前言
缓存,英文单词译为Cache,缓存可以帮助我们干很多事,当然最直接的体会就是可以减少不必要的数据请求和操作.同样在HDFS中,也存在着一套完整的缓存机制,但可能使用了解此机制的人并不多,因为这个配置项平时大家比较少用而且HDFS中默认是关闭此功能的.至于是哪个配置项呢,在后面的描述中将会给出详细的分析.
HDFS缓存疑问点
为什么在这里会抛出这样一个问题呢,因为本人在了解完HDFS的Cache整体机理之后,确实感觉到其中的逻辑有点绕,直接分析不见得会起到很好的效果,所以先采取提问的形式来做一个引导会是一个不错的选择.列举如下几个问题,在这里缓存的对象block数据块,需要缓存的目标block叫做CacheBlock,block块从缓存状态需要转变为非缓存状态的block块称之为UnCacheBlock.
- 如何在物理层面缓存目标block块?
- 缓存块的生命周期状态有哪几种?
- 哪些情况会触发CacheBlock, UnCacheBlock操作?
- CacheBlock,UnCacheBlock缓存块如何确定?
- 系统所持有的CacheBlock列表如何更新?
- CacheBlock如何被使用?
现在依次从上到下依次揭开谜底,最后你一定会有种恍然大悟的感觉.
HDFS物理层面缓存Block
物理层面缓存Block,这个名词听上去意思怪怪的.在HDFS源码中的解释如下:
Manages caching for an FsDatasetImpl by using the mmap(2) and mlock(2) system calls to lock blocks into memory.大意为利用mmap,mlock系统调用将block锁入内存.没接触过底层操作系统知识的人可能不是很清楚mmap,mlock调用是怎么一回事,在这里就简单介绍一下.这里以mmap为例,他其实是一个内存映射调用,百度百科中关于mmap的解释如下:
mmap将一个文件或者其它对象映射进内存。文件被映射到多个页上,如果文件的大小不是所有页的大小之和,最后一个页不被使用的空间将会清零。mmap在用户空间映射调用系统中作用很大。我们主要关注前半部分的解释,将文件或其他对象映射进行内存,这句话直接在代码中得到了体现.
/**
* Load the block.
*
* mmap and mlock the block, and then verify its checksum.
*
* @param length The current length of the block.
* @param blockIn The block input stream. Should be positioned at the
* start. The caller must close this.
* @param metaIn The meta file input stream. Should be positioned at
* the start. The caller must close this.
* @param blockFileName The block file name, for logging purposes.
*
* @return The Mappable block.
*/
public static MappableBlock load(long length,
FileInputStream blockIn, FileInputStream metaIn,
String blockFileName) throws IOException {
MappableBlock mappableBlock = null;
MappedByteBuffer mmap = null;
FileChannel blockChannel = null;
try {
blockChannel = blockIn.getChannel();
if (blockChannel == null) {
throw new IOException("Block InputStream has no FileChannel.");
}
mmap = blockChannel.map(MapMode.READ_ONLY, 0, length);
NativeIO.POSIX.getCacheManipulator().mlock(blockFileName, mmap, length);
verifyChecksum(length, metaIn, blockChannel, blockFileName);
mappableBlock = new MappableBlock(mmap, length);
} finally {
IOUtils.closeQuietly(blockChannel);
if (mappableBlock == null) {
if (mmap != null) {
NativeIO.POSIX.munmap(mmap); // unmapping also unlocks
}
}
}
return mappableBlock;
}在上面的代码中,blockChannel对象(本质对象是FileChannel)就被映射到内存上了.OK,当然这是最底层执行的操作了,在HDFS中的上层调用是如何的呢,这才是我们所要真正关心的.
缓存块的生命周期状态
缓存块的生命周期不仅仅只有Cached(已缓存)和(UnCached)(已解除缓存)2种.在FSDatasetCache类中,有了明确的定义:
private enum State {
/**
* The MappableBlock is in the process of being cached.
*/
CACHING,
/**
* The MappableBlock was in the process of being cached, but it was
* cancelled. Only the FsDatasetCache#WorkerTask can remove cancelled
* MappableBlock objects.
*/
CACHING_CANCELLED,
/**
* The MappableBlock is in the cache.
*/
CACHED,
/**
* The MappableBlock is in the process of uncaching.
*/
UNCACHING;
/**
* Whether we should advertise this block as cached to the NameNode and
* clients.
*/
public boolean shouldAdvertise() {
return (this == CACHED);
}
}这个状态信息被保存在了实际存储的Value中
/**
* MappableBlocks that we know about.
*/
private static final class Value {
final State state;
final MappableBlock mappableBlock;
Value(MappableBlock mappableBlock, State state) {
this.mappableBlock = mappableBlock;
this.state = state;
}
}实际存储的Value与Block块就构成了Cache中非常常见的key-value的结构
/**
* Stores MappableBlock objects and the states they're in.
*/
private final HashMap<ExtendedBlockId, Value> mappableBlockMap =
new HashMap<ExtendedBlockId, Value>();可能有人会疑问为什么这里不直接用64位的blockId直接当key,而是用ExtendedBlockId,答案是因为要考虑到Block Pool的存在,现在的HDFS是支持多namespace命名空间的.ExtendedBlockId, Value键值对的存储与清除发生在cacheBlock和unCacheBlock方法.
/**
* Attempt to begin caching a block.
*/
synchronized void cacheBlock(long blockId, String bpid,
String blockFileName, long length, long genstamp,
Executor volumeExecutor) {
...
mappableBlockMap.put(key, new Value(null, State.CACHING));
volumeExecutor.execute(
new CachingTask(key, blockFileName, length, genstamp));
LOG.debug("Initiating caching for Block with id {}, pool {}", blockId,
bpid);
}然后放入CachingTask中异步执行.同理unCacheBlock方法也放在了异步线程中执行.
synchronized void uncacheBlock(String bpid, long blockId) {
ExtendedBlockId key = new ExtendedBlockId(blockId, bpid);
Value prevValue = mappableBlockMap.get(key);
boolean deferred = false;
...
switch (prevValue.state) {
case CACHING:
LOG.debug("Cancelling caching for block with id {}, pool {}.", blockId,
bpid);
mappableBlockMap.put(key,
new Value(prevValue.mappableBlock, State.CACHING_CANCELLED));
break;
case CACHED:
mappableBlockMap.put(key,
new Value(prevValue.mappableBlock, State.UNCACHING));
if (deferred) {
LOG.debug("{} is anchored, and can't be uncached now. Scheduling it " +
"for uncaching in {} ",
key, DurationFormatUtils.formatDurationHMS(revocationPollingMs));
deferredUncachingExecutor.schedule(
new UncachingTask(key, revocationMs),
revocationPollingMs, TimeUnit.MILLISECONDS);
} else {
LOG.debug("{} has been scheduled for immediate uncaching.", key);
uncachingExecutor.execute(new UncachingTask(key, 0));
}
break;
default:
LOG.debug("Block with id {}, pool {} does not need to be uncached, "
+ "because it is in state {}.", blockId, bpid, prevValue.state);
numBlocksFailedToUncache.incrementAndGet();
break;
}
}CacheBlock,UnCacheBlock场景触发
按照上面的问题顺序,第三个问题就是哪种情况会触发缓存块的行为呢.同样我们要将此情形分为2类,一个是cacheBlock,另外一个就是unCacheBlock.
CacheBlock动作
在ide中通过open call的方式可以追踪出他的上层方法调用,如图
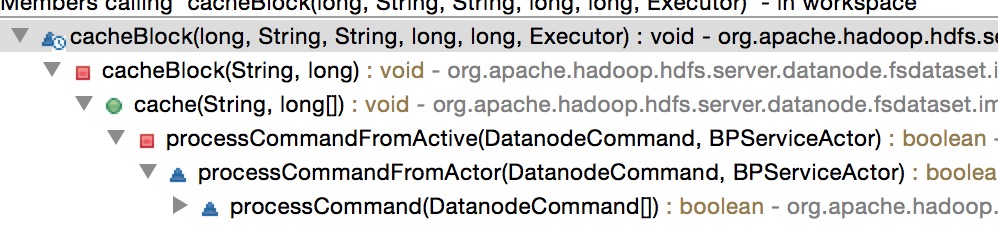
最下层的方法已经表明了此方法最终是来自于NameNode心跳处理的回复命令.挑出其中一个方法进行查阅
private boolean processCommandFromActive(DatanodeCommand cmd,
BPServiceActor actor) throws IOException {
final BlockCommand bcmd =
cmd instanceof BlockCommand? (BlockCommand)cmd: null;
final BlockIdCommand blockIdCmd =
cmd instanceof BlockIdCommand ? (BlockIdCommand)cmd: null;
switch(cmd.getAction()) {
...
case DatanodeProtocol.DNA_CACHE:
LOG.info("DatanodeCommand action: DNA_CACHE for " +
blockIdCmd.getBlockPoolId() + " of [" +
blockIdArrayToString(blockIdCmd.getBlockIds()) + "]");
dn.getFSDataset().cache(blockIdCmd.getBlockPoolId(), blockIdCmd.getBlockIds());
break;
...
default:
LOG.warn("Unknown DatanodeCommand action: " + cmd.getAction());
}
return true;
}UnCacheBlock动作
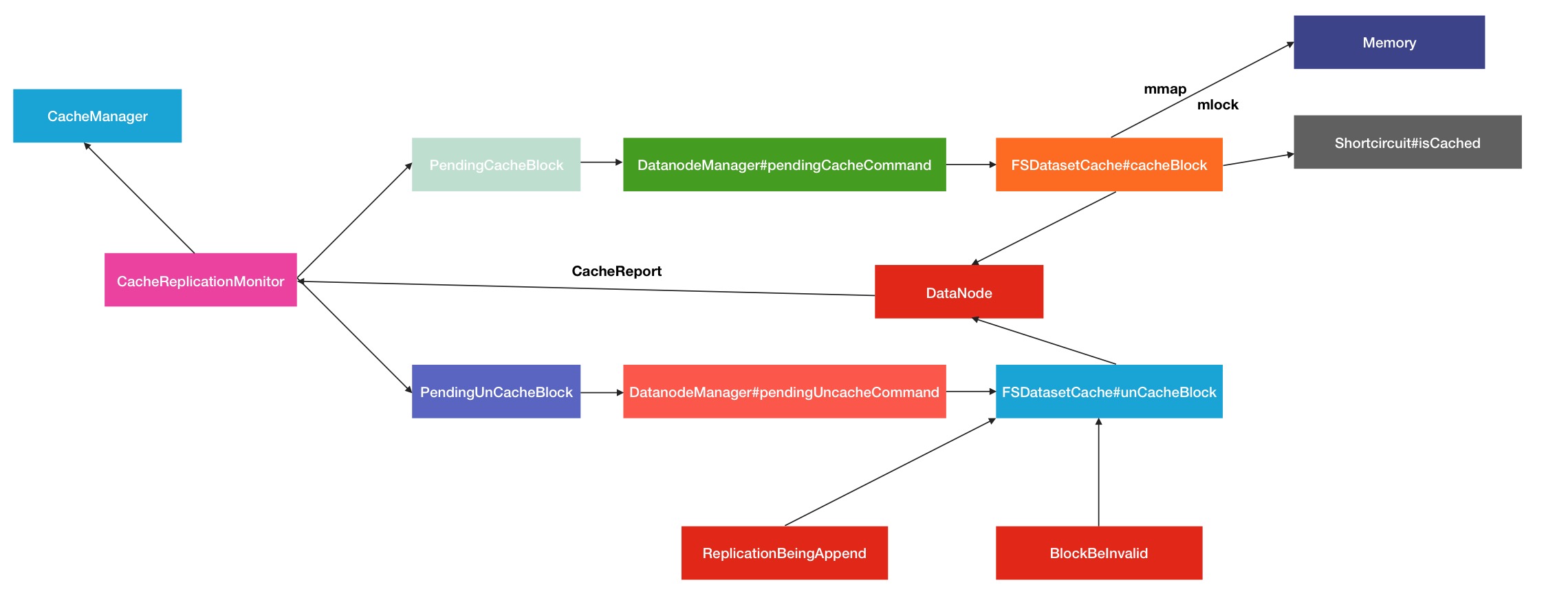
解除缓存block的动作是否也是来自于NameNode的反馈命令呢,答案其实并不仅限如此.同样给出调用关系图

可以看到,这里汇总成3类调用情况:
- 当block块被执行append写操作
- 当block被处理为invalidate的时候
- 上层NameNode发送unCache反馈命令
其中最后一种跟上小节提到的情况一样,是从NameNode中收到的反馈命令所致.前面2类情况导致unCache动作的理由很好理解.
- 因为block块被继续执行了写动作,数据必然发生改变,原有的cache缓存块就要重新被更新.
- 当block被处理为invalidate无效块的时候,接着会被NameNode从系统中清除,cache缓存块自然而言就没有存在的必要了.
CacheBlock,UnCacheBlock缓存块的确定
目标缓存块的确定问题本质上归结为就是上面NameNode中cacheBlock,unCacheBlock回复命令中的blockId组的缘来,就是下述代码中的block pool Id和blockIds.
dn.getFSDataset().cache(blockIdCmd.getBlockPoolId(), blockIdCmd.getBlockIds());blockIdCmd是NameNode心跳处理的回复命令,所以必然存在回复处理的过程,从而构造出了blockIdCmd的回复指令.这里直接定位到DatanodeManager#handleHeartbeat命令处理方法中
if (shouldSendCachingCommands &&
((nowMs - nodeinfo.getLastCachingDirectiveSentTimeMs()) >=
timeBetweenResendingCachingDirectivesMs)) {
// 构造需要缓存的block命令
DatanodeCommand pendingCacheCommand =
getCacheCommand(nodeinfo.getPendingCached(), nodeinfo,
DatanodeProtocol.DNA_CACHE, blockPoolId);
if (pendingCacheCommand != null) {
cmds.add(pendingCacheCommand);
sendingCachingCommands = true;
}
// 构造需要解除缓存的block命令
DatanodeCommand pendingUncacheCommand =
getCacheCommand(nodeinfo.getPendingUncached(), nodeinfo,
DatanodeProtocol.DNA_UNCACHE, blockPoolId);
if (pendingUncacheCommand != null) {
cmds.add(pendingUncacheCommand);
sendingCachingCommands = true;
}
if (sendingCachingCommands) {
nodeinfo.setLastCachingDirectiveSentTimeMs(nowMs);
}
}从这里可以看出,cacheBlock和unCacheBlock来源于nodeInfo中的pendingCache和pendingUncache,实质获取的变量如下:
/**
* The blocks which we know are cached on this datanode.
* This list is updated by periodic cache reports.
*/
private final CachedBlocksList cached =
new CachedBlocksList(this, CachedBlocksList.Type.CACHED);
/**
* The blocks which we want to uncache on this DataNode.
*/
private final CachedBlocksList pendingUncached =
new CachedBlocksList(this, CachedBlocksList.Type.PENDING_UNCACHED);好像离目标越来越近了,只要能找到CachedBlockList的直接操作方,就能明白缓存block以及解除缓存block是如何确定的.通过进一步的上层调用,最后发现真正的操作主类CacheReplicationMonitor,这个类的用途如下:
Scans the namesystem, scheduling blocks to be cached as appropriate.在这里,我做些补充解释,CacheReplicationMonitor自身持有一个系统中的标准缓存块列表,然后通过自身内部的缓存原则,进行cacheBlock的添加和移除,然后对应更新到之前提到过的pendingCache和pendingUncache列表中,随后这些pending信息就会被NameNode拿来放入回复命令中.这里就会有2个疑惑点:
- CacheReplicationMonitor内部维护的系统标准缓存块哪里来
- CacheReplicationMonitor内部缓存原则,策略是什么,什么情况下block应该被Cache,什么情况下又可以取消Cache
第一个问题会在下面的小节中提到,这里集中看第二条.答案在rescanCachedBlockMap的方法中.鉴于此方法代码处理逻辑比较复杂,我们直接看方法注释中的解释:
Scan through the cached block map.
Any blocks which are under-replicated should be assigned new Datanodes.
Blocks that are over-replicated should be removed from Datanodes.这里给出了2个基本原则:
- 任何少于标准副本块个数的副本应该缓存到新的节点上
- 过副本数的缓存block应该从节点上进行移除
其实仔细一想,这个策略还是很巧妙的,尽量多缓存一些副本数不够的副本(缓存相当于充当了1块副本),移除掉副本数过多的多余缓存.
系统持有的CacheBlock列表如何更新
在上节中提到过CacheReplicationMonitor对象持有的系统CacheBlock列表如何被更新的问题,这个列表是用来发送pendingCache,pengdUncache信息的基础.因为是系统所全局持有的,会存在反馈上报的过程.同样存在于心跳处理代码的附近.
...
List<DatanodeCommand> cmds = blockReport();
processCommand(cmds == null ? null : cmds.toArray(new DatanodeCommand[cmds.size()]));
// 缓存块的上报
DatanodeCommand cmd = cacheReport();
processCommand(new DatanodeCommand[]{ cmd });
...继续调用到下面这行操作
// 获取到datanode上的缓存块的blockId
List<Long> blockIds = dn.getFSDataset().getCacheReport(bpid);最后又重新调用到了FSDatasetCache中的getCacheBlocks方法.到这里你应该可以发现,这里形成了一个闭环操作.最后的缓存操作执行者同样也是缓存块情况的反馈者.CacheReplicationMonitor属于CacheManager对象的内部变量,会从中拿到cacheBlock块的最新信息.
CacheBlock的使用
这时候重新回头看CacheBlock缓存块的使用问题就显得很简单了,cacheBlock在shortCirCuit读操作中的请求文件描述符的时候用到.
public void requestShortCircuitFds(final ExtendedBlock blk,
final Token<BlockTokenIdentifier> token,
SlotId slotId, int maxVersion, boolean supportsReceiptVerification)
throws IOException {
...
if (slotId != null) {
boolean isCached = datanode.data.
isCached(blk.getBlockPoolId(), blk.getBlockId());
datanode.shortCircuitRegistry.registerSlot(
ExtendedBlockId.fromExtendedBlock(blk), slotId, isCached);
registeredSlotId = slotId;
}
fis = datanode.requestShortCircuitFdsForRead(blk, token, maxVersion);
Preconditions.checkState(fis != null);
bld.setStatus(SUCCESS);
bld.setShortCircuitAccessVersion(DataNode.CURRENT_BLOCK_FORMAT_VERSION);
... 最后,给出整个调用流程,你可以明显看到中间的一个闭环
HDFS缓存控制配置
说了这么多关于HDFS缓存的原理和内容后,一定要补充介绍管控此功能的配置项,如下,附上解释:
<property>
<name>dfs.datanode.max.locked.memory</name>
<value>0</value>
<description>
The amount of memory in bytes to use for caching of block replicas in
memory on the datanode. The datanode's maximum locked memory soft ulimit
(RLIMIT_MEMLOCK) must be set to at least this value, else the datanode
will abort on startup.
By default, this parameter is set to 0, which disables in-memory caching.
If the native libraries are not available to the DataNode, this
configuration has no effect.
</description>
</property>看完这个配置,估计你的第一反应也是这个配置项的名称与实际所使用的功能情况不太一致,有点歧义的感觉,可能叫dfs.datanode.max.cache.memory比较好理解一些.这个配置项控制的是下面这个变量:
首先是在FSDatasetCache构造函数中拿到此属性值
this.maxBytes = dataset.datanode.getDnConf().getMaxLockedMemory();然后在usedBytes对象的使用上做限制
long reserve(long count) {
count = rounder.round(count);
while (true) {
long cur = usedBytes.get();
long next = cur + count;
if (next > maxBytes) {
return -1;
}
if (usedBytes.compareAndSet(cur, next)) {
return next;
}
}
}这个配置默认关闭的,大家可以通过改变此配置的值来开启此功能,对于HDFS读性能将会带来不小的提升.