前言
最近在工作中解决了一个慢磁盘的问题,个人感觉整个发现-分析-解决的过程还是非常有意思并且很有意义的.而且磁盘监控在目前的Hadoop中还是没有做的很全的,大多数都是对Datanode,可以说这是1个盲区.其实想一想,hadoop自身不做这方面的监控也合理,因为像这种问题基本上是属于硬件问题,本不应该在软件层面对其进行监控,没有这么大的必要.但是后来我们想了想,如果通过软件层面的监控手段发现机器硬件上的问题也不错,至少能发现问题,何乐而不为呢.下面进入文章的正题.
慢磁盘
在这里我姑且用这个名词来解释这个现象,用专业点的英文术语说应该是slow-writed disk,译为写入操作很慢的磁盘,写操作主要包括创建文件,目录,写文件这些操作.而慢磁盘的理解就是进行这些写操作耗时远远超出平均值时间的磁盘.我们在最近就碰到了这样的场景,其他正常的盘基本上创建1个Test目录,只需1/10或者快的1/100秒左右的时间,而我惊奇的发现有块盘竟然花了5分钟左右,而且更奇怪的是,有的时候会出现有的时候又不会出现这样的现象.一旦出现了慢磁盘,将会严重拖慢这个节点的整体运行效率,继而让此节点成为集群中的慢节点,最后影响整个集群.那么问题来了,既然慢磁盘这么重要,我们怎么准确定位到哪台机器的哪块磁盘有问题的,那么多个节点,每个节点上又有那么多块盘.
慢磁盘的发现
下面教大家几个方法:
1.通过心跳未联系次数.一般如果出现慢磁盘现象,会影响到datanode与namenode的心跳,这个值会变得很大.
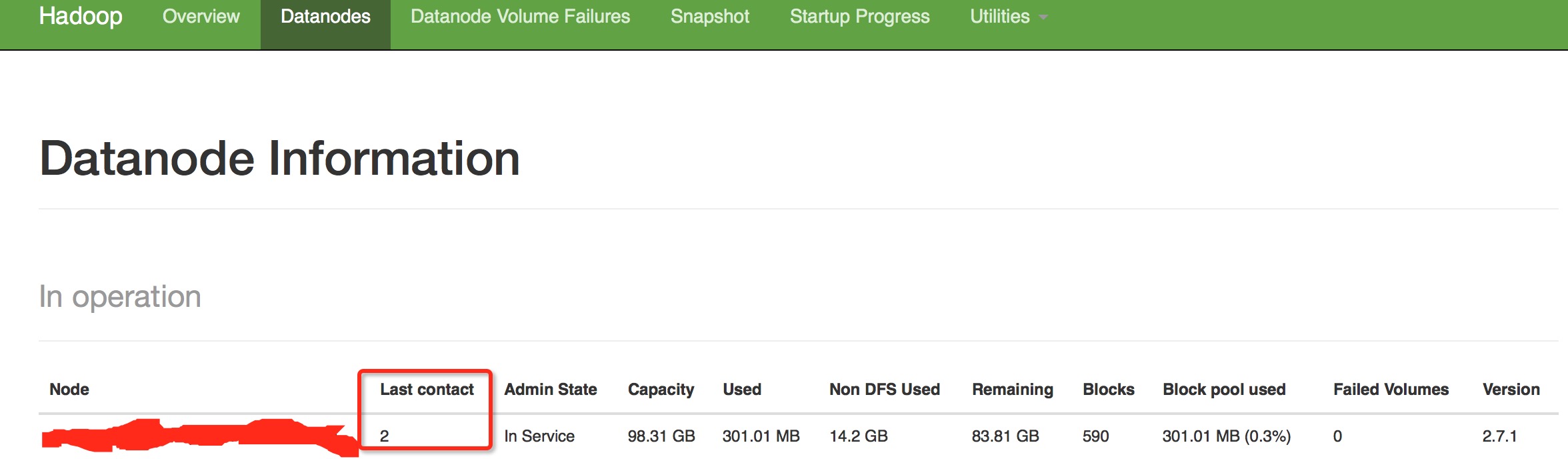
2.通过ganglia对datanode写操作相关的监控,这个是传统的方式.

对比几个特殊的节点观察时间有没有特别长的.
当然以上是确定可疑慢磁盘所在节点,假设异常节点已经发现,下面是怎么发现上面的慢磁盘,这个方法不用想的那么复杂,这里提供最简单的方法,写1个脚本,在所有的磁盘上执行
time mkdir test
rm -r -f test观察哪个磁盘所花的时间最长就可以了.当然你想用Linux工具专门的检查磁盘读写性能的命令,当然最好了.
慢磁盘监控
上面提供的方法在使用性和准确性方面还是存在许多偏差的,尤其是在寻找慢磁盘的方法上,因此最权威的方法还是在hadoop层面对每个磁盘进行写操作的时间进行监控,这无疑是最准的,所以我们要加自定义的Metrics代码,下面简单介绍一下我们是如何对此进行改造的.首先要明白一定的原理,datanode写磁盘对应的关系是
Datanode-->FsDatasetImpl-->volumesList
在volumesList里就对应包含了配置文件中配的各个文件写入磁盘目录.每个磁盘对应的类是FsVolumeImpl.在FsVolumeImpl类中就包含了许多创建文件的方法.
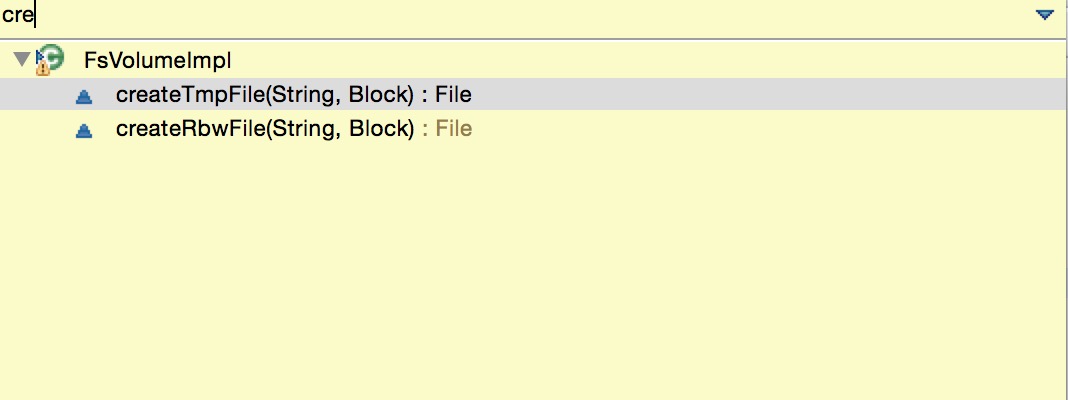
这些创建的文件就会最终写入这个类所代表的磁盘中,因此我们要监控的对象就是这个对象.OK,下面我们如何开始呢,最文章开始的时候已经说了,Hadoop社区没有对fsVolume做额外的监控,所以需要自己新定义1个,那就叫FsVolumsMetrics,指标如下:
@Metrics(about = "FsVolume metrics", context = "dfs")
public class FsVolumeMetrics {
static final Log LOG = LogFactory.getLog(FsVolumeMetrics.class);
private static final Map<String, FsVolumeMetrics> REGISTRY =
Maps.newHashMap();
int getTmpInputStreamsCounter;
int createTmpFileCounter;
int createRbwFileCounter;
int getTmpInputStreamsTimeoutCounter;
int createTmpFileTimeoutCounter;
int createRbwFileTimeoutCounter;
MetricsRegistry registry = null;
@Metric
MutableRate getTmpInputStreamsOp;
@Metric
MutableRate createTmpFileOp;
@Metric
MutableRate createRbwFileOp;
@Metric
MutableRate getTmpInputStreamsTimeout;
@Metric
MutableRate createTmpFileTimeout;
@Metric
MutableRate createRbwFileTimeout;
private FsVolumeMetrics(FsVolumeImpl volume) {
this.createRbwFileCounter = 0;
this.createTmpFileCounter = 0;
this.getTmpInputStreamsCounter = 0;
this.createRbwFileTimeoutCounter = 0;
this.createTmpFileTimeoutCounter = 0;
this.getTmpInputStreamsTimeoutCounter = 0;
String name = "fsVolume:" + volume.getBasePath();
LOG.info("Register fsVolumn metric for path: " + name);
registry = new MetricsRegistry(name);
}
static FsVolumeMetrics create(FsVolumeImpl volume) {
String n = "fsVolume:" + volume.getBasePath();
LOG.info("Create fsVolumn metric for path: " + n);
synchronized (REGISTRY) {
FsVolumeMetrics m = REGISTRY.get(n);
if (m == null) {
m = new FsVolumeMetrics(volume);
DefaultMetricsSystem.instance().register(n, null, m);
REGISTRY.put(n, m);
}
return m;
}
}
public void addGetTmpInputStreamsOp(long time) {
getTmpInputStreamsCounter++;
getTmpInputStreamsOp.add(time);
}
public void addGetTmpInputStreamsTimeout(long time) {
getTmpInputStreamsTimeoutCounter++;
getTmpInputStreamsTimeout.add(time);
}
public void addCreateTmpFileOp(long time) {
createTmpFileCounter++;
createTmpFileOp.add(time);
}
public void addCreateTmpFileTimeout(long time) {
createTmpFileTimeoutCounter++;
createTmpFileTimeout.add(time);
}
public void addCreateRbwFileOp(long time) {
createRbwFileCounter++;
createRbwFileOp.add(time);
}
public void addCreateRbwFileTimeout(long time) {
createRbwFileTimeoutCounter++;
createRbwFileTimeout.add(time);
}
}public static final String DFS_WRITE_VOLUME_THRESHOLD_TIME_MS =
"dfs.write.volume.threshold.time.ms";
public static final long DFS_WRITE_VOLUME_THRESHOLD_TIME_MS_DEFAULT = 300; FsVolumeImpl(FsDatasetImpl dataset, String storageID, File currentDir,
Configuration conf, StorageType storageType) throws IOException {
this.dataset = dataset;
this.storageID = storageID;
this.reserved = conf.getLong(
DFSConfigKeys.DFS_DATANODE_DU_RESERVED_KEY,
DFSConfigKeys.DFS_DATANODE_DU_RESERVED_DEFAULT);
this.reservedForRbw = new AtomicLong(0L);
....
metric = FsVolumeMetrics.create(this);
}@Override // FsDatasetSpi
public synchronized ReplicaHandler createRbw(
StorageType storageType, ExtendedBlock b, boolean allowLazyPersist)
throws IOException {
ReplicaInfo replicaInfo = volumeMap.get(b.getBlockPoolId(),
b.getBlockId());
....
}
FsVolumeImpl v = (FsVolumeImpl) ref.getVolume();
// create an rbw file to hold block in the designated volume
File f;
try {
long startTime = Time.monotonicNow();
f = v.createRbwFile(b.getBlockPoolId(), b.getLocalBlock());
long duration = Time.monotonicNow() - startTime;
if (duration > volumeThresholdTime) {
LOG.warn("Slow create RbwFile to volume=" + v.getBasePath() + " took "
+ duration + "ms (threshold=" + volumeThresholdTime + "ms)");
v.metric.addCreateRbwFileTimeout(duration);
}
v.metric.addCreateRbwFileOp(duration);
} catch (IOException e) {
IOUtils.cleanup(null, ref);
throw e;
}
.....
}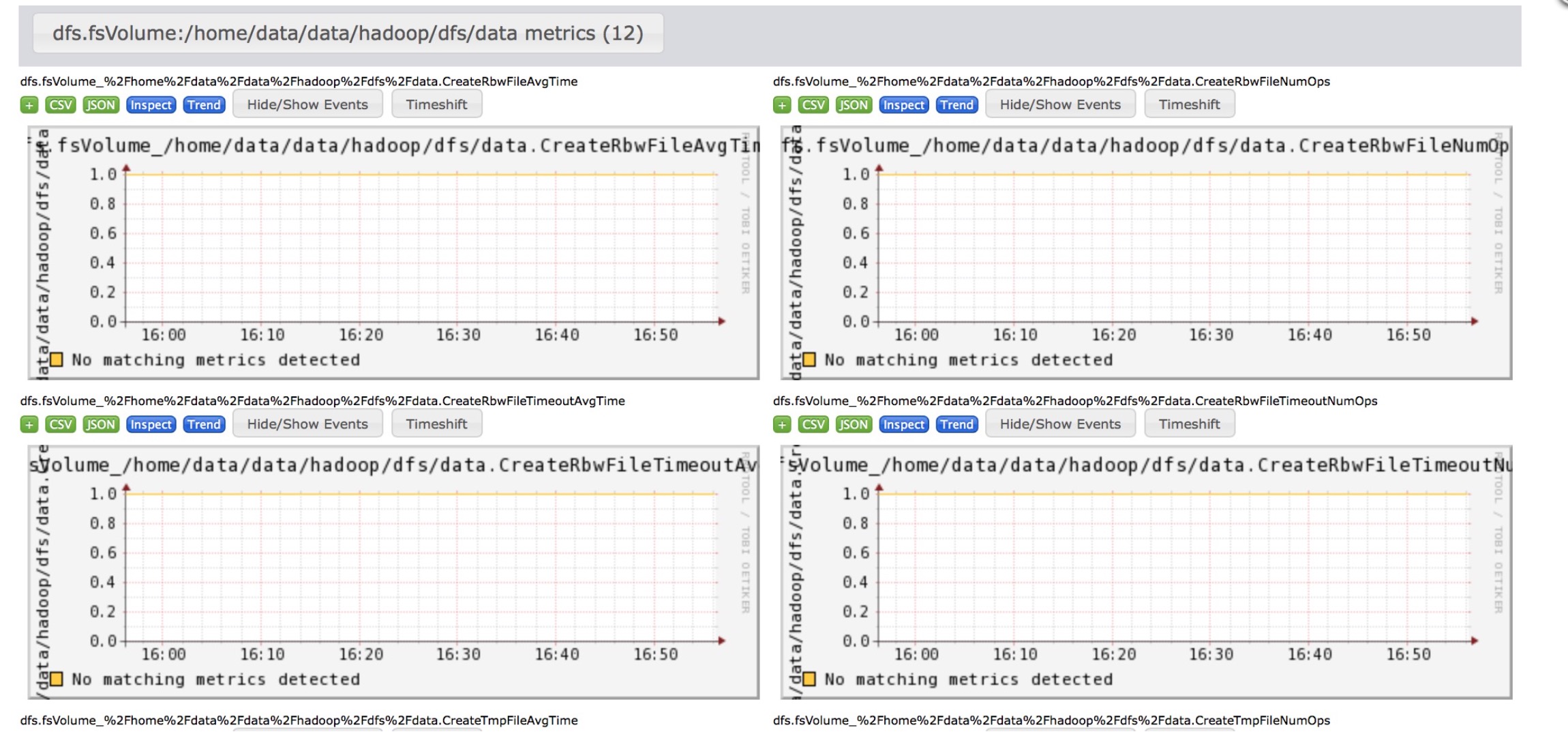
因为我配置的data.dir是/home/data/data/hadoop/dfs/data,所以就会出现上面那么长的标题,这就是我们要达到的最终效果,希望能带给大家收获.此功能我已经打成patch,提交开源社区,编号HDFS-9510,要使用的同学可以自行git apply.
慢磁盘解决
如果慢磁盘已经发现了,怎么解决呢,最干脆的方法就是立即下线,不要在往这块盘上写数据了,并联系运维部门进行处理或者说你们自己内部想办法解决.但是还是那句话,像慢磁盘这样的偏硬件性的问题还是交给这方面专业的人去解决比较稳妥.
相关链接:
Issue 链接:https://issues.apache.org/jira/browse/HDFS-9510
Github patch链接:https://github.com/linyiqun/open-source-patch/blob/master/hdfs/HDFS-9510/HDFS-9510.002.patch