前言
在现有的HDFS中,为了保证元数据的高可用性,我们可以在配置项dfs.namenode.name.dir中配置多个元数据存储目录来达到多备份的作用。这样一来,如果其中一个目录文件损坏了,我们可以选择另外可用的文件。那么问题来了,如果所有备用的元数据都损坏了,不能用了,这个时候怎么办,那么是否就意味着集群就永远启动不起来了呢?这将会是一个多么糟糕的结果啊。在这里,我们就要引出本文的主题:HDFS的数据恢复模式(Recovery Mode)。
HDFS数据恢复模式概述
HDFS数据恢复模式的使用场景如前文中所提到的,当系统遭遇到硬件问题或软件层面的问题导致文件损坏,从而导致NameNode无法正常启动,这个时候数据恢复模式就派上用场了。更全面地来说,HDFS数据恢复模式实质上是一种元数据自我恢复的启动模式。所以它并不是DataNode上真实数据的恢复,这一点可能容易被人误解。
其次,数据恢复针对的情况是损坏状态下的editlog,而不是fsImage,fsImage是恢复后生成的。
HDFS数据恢复模式原理
当editlog文件损坏的时候,如果我们启动了NameNode,很显然NameNode会在apply editlog的时候抛出异常,从而导致NameNode启动失败。而在Recovery Mode模式下,NameNode则会智能地跳过这些错误情况,从而保证NameNode启动成功。在启动完NameNode之后,它会生出一个新的Fsimage,然后再次退出,下次集群管理员就可以正常的方式来启动集群了,因为此时用的是新的fsImage。图示过程如下:

图 1-1 HDFS数据恢复模式原理图
HDFS数据恢复模式核心代码的实现
本节我们从代码层面来学习HDFS数据恢复模式是如何实现的,主要涉及到的类有NameNode,FSNamesystem,FSImage,FSEditLogLoader。
数据恢复模式的启动入口是hdfs namenode -recover命令,相应地就对应到了NameNode的处理方法,代码如下:
public static NameNode createNameNode(String argv[], Configuration conf)
throws IOException {
LOG.info("createNameNode " + Arrays.asList(argv));
if (conf == null)
conf = new HdfsConfiguration();
// Parse out some generic args into Configuration.
GenericOptionsParser hParser = new GenericOptionsParser(conf, argv);
argv = hParser.getRemainingArgs();
// Parse the rest, NN specific args.
StartupOption startOpt = parseArguments(argv);
...
switch (startOpt) {
case FORMAT: {
...
case RECOVER: {
// reconver参数对应的启动模式
NameNode.doRecovery(startOpt, conf);
return null;
}
...然后我们进入doRecovery方法,
private static void doRecovery(StartupOption startOpt, Configuration conf)
throws IOException {
String nsId = DFSUtil.getNamenodeNameServiceId(conf);
String namenodeId = HAUtil.getNameNodeId(conf, nsId);
initializeGenericKeys(conf, nsId, namenodeId);
...
try {
// 进入FSNamesystem内的处理方法,此刻开始正式进入数据恢复过程
fsn = FSNamesystem.loadFromDisk(conf);
fsn.getFSImage().saveNamespace(fsn);
...中间会经过FSNamesystem.loadFSImage(startOpt),进入此方法,
private void loadFSImage(StartupOption startOpt) throws IOException {
final FSImage fsImage = getFSImage();
// format before starting up if requested
if (startOpt == StartupOption.FORMAT) {
fsImage.format(this, fsImage.getStorage().determineClusterId());// reuse current id
startOpt = StartupOption.REGULAR;
}
boolean success = false;
writeLock();
try {
// 构造数据恢复上下文对象
MetaRecoveryContext recovery = startOpt.createRecoveryContext();
// 进行新的镜像文件的生成过程
final boolean staleImage
= fsImage.recoverTransitionRead(startOpt, this, recovery);
...这里我们进入最终的FSImage的loadFSImage方法,
private boolean loadFSImage(FSNamesystem target, StartupOption startOpt,
MetaRecoveryContext recovery)
throws IOException {
final boolean rollingRollback
= RollingUpgradeStartupOption.ROLLBACK.matches(startOpt);
final EnumSet<NameNodeFile> nnfs;
...
Iterable<EditLogInputStream> editStreams = null;
initEditLog(startOpt);
...
Exception le = null;
FSImageFile imageFile = null;
// 遍历fsImage所存储的多个备份目录
for (int i = 0; i < imageFiles.size(); i++) {
try {
imageFile = imageFiles.get(i);
// 加载此镜像文件,加载成功一个即可
loadFSImageFile(target, recovery, imageFile, startOpt);
break;
} catch (IllegalReservedPathException ie) {
...
}
}
...
if (!rollingRollback) {
// 然后进行editlog的加载
long txnsAdvanced = loadEdits(editStreams, target, startOpt, recovery);
needToSave |= needsResaveBasedOnStaleCheckpoint(imageFile.getFile(),
txnsAdvanced);
}
...OK,到了这里,我们终于找到了editlog加载的入口了,loadEdits也将是我们所要重点关注的,因为在此过程中,实现了Recovery Mode中最为关键的跳过错误记录的逻辑。
FSEditLogLoader的loadEdits过程
我们直接进入loadEdit方法,
long loadFSEdits(EditLogInputStream edits, long expectedStartingTxId,
StartupOption startOpt, MetaRecoveryContext recovery) throws IOException {
StartupProgress prog = NameNode.getStartupProgress();
Step step = createStartupProgressStep(edits);
prog.beginStep(Phase.LOADING_EDITS, step);
fsNamesys.writeLock();
try {
long startTime = monotonicNow();
FSImage.LOG.info("Start loading edits file " + edits.getName());
// 传入期望的起始txid,恢复模式上下文
long numEdits = loadEditRecords(edits, false, expectedStartingTxId,
startOpt, recovery);
...我们继续进入此方法,
long loadEditRecords(EditLogInputStream in, boolean closeOnExit,
long expectedStartingTxId, StartupOption startOpt,
MetaRecoveryContext recovery) throws IOException {
...
try {
while (true) {
try {
FSEditLogOp op;
try {
// 从editlog输入流中读取下一个操作记录
op = in.readOp();
if (op == null) {
break;
}
} catch (Throwable e) {
// 如果出现文件损坏的情况,此处会抛出异常
//...
// 如果不是处于数据恢复的启动方式下,则会抛出异常
if (recovery == null) {
// We will only try to skip over problematic opcodes when in
// recovery mode.
throw new EditLogInputException(errorMessage, e, numEdits);
}
MetaRecoveryContext.editLogLoaderPrompt(
"We failed to read txId " + expectedTxId,
recovery, "skipping the bad section in the log");
// 如果处于Recovery Mode模式,则此处会跳过错误记录,重新定位到下一个有效的操作记录
in.resync();
continue;
}
...从上面的方法中,我们基本就知道了它是如何跳过错误的editlog记录的。读到了有效的editlog记录之后,就是把它apply到内存的操作了,
...
recentOpcodeOffsets[(int)(numEdits % recentOpcodeOffsets.length)] =
in.getPosition();
if (op.hasTransactionId()) {
// 如果当前读到的事务id大于期待的值,说明中间有被忽略的editlog记录,打出提醒信息
if (op.getTransactionId() > expectedTxId) {
MetaRecoveryContext.editLogLoaderPrompt("There appears " +
"to be a gap in the edit log. We expected txid " +
expectedTxId + ", but got txid " +
op.getTransactionId() + ".", recovery, "ignoring missing " +
" transaction IDs");
} else if (op.getTransactionId() < expectedTxId) {
MetaRecoveryContext.editLogLoaderPrompt("There appears " +
"to be an out-of-order edit in the edit log. We " +
"expected txid " + expectedTxId + ", but got txid " +
op.getTransactionId() + ".", recovery,
"skipping the out-of-order edit");
continue;
}
}
try {
if (LOG.isTraceEnabled()) {
LOG.trace("op=" + op + ", startOpt=" + startOpt
+ ", numEdits=" + numEdits + ", totalEdits=" + totalEdits);
}
// Apply此记录到NameNode内存中
long inodeId = applyEditLogOp(op, fsDir, startOpt,
in.getVersion(true), lastInodeId);
...然后以上操作都完成之后,NameNode会执行一次saveNamespace的动作,就会生成一个新的可用的fsImage了,代码如下:
private static void doRecovery(StartupOption startOpt, Configuration conf)
throws IOException {
...
NameNode.initMetrics(conf, startOpt.toNodeRole());
FSNamesystem fsn = null;
try {
fsn = FSNamesystem.loadFromDisk(conf);
// 加载完editlog之后,执行一次saveNamespace生成一个新的fsImage
fsn.getFSImage().saveNamespace(fsn);
MetaRecoveryContext.LOG.info("RECOVERY COMPLETE");
...到了这里,整个代码的执行流程就结束了。执行流程图如下:
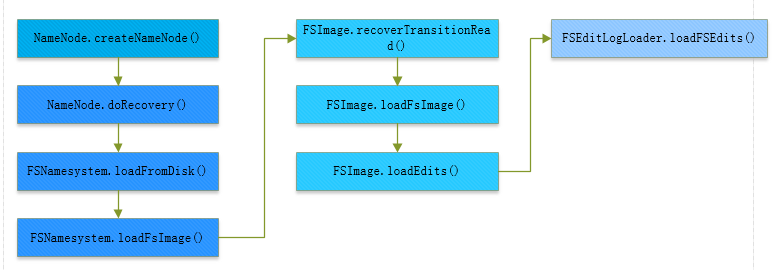
图 1-2 HDFS数据恢复模式执行流程图
有效editlog的定位寻找
最后我们再来关注一下之前跳过editlog的具体操作逻辑,就是rsync方法,
public void resync() {
if (cachedOp != null) {
return;
}
// 定位到下一个有效的editlog操作记录
cachedOp = nextValidOp();
}然后我们定位到其具体的子类实现,位于类EditLogFileInputStream中,
protected FSEditLogOp nextValidOp() {
try {
// 这里的true参数代表着要跳过坏的editlog记录
return nextOpImpl(true);
} catch (Throwable e) {
LOG.error("nextValidOp: got exception while reading " + this, e);
return null;
}
}上面方法最终将会执行到FSEditLogOp.Reader.readOp方法,执行逻辑如下,
public FSEditLogOp readOp(boolean skipBrokenEdits) throws IOException {
// 循环读取Op操作记录,直到找到一个有效的记录
while (true) {
try {
return decodeOp();
} catch (IOException e) {
in.reset();
if (!skipBrokenEdits) {
throw e;
}
} catch (RuntimeException e) {
...
// 判断是否跳过坏的edit记录,如果不跳过,此处将会抛出异常
if (!skipBrokenEdits) {
throw e;
}
} catch (Throwable e) {
in.reset();
// 判断是否跳过坏的edit记录,如果不跳过,此处将会抛出异常
if (!skipBrokenEdits) {
throw new IOException("got unexpected exception " +
e.getMessage(), e);
}
}
...
}
}HDFS数据恢复模式使用
前面已经提到过,HDFS数据恢复模式实质上是一种NameNode的启动方式,我们可以通过指定启动NameNode的参数来选择是否以这样的方式启动NameNode,输入hdfs namenode -help即可获取这些参数,
$ hdfs namenode -help
Usage: java NameNode [-backup] |
[-checkpoint] |
...
[-bootstrapStandby] |
[-recover [ -force] ] | // 以数据恢复模式的启动方式,force参数表示后面所有的提醒都默认选择第一个
[-metadataVersion ] ] 此种方式与之前脚本启动方式略有不同的一点在于,此类方式是前台启动的,用户能直观地看到NameNode的启动过程。
参考资料
[1].https://issues.apache.org/jira/browse/HDFS-3004
[2].https://issues.apache.org/jira/secure/attachment/12542798/recovery-mode.pdf