文章目录
前言
在之前笔者写过一篇关于Ozone数据探查服务Recon的文章(存储系统“数据之眼”的设计–数据探查服务).Recon作为一个系统内部数据探查服务,它通过定期同步OM元数据,然后做内部的智能化分析(内部做数据聚合计算等等),可以帮助管理员方便了解系统内的数据情况。目前Recon 1.0版本已经设计实现完毕。最近Ozone社区在设计讨论Recon 2.0的事情,在2.0中,Recon涵盖的内容将会更多。这里面Recon将会进一步探查分析SCM内的Container元数据管理。下面我们来简单聊聊Recon 2.0的相关内容。
现今Ozone Recon的功能以及2.0版本的目标
现有Ozone Recon的功能主要在于OM元数据(key键值数据)的分析,包括简单的file size的range计数,然后就是Recon整体模型的基础实现。Recon的一个主要实现点在于,它通过同步原系统服务元数据的方式,然后做二次数据分析。
在1.0的设计中,很多细节的功能点其实还不够完善,比如用户会比较关心的key数据丢失的问题,类似于HDFS下的missing block问题。这里我们要知道哪些key,在哪些节点上发生数据丢失或损坏了。而这就是Recon 2.0要做的主要目标,就是做一个类似HDFS FSCk这样的命令功能。
综上所述,Recon 2.0将会实现以下两项功能点:
- 有能力知道丢失的数据key,以及此key所在Container的信息,类似FSCK命令。
- 收集,展示Datanode节点的健康信息,包括最近一次心跳,capacity,usage信息以及其上Container状态信息等等。
Recon作为外部服务,如果它能支持类似FSCK的功能,那么有一点它是必须要去做的:跟踪SCM服务的Container信息。换句话说,它需要能够跟踪OM的key元数据信息一样track住SCM的metadata信息。但是track SCM元数据的难度和track OM的元数据的难度并不相同。
这里取决于目前SCM元数据使用的以下一些特点:
- SCM拥有多个db文件,分别对应Pipeline,Container元数据信息等。
- SCM的db文件持久化信息只适用于重启开始阶段,在运行态中的Container信息,SCM根据Datanode节点的汇报,只在内存中更新。因此db文件不能代表最新的Container状态情况。
因此,我们说SCM Container数据信息的track并不容易。
SCM Container的track实现
针对如上设计,Ozone社区讨论出了以下三种方法。
方法一: 在SCM中新增实现API来获取丢失,损坏的Container数据
此方法实现最为简单,直接,只要在SCM内稍作修改,Recon服务进行调用即可。这种简单处理的方式有以下2大弊端:
- 第一点,在某些个别情况下,可能存在大量损坏Container的情况,一次get list太多Container可能会超出RPC回复内容大小。
- 第二点,此方法不利于Recon未来的扩展。当未来Recon需要获取额外例如Pipeline信息等类似时,又得需要SCM提供专门的接口实现,最后会变为SCM给Recon的一个endpoint实现。
方法二: Recon定期获取SCM的元数据进行同步
此方法类似于Recon目前定期同步OM元数据的方式,这里面的一个难点问题在于里面增量数据的更新问题。在 SCM内,Container的最新状态信息是从下面的Datanode节点汇报上来的,然后维护在SCM的内存中的。这些数据并没有实时持久化到db文件内。
因此如果要基于DB store文件做同步,那么我们需要定期持久化最新的Container状态数据或者能够获取到streaming的delta update的数据,然后Recon这边做delta的更新。
方法三: Datanode汇报数据到Recon服务
社区提到的第三种方法是允许Datanode直接汇报Container等元数据到Recon服务中。然后Recon服务根据下面汇报上来的数据在内存中构建Container等元数据信息。相比以上两种方法,此方法在改动上最大。但是在未来Recon的扩展性上来说,这种方法是比较好的做法。
在此种处理方式下,Recon将会像SCM处理Container report方式一样,处理这些report信息。
目前社区的倾向做法是方法三,就是在Recon内部能够track这些Container的数据信息,然后做进一步的missing key,Container的track分析。
另外我们可以在Recon 2.0中对一些metric指标进行友好地展示,暴露出来,和Prometheus、Grafana集成,将Recon完善为一个更加成熟的数据探查服务。
一个全新的Recon 2.0的架构模型图将会如下所示:
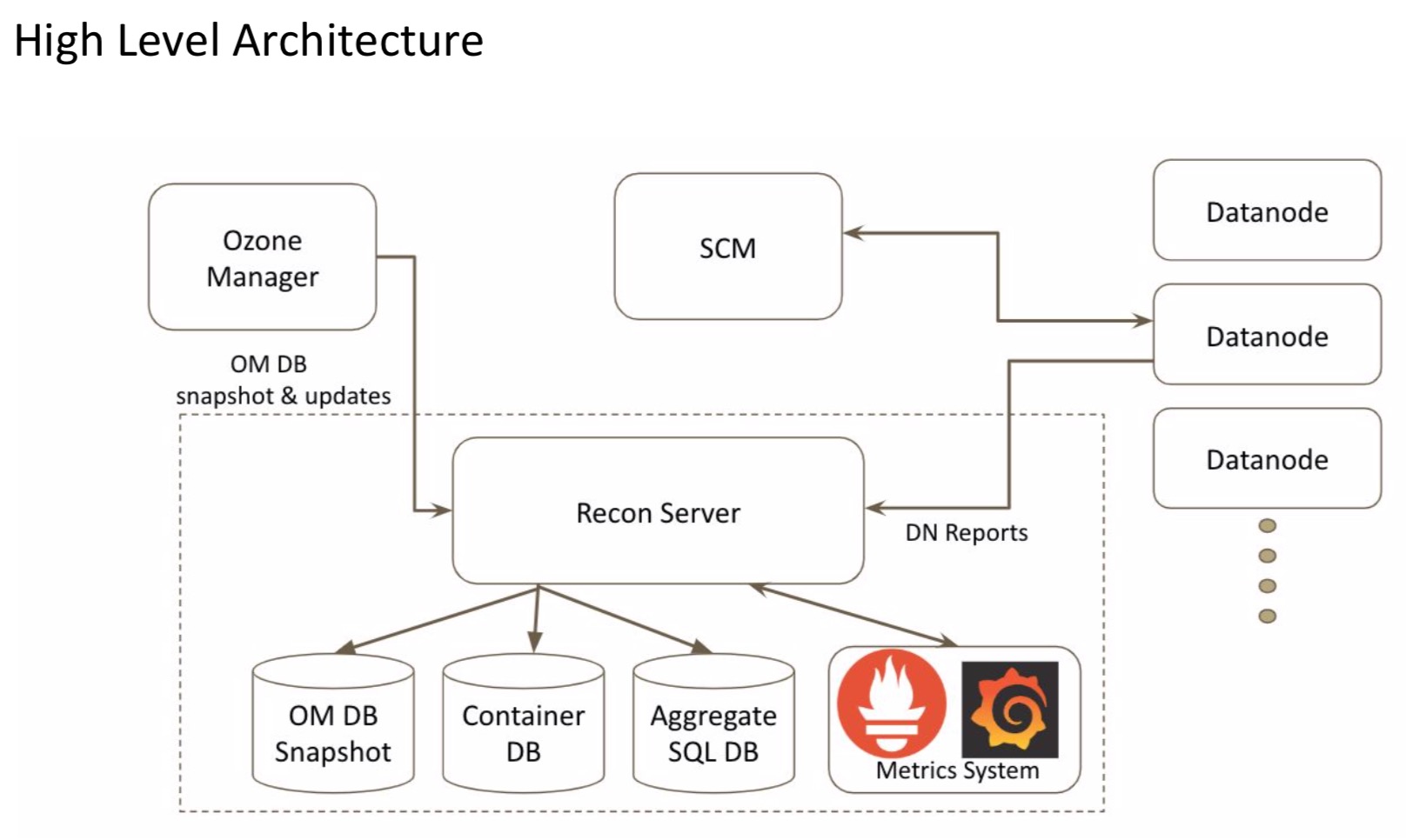
引用
[1].https://issues.apache.org/jira/browse/HDDS-1996 . Ozone Recon Service v0.2