前言
任何分布式系统在不断演变的过程中,必然都会经过有小变到大的过程,中间也必定会由不稳定到逐步稳定的过程.在所有的这些系统能够稳定运行的一个前提是,完整的监控和报警系统.这个模块是系统保持稳定最最基础的模块服务.只有在这块功能完善的情况下,才会让系统的维护者更高效的定位到问题所在,减少不必要的时间消耗,才会有更多的时间去做其他方面的一些优化.今天我所主要描述的就是对于Hadoop的强大监控工具Ganglia.
Ganglia
先来说说什么是Ganglia,Ganglia是开源的集群监控项目,代码可以在github社区进行下载.Ganglia的架构设计也是类似于Client-Server的模式,Client端会开启gmond进程进行客户端监控数据的收集,然后发给Server端,server端对数据进行收集并进行页面的展示,下面是一张结构图,大家只需做大致了解即可.
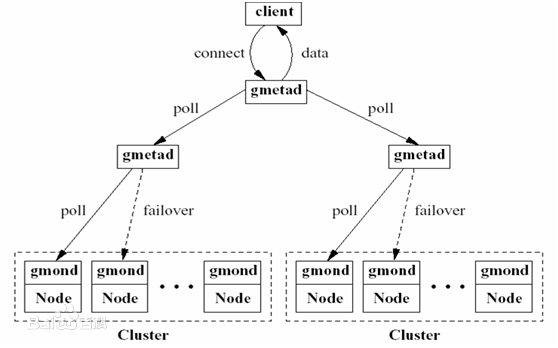
那么Ganglia与Hadoop,Yarn有什么关系呢.应该说Ganglia对Hadoop进行了很完美的支持,看过Ganglia监控界面的同学,应该知道Hadoop在Ganglia上定义了非常多细粒度的指标,基本涉及了非常多方面的统计信息.这里还需提到一点,Ganglia对HBase的支持也十分完美.
Hadoop的Ganglia统计指标
下面是文章描述的重点,Hadoop如何将统计指标注册到Ganglia上的呢,而且还能定期发送最新的数据.以DataNode数据节点为例.与DataNode统计相关的维度列表信息显示如下:
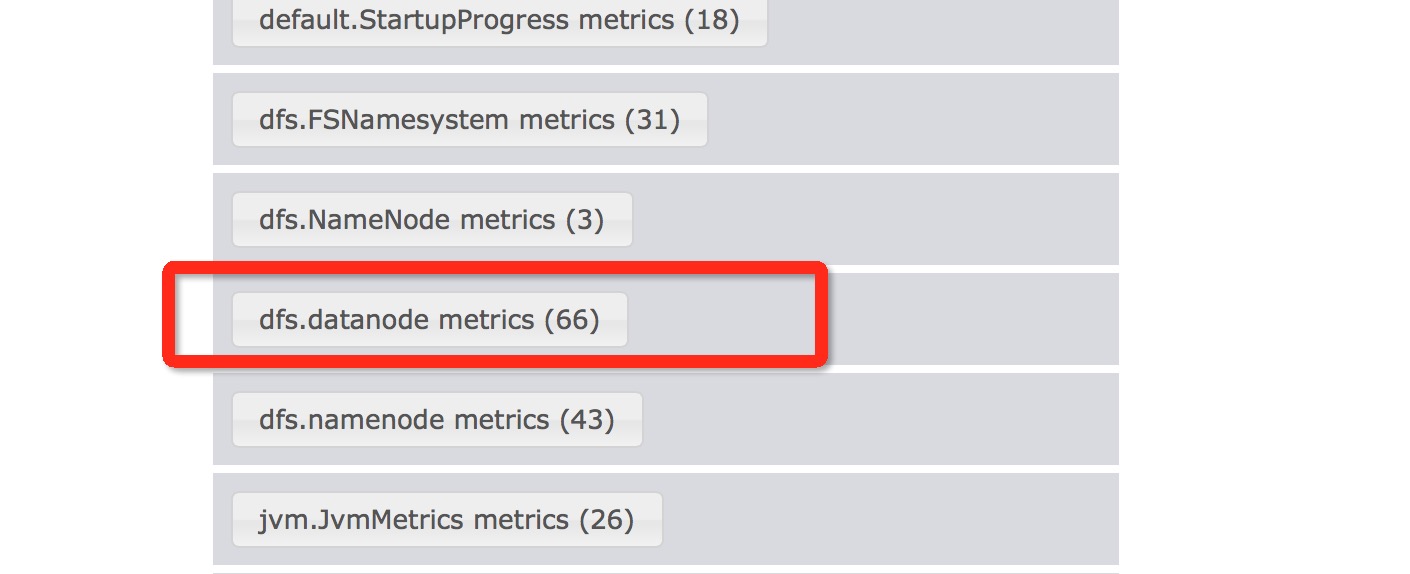
这个名称定义也是有来头的,这个名称是与相应的Metric类是相关的.比如dfs.datanode metrics ,以点分为2个部分,第一个dfs为上下文,第二个为具体的统计名称.上下文由下面的行定义
/**
*
* This class is for maintaining the various DataNode statistics
* and publishing them through the metrics interfaces.
* This also registers the JMX MBean for RPC.
* <p>
* This class has a number of metrics variables that are publicly accessible;
* these variables (objects) have methods to update their values;
* for example:
* <p> {@link #blocksRead}.inc()
*
*/
@InterfaceAudience.Private
@Metrics(about="DataNode metrics", context="dfs")
public class DataNodeMetrics {
...@InterfaceAudience.Private
@Metrics(about="DataNode metrics", context="dfs")
public class DataNodeMetrics {
....
final MetricsRegistry registry = new MetricsRegistry("datanode");那么再在Ganglia上点击详情指标统计图,就呈现了各式各样的指标统计.
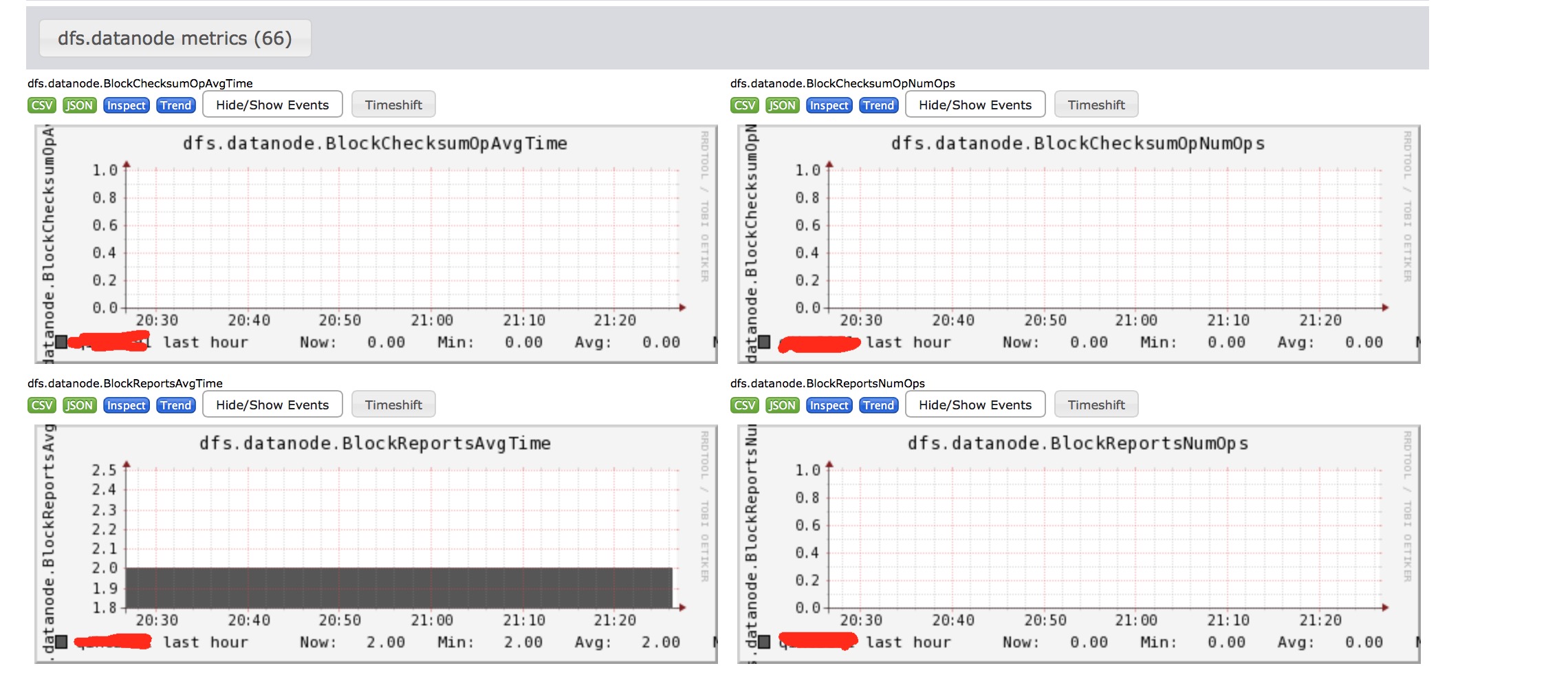
这些指标其实对应的就是DataNodeMetrics中定义的类变量.比如第二个变量blockChecsum检查操作次数为:
MutableCounterLong datanodeNetworkErrors;
@Metric MutableRate readBlockOp;
@Metric MutableRate writeBlockOp;
@Metric MutableRate blockChecksumOp;...
public void incrBlocksReplicated(int delta) {
blocksReplicated.incr(delta);
}
public void incrBlocksWritten() {
blocksWritten.incr();
}
public void incrBlocksRemoved(int delta) {
blocksRemoved.incr(delta);
}
public void incrBytesWritten(int delta) {
bytesWritten.incr(delta);
}
...public void incrBlocksWritten() {
blocksWritten.incr();
}void receiveBlock(
DataOutputStream mirrOut, // output to next datanode
DataInputStream mirrIn, // input from next datanode
DataOutputStream replyOut, // output to previous datanode
String mirrAddr, DataTransferThrottler throttlerArg,
DatanodeInfo[] downstreams,
boolean isReplaceBlock) throws IOException {
syncOnClose = datanode.getDnConf().syncOnClose;
....
// If this write is for a replication or transfer-RBW/Finalized,
// then finalize block or convert temporary to RBW.
// For client-writes, the block is finalized in the PacketResponder.
if (isDatanode || isTransfer) {
// Hold a volume reference to finalize block.
try (ReplicaHandler handler = claimReplicaHandler()) {
// close the block/crc files
close();
block.setNumBytes(replicaInfo.getNumBytes());
if (stage == BlockConstructionStage.TRANSFER_RBW) {
// for TRANSFER_RBW, convert temporary to RBW
datanode.data.convertTemporaryToRbw(block);
} else {
// for isDatnode or TRANSFER_FINALIZED
// Finalize the block.
datanode.data.finalizeBlock(block);
}
}
datanode.metrics.incrBlocksWritten();
}
...下面来看看另外一个NameNode的Ganglia指标统计.在NameNode中,存在同样对应的统计类NameNodeMetrics.
/**
* This class is for maintaining the various NameNode activity statistics
* and publishing them through the metrics interfaces.
*/
@Metrics(name="NameNodeActivity", about="NameNode metrics", context="dfs")
public class NameNodeMetrics {
final MetricsRegistry registry = new MetricsRegistry("namenode");
.../**
* This class is for maintaining the various NameNode activity statistics
* and publishing them through the metrics interfaces.
*/
@Metrics(name="NameNodeActivity", about="NameNode metrics", context="dfs")
public class NameNodeMetrics {
final MetricsRegistry registry = new MetricsRegistry("namenode");
@Metric MutableCounterLong createFileOps;
@Metric MutableCounterLong filesCreated;
@Metric MutableCounterLong filesAppended;
@Metric MutableCounterLong getBlockLocations;
@Metric MutableCounterLong filesRenamed;
@Metric MutableCounterLong filesTruncated;
@Metric MutableCounterLong getListingOps;
@Metric MutableCounterLong deleteFileOps;
@Metric MutableCounterLong requestOps;
@Metric("Number of files/dirs deleted by delete or rename operations")
MutableCounterLong filesDeleted;
@Metric MutableCounterLong fileInfoOps;
@Metric MutableCounterLong addBlockOps;
@Metric MutableCounterLong getAdditionalDatanodeOps;
@Metric MutableCounterLong createSymlinkOps;
@Metric MutableCounterLong getLinkTargetOps;
@Metric MutableCounterLong filesInGetListingOps;
@Metric("Number of allowSnapshot operations")最后重点说说RM,ResourceManager的监控,为什么说是重点说说呢,因为这个类在Hadoop原有的代码中是不存在的.我自己新加的,就是ResourceManagerMetrics,取这个名称是保持之前的一致性.RM的统计在目前的Ganglia上非常缺乏.因此我加了许多RM相关关键指标的统计.主要包含如下几点.
1.Container容器allocated申请与released释放成功失败次数.
2.Application应用注册与注销次数.
3.关闭应用次数统计.
父类的名称为rpc.ResourceManager metrics
@InterfaceAudience.Private
@Metrics(about="ResourceManager metrics", context="rpc")
public class ResourceManagerMetrics {
final MetricsRegistry registry = new MetricsRegistry("Resourcemanager");
String name;
public static final String KILL_APP_REQUEST = "Kill Application Request";
public static final String SUBMIT_APP_REQUEST = "Submit Application Request";
public static final String MOVE_APP_REQUEST = "Move Application Request";
public static final String FINISH_SUCCESS_APP = "Application Finished - Succeeded";
public static final String FINISH_FAILED_APP = "Application Finished - Failed";
public static final String FINISH_KILLED_APP = "Application Finished - Killed";
public static final String REGISTER_AM = "Register App Master";
public static final String AM_ALLOCATE = "App Master Heartbeats";
public static final String UNREGISTER_AM = "Unregister App Master";
public static final String ALLOC_CONTAINER = "AM Allocated Container";
public static final String RELEASE_CONTAINER = "AM Released Container";@Metric MutableCounterLong cmAllocatedSuccessOps;
@Metric MutableCounterLong cmReleasedSuccessOps;
@Metric MutableCounterLong killAppRequestSuccessOps;
@Metric MutableCounterLong submitAppRequestSuccessOps;
@Metric MutableCounterLong moveAppRequestSuccessOps;
@Metric MutableCounterLong registerAMSuccessOps;
@Metric MutableCounterLong unRegisterAMSuccessOps;
@Metric MutableCounterLong amAllocatedSuccessOps;
@Metric MutableCounterLong finishSucceedAppSuccessOps;
@Metric MutableCounterLong finishFailedAppSuccessOps;
@Metric MutableCounterLong finishKilledAppSuccessOps;
@Metric MutableCounterLong cmAllocatedFailedOps;
@Metric MutableCounterLong cmReleasedFailedOps;
@Metric MutableCounterLong killAppRequestFailedOps;
@Metric MutableCounterLong submitAppRequestFailedOps;
@Metric MutableCounterLong moveAppRequestFailedOps;
@Metric MutableCounterLong registerAMFailedOps;
@Metric MutableCounterLong unRegisterAMFailedOps;
@Metric MutableCounterLong amAllocatedFailedOps;
@Metric MutableCounterLong finishSucceedAppFailedOps;
@Metric MutableCounterLong finishFailedAppFailedOps;
@Metric MutableCounterLong finishKilledAppFailedOps;public void incrContainerAllcatedOpr(String opr, String result){
if(opr.equals(ALLOC_CONTAINER)){
if(result.equals("SUCCESS")){
cmAllocatedSuccessOps.incr();
}else if (result.equals("FAILED")){
cmAllocatedFailedOps.incr();
}
}
}/**
* A helper api for creating an audit log for a failure event.
*/
static String createFailureLog(String user, String operation, String perm,
String target, String description, ApplicationId appId,
ApplicationAttemptId attemptId, ContainerId containerId) {
rmm.incrFailedOpr(operation);
OK,分析到这里,最后看一下与本文所贯穿的主要结构图.
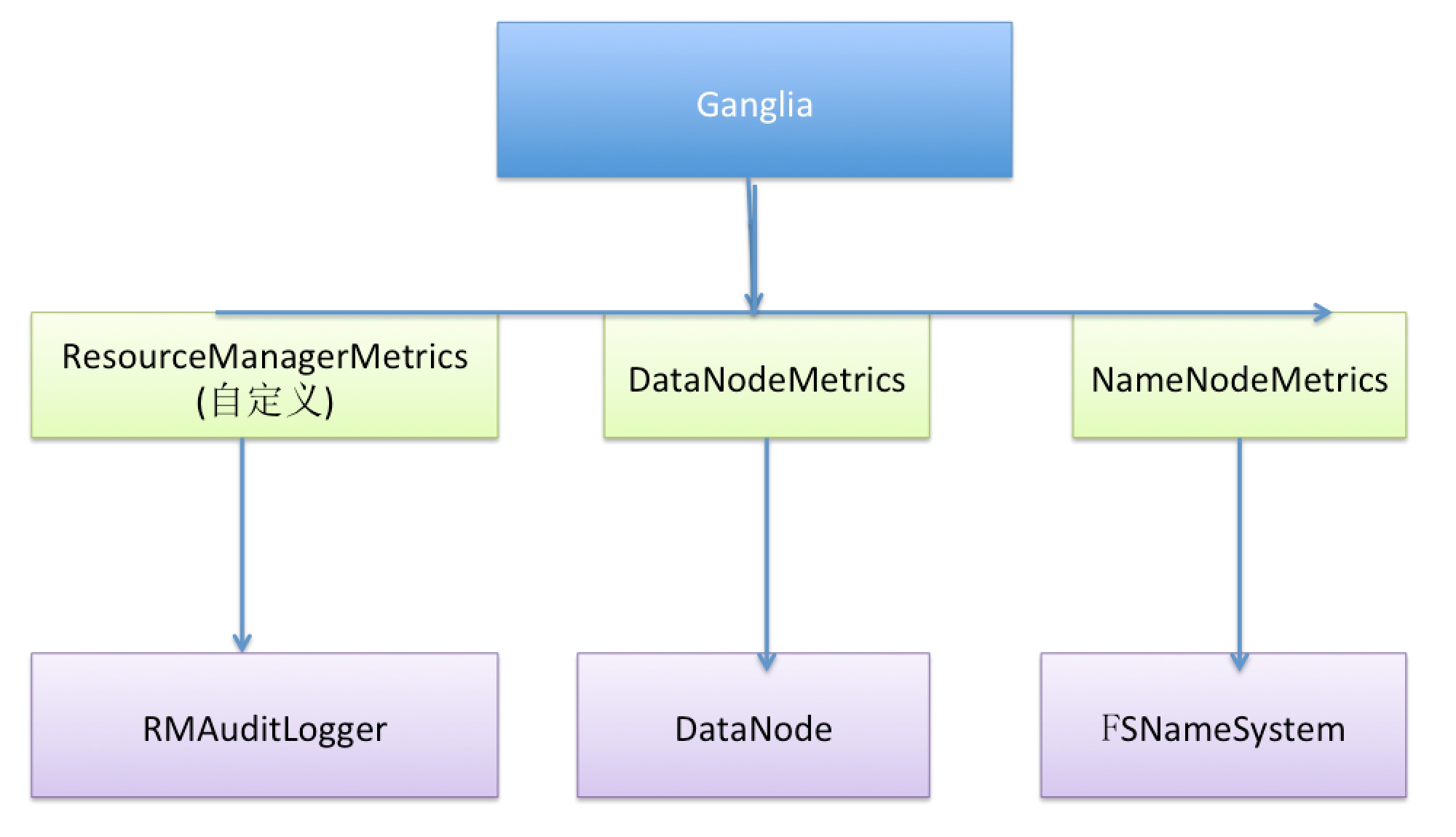
同时对ResourceManagerMetrics代码有兴趣的同学,请看下面的链接.
全部代码的分析请点击链接https://github.com/linyiqun/hadoop-yarn/tree/master/RMMetric,后续将会继续更新YARN其他方面的代码分析。
参考源代码
Apach-hadoop-2.7.1(hadoop-hdfs-project)