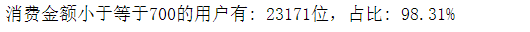
4.用户购买数量的分布图(二八法则)
group_user.sum().query('order_products < 100').order_products.hist(bins = 40) # 购买数量设置小于100,分成40块,每块就是2.5
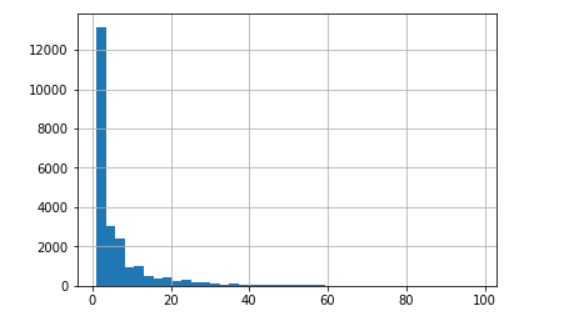
大部分用户的购买数量落在区间 [0,20]
5.用户累计消费金额的占比(百分之多少的用户占了百分之多少的消费额)
1 user_cumsum = group_user.sum().sort_values('order_amount').apply(lambda x: x.cumsum() / x.sum()) # axis = 0按列计算 cumsum滚动累加求和 sort_values排序,升序 2 user_cumsum
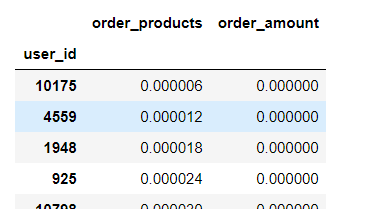
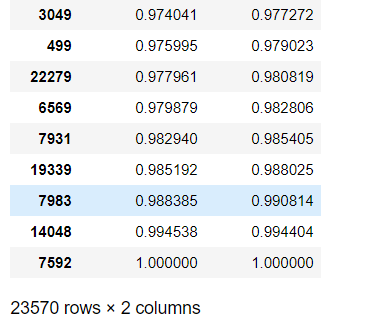
user_cumsum.reset_index().order_amount.plot().grid(b=True) # reset_index重设索引,grid(b=True)开启网格线


拿消费界限计算各自消费总额
1.用户第一次消费时间(首购)
在很多行业里面首购是一个很重要的维度,它和渠道息息相关,尤其是针对客单价比较高客户留存率比价低的行业,第一次客户从哪里来可以拓展出很多运营方式
group_user.month.min().value_counts()

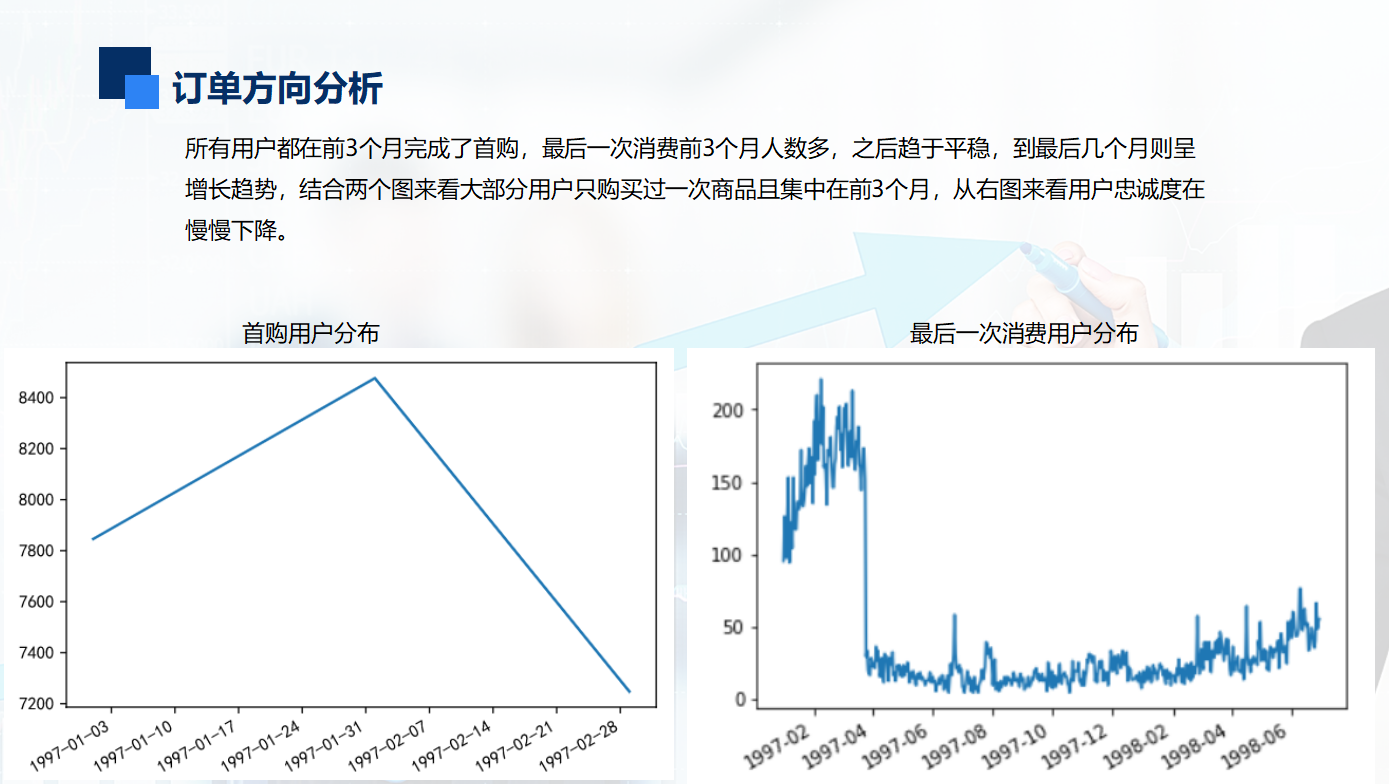
求月份的最小值,即用户消费行为中的第一次消费时间。所有用户的第一次消费都集中在前三个月。
2.用户最后一次消费时间
group_user.month.max().value_counts()
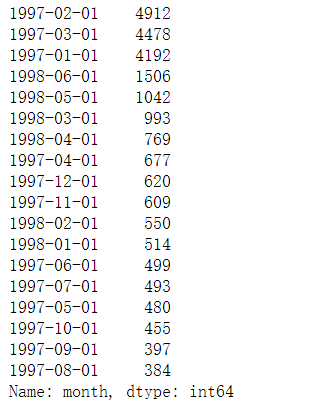
group_user.max().order_dt.value_counts().plot()
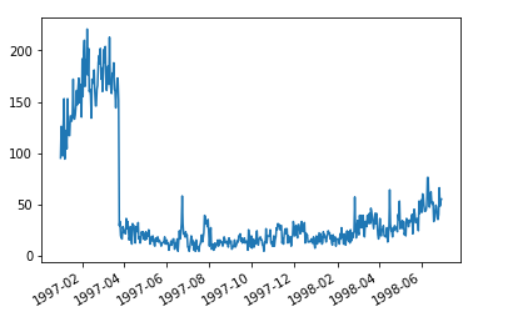
用户最后一次消费比第一次消费分布广,大部分最后一次消费集中在前三个月,说明很多客户购买一次就不再进行购买。
随着时间的增长,最后一次购买数也在递增,消费呈现流失上升的情况,用户忠诚度在慢慢下降。
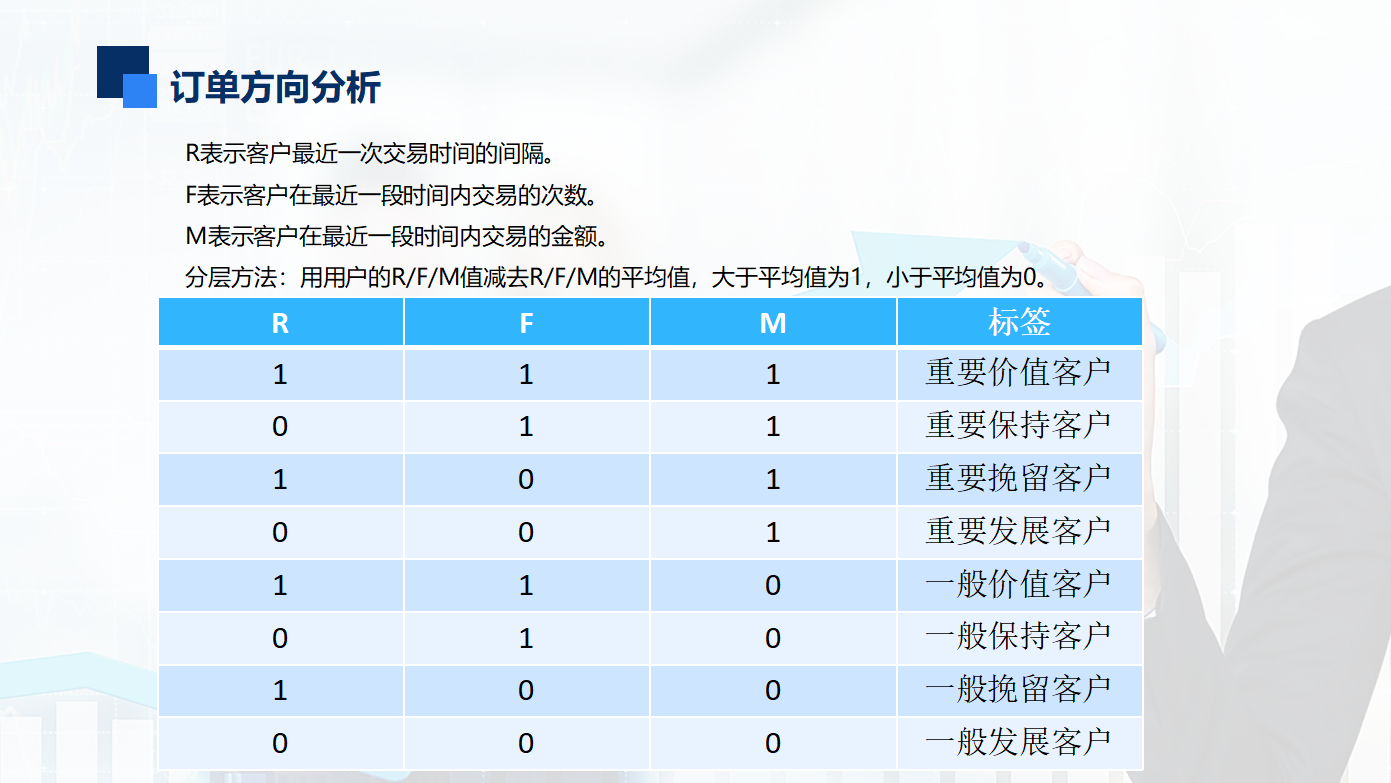
3.用户分层(RFM)
1 rfm = df.pivot_table(index = 'user_id', 2 values = ['order_products','order_amount','order_dt'], 3 aggfunc = {'order_dt':'max','order_amount':'sum','order_products':'sum'}) 4 5 rfm.head()
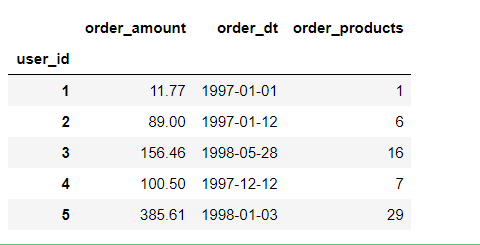
order_amount消费总金额,order_products消费产品数,order_dt最近一次消费时间
order_products求的是消费产品数,把它替换成消费次数也是可以,但是因为我们这里消费次数是比较固定的,所以使用消费产品数的维度。
1 rfm['R'] =-(rfm.order_dt - rfm.order_dt.max()) / np.timedelta64(1,'D') 2 #-(rfm.order_dt - rfm.order_dt.max())结果为时间类型,将时间格式转化为整数或者浮点数的形式,可以除以单位‘D’,也可以用astype转化 3 rfm.rename(columns ={'order_products':'F', 'order_amount':'M'},inplace = True ) 4 rfm = rfm[['R','F', 'M']] 5 rfm.head()

获得三个字段的值后定义分层函数进行用户分层
1 def rfm_func(x): 2 level = x.apply(lambda x :'1' if x >= 0 else '0') 3 label = level.R + level.F + level.M 4 d = { 5 '111':'重要价值客户', 6 '011':'重要保持客户', 7 '101':'重要挽留客户', 8 '001':'重要发展客户', 9 '110':'一般价值客户', 10 '010':'一般保持客户', 11 '100':'一般挽留客户', 12 '000':'一般发展客户' 13 } 14 result = d[label] 15 return result 16 17 rfm['label'] = rfm[['R','F','M']].apply(lambda x : x - x.mean()).apply(rfm_func,axis = 1) # axis = 1列,即把rfm_func结果放到列 18 rfm.head()
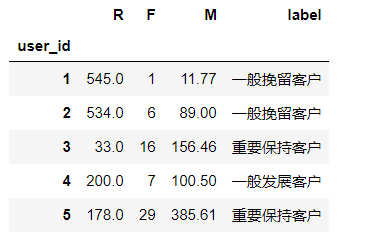
统计一下每个层次的用户有多少
rfm.groupby('label').count()
画饼图看一下占比
1 x = rfm.groupby('label').count().R 2 plt.pie(x.values, labels=x.index, autopct='%.0f%%')
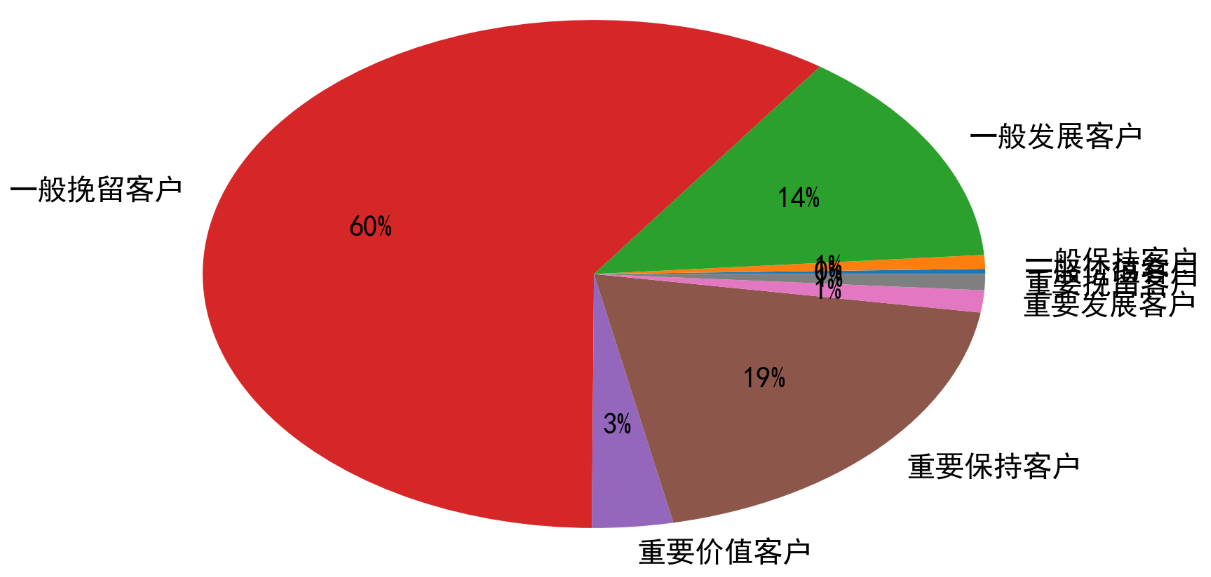
可以看到,一般挽留和一般发展的用户占了大部分,重要保持客户排名第二
rfm.groupby('label').sum().M
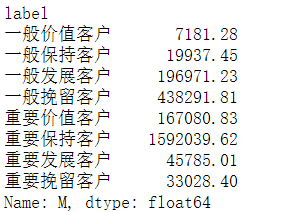
画饼图看一下占比
1 y = rfm.groupby('label').sum().M 2 plt.pie(y.values, labels=y.index, autopct='%.0f%%')

结合上一个图看,一般挽留客户人数占60%,但销售额只占18%,重要保持客户占19%,销售额占64%,消费的大头主要是重要保持客户
4.用户购买周期
1 order_diff = group_user.apply(lambda x : x.order_dt - x.order_dt.shift()) # 将用户分组后,每个用户的订单购买时间进行错位相减 2 order_diff.describe()

用户的平均购买周期是68天,绝大部分用户的购买周期都低于100天
用户购买周期分布
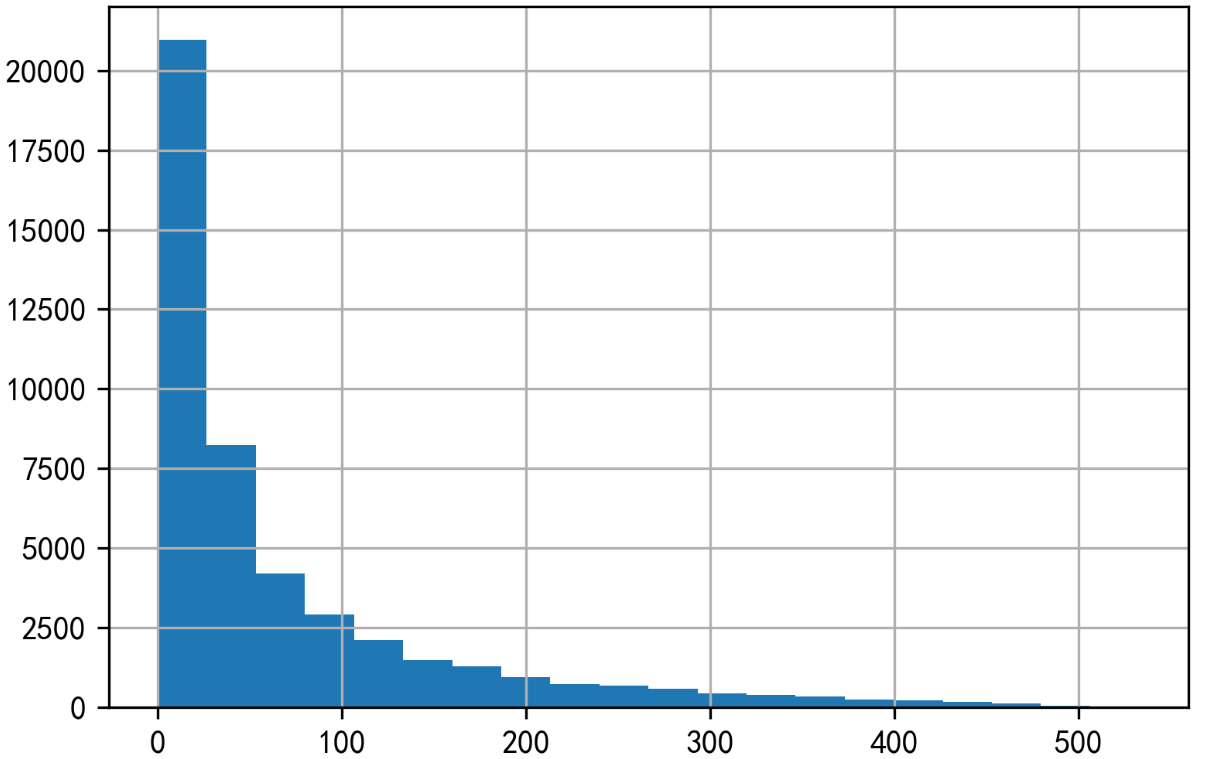
小结:用户首购集中在前三个月并且最后一次购物也集中在前三个月,很多用户都是在前三个月购买一次后就不买了,这些用户大多属于一般发展和一般挽留客户,只贡献了1/4的销售额,剩下的用户购买量大,贡献了销售额的大头。