又得开始写博客了,目测又要一周一篇了,当然了这不算python跟前端的,个人喜欢notepad++可惜不能放图片,word什么的太讨厌了
为什么要单机优化呢,很简单,因为不论以后是各类集群也好,物理机虚拟机也好,只有将个人优势发挥到最大才能提升整体的最低限度,因为木桶原理嘛;再一个,穷啊,玩linux那就是得优化,极尽的压榨操作系统的性能。集群什么的都是从单机演化出来的,so,优化好单机是你继续下一步的初始条件
我们从一个请求连接的总流程来看一下我们可优化的点(运维角度)
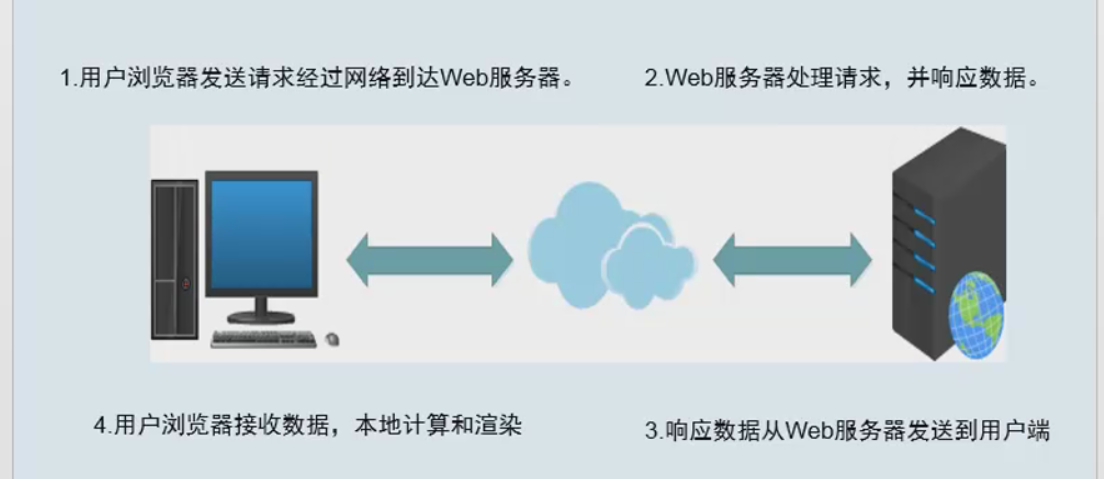
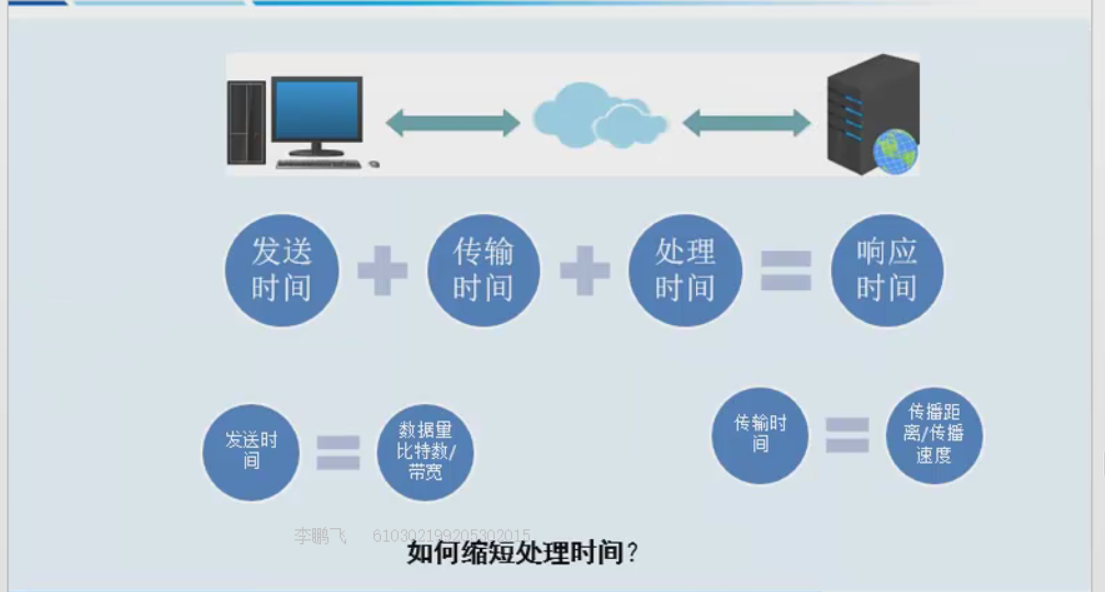
其实这中间的每一个步骤速度提升都对我们的性能有提升(此时的性能是指用户的客观感受,就是开你网页快不快),每次网站变卡了,领导就说去赶快加点带宽去,这句话也是对的,带宽大了,数据发送的时间就会变少,加带宽肯定是对性能提升有好处的,so现在知道了你们老大其实也是很专业的了吧~~~
好了,不卖萌了,作为专业的运维,我们肯定是希望花合适的时间金钱在最合适的提升位置,这也就是所谓的 “瓶颈点”,因此做优化,找出“瓶颈点”最为关键!但是非常可惜我们只能从自己的服务器这面进行优化的进行,因为找出“瓶颈点”这就是一个很现实的事情了,纸上谈兵,毫无意义。
因此,进入今天的主题吧,单机web性能优化!
完全单机的web其实是不容易针对优化的,因为所有的服务都需要安放在一台机器上,常见的就是我们喜欢的lnmp,一台电脑上要装nginx、php、mysql,可能还有一些其他的什么鬼,so,我萌只能进行一些通用的优化了。
一.从系统本身限制考虑
先从我们的服务器本身考虑,我们需要使用ulimit 这个熟悉的命令将每个进程可以打开的文件数目加大到65535(默认值1024)并更改系统可打开的总文件数目,为什么要改这玩意?because on Linux everything is file,so,we must do it!还是不理解,好吧,每当创建一个连接后,这让条连接都会打开若干文件,哪怕至少我们也要打开一个小socket,这样就会占用一个文件,如果连接过多,而单个任务上有限制只允许一共打开1024个文件,那么后面的连接就进不来了。同理,如果所有任务打开的文件数超过了系统本身允许的上限也不行,所以file-max也是尤为重要的,两者缺一不可!
1 [root@master ~]# ulimit -n 2 1024 3 [root@master ~]# ulimit -n 65535 4 [root@master ~]# ulimit -n 5 65535 6 [root@master ~]# cat /proc/sys/fs/file-max 7 181795 8 [root@master ~]# echo "fs.file-max = 6553560" >>/etc/sysctl.conf
二. 提供的服务类型考虑
我们对外提供web服务,那么我走的肯定是http/https连接了,对内我自己的业务需要连接自己的数据库,,so,总的来说我走的就是tcp连接,既然如此我们先回顾下经典的三握四挥吧
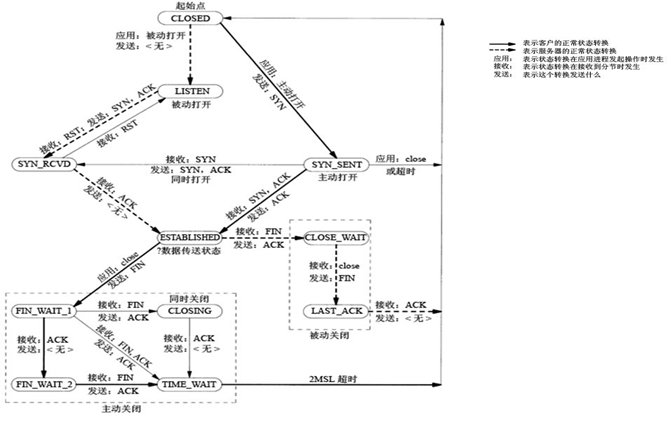
流程及三次握手相关的就不说了就那么几下,直接总结挥手重要的
time_wait出现在客户端主动断开连接后
close_wait出现在服务端主动断开连接后
其实time_wait是不太好,而且他在断开后还是会留有一个2分钟的文件,这样就占用了上面的可打开文件数资源!so,我们从这一点进行相关优化,首先,我们要思考下为什么连接断开了,默认还是会保留状态呢,写tcp协议这哥们是不是傻,是不是傻,你觉得他是不是傻?其实不是,人家只是基于当时的环境考虑了一些问题:
- 防止上一次连接的包在网络传输中迷路了,要把它收回来
- TCP不是UDP,要保证可靠性!在主动关闭方发送的最后一个 ack(fin) ,有可能丢失,这时被动方会重新发fin, 如果这时主动方处于 CLOSED 状态 ,就会响应 rst 而不是 ack。所以主动方要处于 TIME_WAIT 状态,而不能是 CLOSED!
- 另外这么设计TIME_WAIT 会定时的回收资源,并不会占用很大资源的,除非短时间内接受大量请求或者受到攻击
当然,这是基于当年的网络环境下的考虑,1981年的网络状况大约4分钟你传输一个byte!so不解释了(我怎么知道的?因为我会穿越时空啊,我刚才还去买了几瓶82年的雪碧呢~),但是这不是我们就不优化的理由呀,so,我们有三个内核参数来解决这个问题。
- tcp_tw_reuse复用,毕竟每次创建TCP连接是需要消耗资源的,如果TIME-WAIT sockets能复用那真的很不错,我们可以在任何地方开启它
- tcp_tw_recycle快速销魂,它在内网环境下会很给力,可以让你快速回收TIME_WAIT sockets,但是它有一个问题就是不可以在NAT负载均衡器上打开
- tcp_timestamps是上面两个选项的基础条件,不过默认情况下是已经打开的,它就是在打一个时间戳,我们需要一个标识来确定sockets是否该被回收或是复用
1 [root@master ~]# cat /proc/sys/net/ipv4/tcp_tw_reuse 2 0 3 [root@master ~]# cat /proc/sys/net/ipv4/tcp_timestamps 4 1 5 [root@master ~]# cat /proc/sys/net/ipv4/tcp_tw_recycle 6 0 7 [root@master ~]# echo 1 > /proc/sys/net/ipv4/tcp_tw_reuse 8 [root@master ~]# echo 1 > /proc/sys/net/ipv4/tcp_tw_recycle
再从最简单的方面考虑下,我们不就是觉得TIME_WAIT 的时间太长了么,那么我们把它直接改小不就可以了么,改太小也不好,会引起其他问题
1 [root@master ~]# echo 15 > /proc/sys/net/ipv4/tcp_fin_timeout
文件限制方面的优化现在貌似这样就很不错哦,现在我们不考虑这面单纯的就是想提高该web的并发量,怎么破,我们都知道建立连接后是两台机器端口间的互相伤害,so,如果我们可以多开一些端口,有人会问,多开端口那是客户端的问题,你服务端开个80别人连你不都走这个么,这就是架构的魅力所在,在你是服务器的同时,你又是客户端,你提供web就单纯是个html么,不需要交互数据库嘛,不需要拿静态资源嘛,静态资源可能也有个服务器,so,任重而道远啊,多有一些可打开的端口是一件美好的事情了吧
1 [root@master ~]# cat /proc/sys/net/ipv4/ip_local_port_range 2 32768 60999 3 [root@master ~]# echo "10000 65530" > /proc/sys/net/ipv4/ip_local_port_range
三.组件分离
当服务完全都在一台机器上时,我们肯定会随着业务量的增多进行分离,一般会先将数据库分离,然后再将静态资源分离。
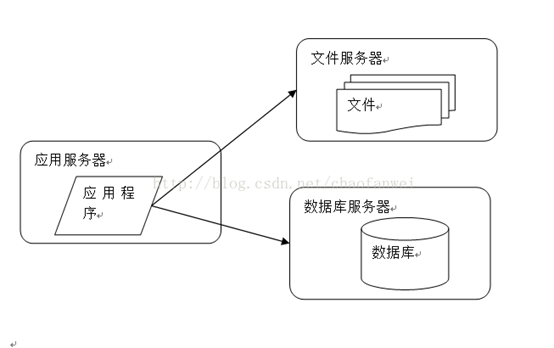
一下子整齐了许多,我们有了3台服务器,在购买服务器的时候我们就可以针对业务挑选性价比更高的服务器,我们的应用服务器不需要存储什么东西,so磁盘什么的就可以从简,数据库那必须ssd了,现在已经很便宜了,对io的提升是极其明显的,而文件服务器,用ssd也好,但是cpu跟内存就不需要太关注了。
当我们的机器分离出来后,已经给我们的并发量带来了提升,每个服务都是要占文件描述符的,现在分离出来,各自占本机的,没人跟你抢,还有可使用的端口。
我们先优化数据库跟文件服务器,他们都需要对磁盘进行大量的io操作,所以我们要对磁盘调度方式进行调整,linuxIO调度大家都知道的,基本知识
Cfq:完全公平,默认选项
Noop:什么都不做,ssd就用这个
Deadline:有一个最后期限,数据库常用
So,很明显我们的文件服务器在使用了ssd盘后就可以将其的盘符的调度改成Noop了,而web服务器可能就是记录下日志,所以使用默认的Cfq就好。而数据库服务器使用Deadline,那么请问使用了ssd的数据库改用Deadline还是Noop?答案其实都是可以的,其实这两者之间性能差别不大,但是由于数据库的性质,设置一个最后期限还是更加合理。
最后我们优化我们的web服务器,以nginx为例,
高级配置:
worker_processes auto;
Events配置:
use epoll;
worker_connections 65535
HTTP配置:
sendfile on;
tcp_nopush on;
tcp_nodelay on;
前几个就不说了,tcp_nopush与tcp_nodelay的意义是相对的,但是在开启sendfile的情况下并不冲突,简单的说最终的效果就是会将发送的数据一直积累到最大报文长度后再发送,如果是最后的包那么会直接发送不等待。这里面牵扯tcp协议里的东西
Nagle算法是指满足最大报文长度情况下,立刻发送,否则放在缓冲区,减少网络中包的数量提升性能
DelayedAcknowledgment不再针对单个包发送ACK,而是一次确认两个包,或者在发送响应数据的同时捎带着发送ACK,又或者触发超时时间后再发送ACK,通过减少网络中的ack数量提升网络环境
但是长连接出现奇数包+结束小包时,就会对前两个包很快的进行正常处理,但是第三个包的ack并未返回而是被先缓存起来了,而发送端需要确认此包的ack才能发结束小包结束全部连接,so,需要延迟40ms过期时间才会发送,然后结束连接,从而降低了性能。
在短连接中不会出现这种情况,因为连接是读---写---读---写,立刻结束的,因为立刻结束了连接,so最后的包是立刻发出的