IPython使用
IPython是增强的CPython,尤其是交互式体验。该项目提供了Jupyter Notebook,之后分离。
提供帮助功能:
?:IPython概叙和简介
help(name):查询指定名称的帮助。
obj?:列出对象的详细帮助。
obj??:如果可以,则列出更详细的帮助。
特殊变量
IPython内部提供了非常多的变量,或许能用到的如下:
_:表示前一次输出
__:表示倒数第二次输出
___:表示倒数第三次输出
_dh:目录历史
_oh:输出历史
shell命令
使用'!'+shell命令可执行当前系统shell的命令。
魔术方法
‘%’:如%cd,改变当前工作目录,%pwd,显示当前目录,%ls,显示当前目录文件,%timeit,显示当前语句运行时间。
'%%':如%%timeit,显示当前cell运行时间。%%js,当前cell运行js脚本。
集合set
集合,简称集,由任意个元素构成的集体。
Python中,它是可变的,无序的,不重复的元素的集合。
初始化
1 s1 = set() 2 s2 = set(range(5)) 3 s3 = set([1, 2, 3, 4, 5]) 4 s4 = set('abcabc') 5 s5 = {1, 2, 3}
元素性质
去重:元素都是唯一值。
无序:无序,不可索引。
可哈希:元素必须可哈希。
可迭代:元素可被迭代。
增
1 s1 = set() 2 s1.add(1) # 把一个元素加入集合 3 print(s1) # {1} 4 s1.update((2, 3), [4, 5]) # 把1组或多组可迭代对象加入集合 5 print(s1) # {1, 2, 3, 4, 5}
删
1 s1 = set(range(5)) 2 s1.remove(1) # 删除指定元素 3 print(s1) # {0, 2, 3, 4} 4 s1.pop() # 删除随机元素 5 print(s1) 6 s1.clear() # 清空集合 7 print(s1) # set()
改
集合没有修改,只能利用删除和增加达到效果。
查

可以看出在集合查找元素会比列表快。set,dict利用哈希作为key,时间复杂度是O(1)。
索引
非线性结构,无序,不可被索引。
遍历
只要是容器皆可遍历,效率都是O(n)。
集合概念
全集:所有元素的集合。
子集与超集:一个集合A的元素都在另一个集合B里,A是B的子集,B是A的超集。
真子集与真超集:一个集合A的元素都在另一个集合B里,且A≠B,,A是B的真子集,B是A的真超集。
并集:运算符号'|',多个集合合并的结果。
交集:运算符号'&',两个集合A与B,同时属于A和B集合的元素集合为交集。
差集:运算符号'-',两个集合A与B,属于A集合的元素且不属于B的元素集合为差集。
对称差集:运算符号'^',两个集合A与B,只属于A集合的元素与只属于B集合的元素的集合为对称差集,等同于:(A|B)-(A&B)和(A-B)|(B-A)。
1 s1 = set(range(5)) 2 s2 = set(range(3, 8)) 3 print(s1 | s2) # {0, 1, 2, 3, 4, 5, 6, 7} 4 print(s1 & s2) # {3, 4} 5 print(s1 - s2) # {0, 1, 2} 6 print(s1 ^ s2) # {0, 1, 2, 5, 6, 7} 7 print(s1 >= s2) # False,判断S1是否为S2的超集,'<='判断'S1是否为S2的子集。 8 s3 = set(range(3)) 9 print(s1 > s3) # True,判断S1是否为S2的真超集,'<'判断'S1是否为S2的真子集
字典dict
Python中,字典由任意个元素构成的集合,每一个元素称为item,这个item由key与value组成的二元组。
字典是可变的,无序的,key不重复的key-value键值对集合。
注:Python3.6之后字典录入记录了录入顺序,这个特性建议暂时不要使用。如果需要有序的字典,建议使用collections.OrderedDict()。
初始化
1 d1 = {} 2 d2 = dict() 3 d3 = dict(k1='v1', k2='v2') 4 d4 = dict(d3) 5 d5 = dict(d4, k3='v3') 6 d6 = dict([('k1', 'v1'), ('k2', 'v2')], k2='v3', k3='v4') 7 d7 = dict.fromkeys(range(5)) 8 d8 = dict.fromkeys(range(5), 0)
增与改
1 d = dict() 2 d['k1'] = 'v1' 3 print(d) # {'k1': 'v1'} 4 d.update(k2='v2') 5 print(d) # {'k1': 'v1', 'k2': 'v2'} 6 d.update(k1='v3') 7 print(d) # {'k1': 'v3', 'k2': 'v2'} 8 d['k2'] = 'v4' 9 print(d) # {'k1': 'v3', 'k2': 'v4'}
删
1 d = dict.fromkeys(range(5)) 2 print(d) # {0: None, 1: None, 2: None, 3: None, 4: None} 3 d.pop(1) # 删除key为1的item。 4 print(d) # {0: None, 2: None, 3: None, 4: None} 5 d.pop(1, print('a')) # a,没有找到key为1的item执行下面代码,不设定则返回keyError。 6 print(d) # {0: None, 2: None, 3: None, 4: None} 7 d.popitem() # 随机删掉一个item,没有则返回keyError。 8 print(d) # {0: None, 2: None, 3: None} 9 d.clear() # 清空字典 10 print(d) # {}
查
1 d = dict.fromkeys(range(5), 0) 2 print(d[1]) # 0,key存在返回value,不存在返回keyError。 3 print(d.get(5)) # None,key存在返回value,不存在返回缺省值,没有缺省值返回None。 4 print(d.setdefault(5), 'a') # None a,key存在返回value,不存在创建item,value为缺省值,没有缺省值为None,并返回None和缺省值。
遍历
1 d = dict.fromkeys(range(3), 0) 2 for i in d.values(): # 遍历value 3 print(i) # 0 0 0 4 for i in d.keys(): # 遍历key 5 print(i) # 0 1 2 6 for i in d: # 等同于遍历key 7 print(i) # 0 1 2 8 for k, v in d.items(): # 遍历item 9 print(k, v) # 0 0 1 0 2 0
defaultdict
1 from collections import defaultdict 2 d = defaultdict(list) 3 for k in bytes(range(0x41, 0x45)).decode(): 4 for v in range(3): 5 d[k].append(v) 6 print(d) #defaultdict(<class 'list'>, {'A': [0, 1, 2], 'B': [0, 1, 2], 'C': [0, 1, 2], 'D': [0, 1, 2]})
封装和解构
基本概念
1 a, b = 1, 2 2 print(a, b) # 1 2
Python会先把等号右边的元素封装成一个新的元组,然后解构后按顺序赋值给左边的元素。如果右边的元素不够或溢出均会返回ValueError。
剩余变量结构
1 s = list(range(5)) 2 a, *b, c = s 3 print(a, b, c) # 0 [1, 2, 3] 4
使用'*',可以把溢出的部分全部接收。
选择排序
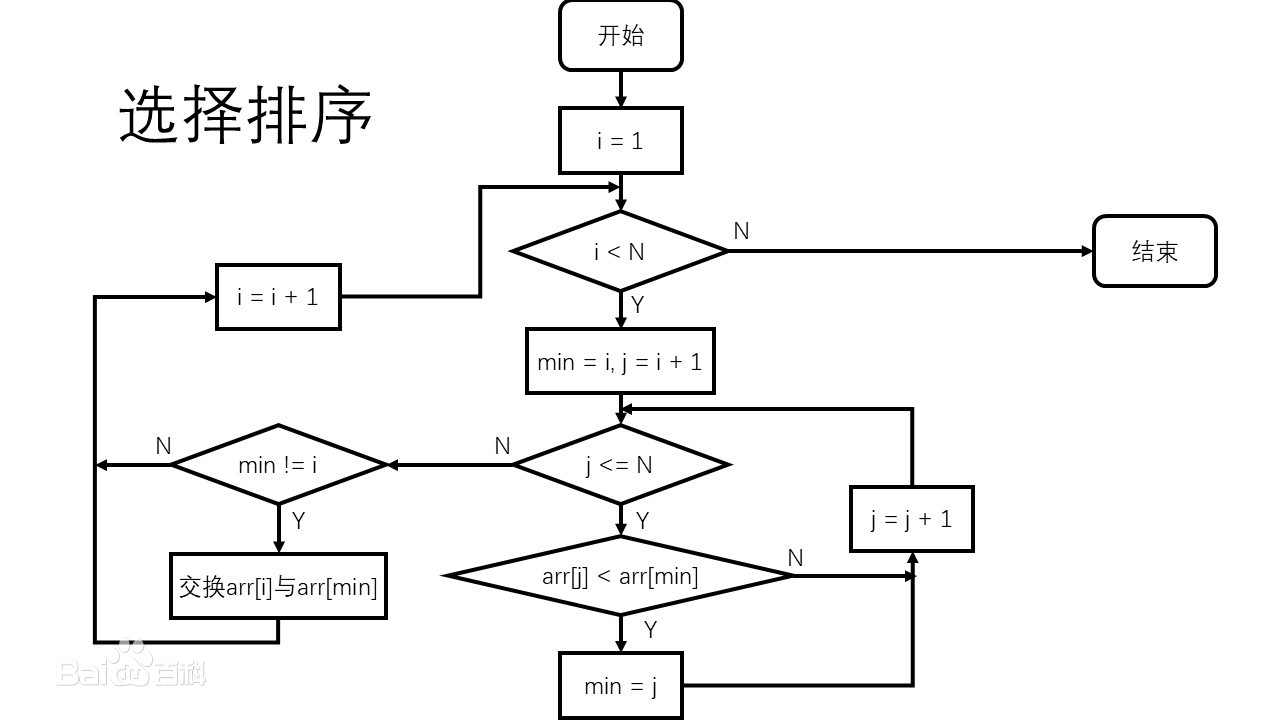
1 import random 2 arr = random.choices(range(1, 101), k=20) 3 print(arr) 4 for i in range(len(arr)//2): 5 is_min, is_max = i, i 6 last = len(arr)-i-1 7 for j in range(i+1, last+1): 8 if arr[is_max] < arr[j]: 9 is_max = j 10 if arr[is_min] > arr[j]: 11 is_min = j 12 if is_max != last: 13 if is_min == last: 14 is_min = is_max 15 arr[last], arr[is_max] = arr[is_max], arr[last] 16 if is_min != i: 17 arr[i], arr[is_min] = arr[is_min], arr[i] 18 print(arr)