前言
在HDFS的世界中,所有涉及元数据相关的操作都是在NameNode内完成的,真实进行文件读写和删除操作是在DataNode节点上完成的,完成好之后,再通过心跳的方式将结果汇报给NameNode。这种处理方式要比完全同步的方式好很多,尤其高吞吐数据量规模的情况下时,走同步的方式会很快遇到瓶颈的。当然了,HDFS NameNode这套机制相关文章已经写了很多了,本文笔者来介绍一个比较新的服务设计:HDFS对象存储的Ozone的块删除服务。Ozone在块删除服务的设计上要比现有的NameNode的块删除操作要复杂一些,因为它所涉及的不同服务之间的调用会更多一些。
Ozone块删除操作的相关服务
首先,我们先要知道Ozone的块删除操作,会涉及到哪些服务的操作调用,这个如果不清楚,后面就会比较难理解(这里提醒一下博友们,HDFS Ozone会要求比较多的上下文知识,如果不了解的可以阅读笔者之前写的Ozone相关的文章)。下面是相关的服务:
第一个KSM(Key Space Manager)服务,Ozone的KSM可以理解为HDFS中的NameNode,作为元数据的管理服务。在块删除服务内,它所要做的事情主要有2个:1.进行元数据的更新;2.与SCM服务通信,将要删除的块通知给SCM。
第二个SCM(Storage Container Manager)服务,SCM是一个中间人的角色,它会同时于KSM和DataNode进行通信。SCM在这里要做的事情是拿到KSM里要删除的块,并从自己维护的container信息里找到删除块对应所属的contain容器,并把这些容器对应的信息通过心跳的方式传给DataNode。
第三个DataNode,没错,DataNode也会参与其中,Ozone和HDFS是共用DataNode的,数据也是存在DataNode节点上的。DataNode做的事情是拿到SCM的删除信息,然后通过内部的后台删除服务进行删除。这个后台服务需要额外实现。
注意了,这里一个比较大的区别是,KSM不直接与DataNode通信,通过中间角色SCM进行操作的。这一点与NameNode直接与DataNode通信是不一样的。可能有人会有疑问,这种设计是为什么呢?看起是多余?笔者来回答一下这个问题,这个得从Ozone的原始设计思路说起,Ozone在设计的时候对于块的设计进行了比较灵活的设计,在DataNode之上提出了SCM容器管理的概念,然后在这个容器概念上进行相应拓展,而不是说直接在DataNode内实现一套新的块管理服务。
Ozone块删除服务流程调用
下面我们来学习了解Ozone的块删除服务的过程调用。这里并不会涉及具体源码的分析,大家只需在宏观上理解这个过程就可以了。在分析过程中,可以对照上节提到的角色分工操作。
步骤1,KSM删除块操作。此步骤是由Client端发起删除请求到KSM服务端的,这个步骤只做元数据的更新,要立即能够回复客户端。在现有的设计中,采用的办法是将block key添加一个前缀标识,使得用户无法有效查到此已从逻辑上删掉的key。因为这个过程并需要阻塞等待物理删除的结束,所以做一个简单的操作即可。此过程如下图:
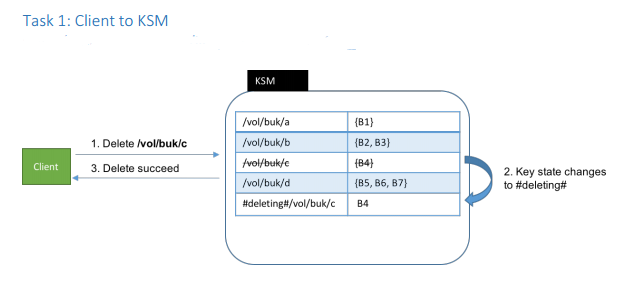
步骤2,KSM定时从外部存储文件(leveldb或rocksdb file)得到待删除的块信息,发送给SCM,SCM将这些块信息写到backlog中(同样也是db file),这里的backlog就将删除的块信息做持久化了,这样下次重启的话,这些信息还是能够保留。步骤2过程如下图
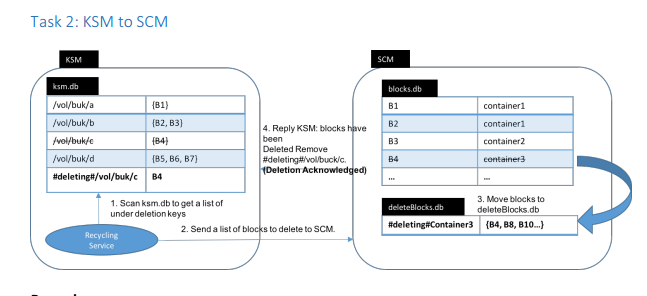
步骤3,SCM定期扫描backlog 文件,得到要删除的块信息,通过心跳发送给DataNode。DataNode收到这些块后,更新自身维护的container db文件,进行块的更新,以此标记出需要删除的chunk文件。然后收到DataNode的回复之后,更新backlog文件,删除掉相应的块记录信息。以下为步骤3的过程
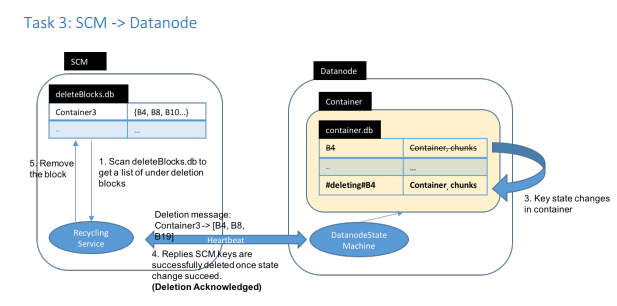
步骤4,DataNode异步删除块操作。这需要在DataNode端额外实现一个服务。此服务定期扫描需要删除的container chunk文件,并进行物理删除。此过程如下图

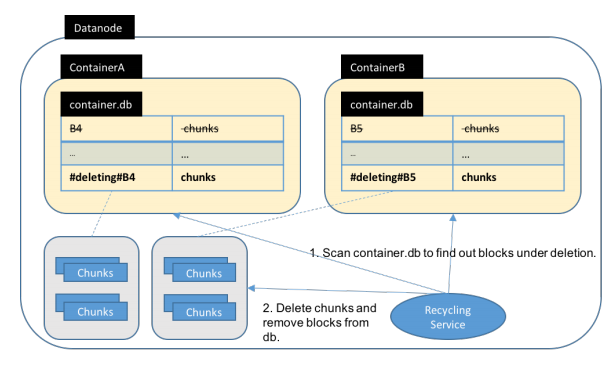
以上就是完整的调用过程。我们可以看到,中间涉及到了很多次的db更新操作和信息交互。这个不难理解,因为中间多了一个角色SCM的加入,使得整条链路变得更长一些。
参考资料
[1].Ozone: KSM: Garbage collect deleted blocks, https://issues.apache.org/jira/browse/HDFS-11922.
[2].https://issues.apache.org/jira/secure/attachment/12878767/Async%20delete%20keys.pdf