背景
某银行客户,RAC 11.2.0.4 Linux环境在7月14日进行跑批业务,平时20分钟左右完成,今日将近2个小时才完成,客户反馈,跑批任务一直在1节点进行,现给出4份AWR报告,希望分析故障原因。(报告包含2份正常时段和2份异常时段)
问题分析
1、对比4份报告--正常时段
根据2份正常时段的报告抬头,跑批任务确实在1节点运行,26分钟完成跑批任务,与客户反馈相符
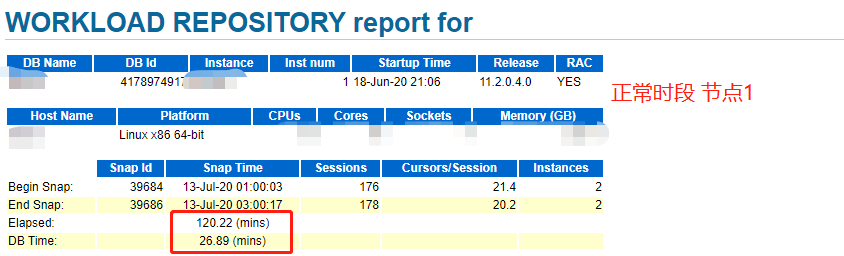

2、对比4份报告--异常时段
再观察2份异常时段的报告抬头,发现RAC 双节点的DB运行时间均在2个半小时,与客户之前反馈,任务只在一节点跑,不相符,由此我们大概可以判断问题的方向,1)可能是任务被负载均衡到2个节点,2)可能任务直接就在2节点运行
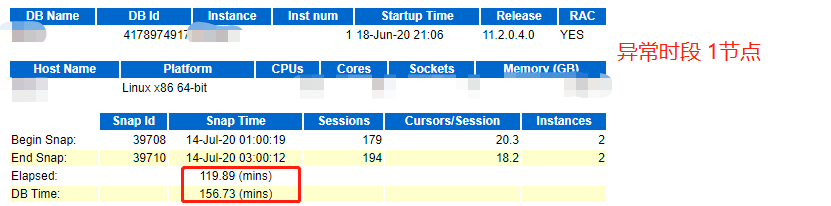

3、分析4份报告Load Profile
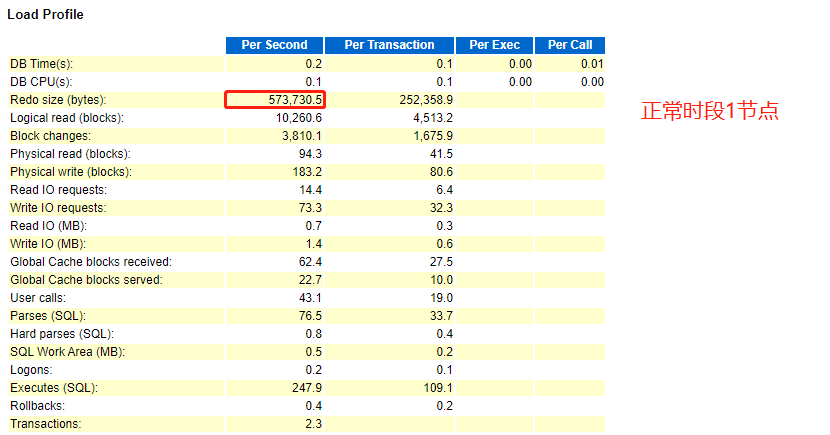
因正常时段主要在1节点,我们可以注重分析1节点报告,进而和异常时段的两份报告做对比。
- 正常时段
- 异常时段
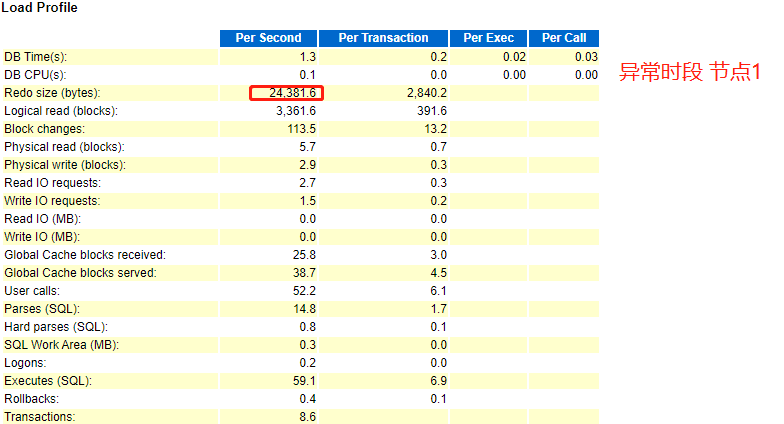
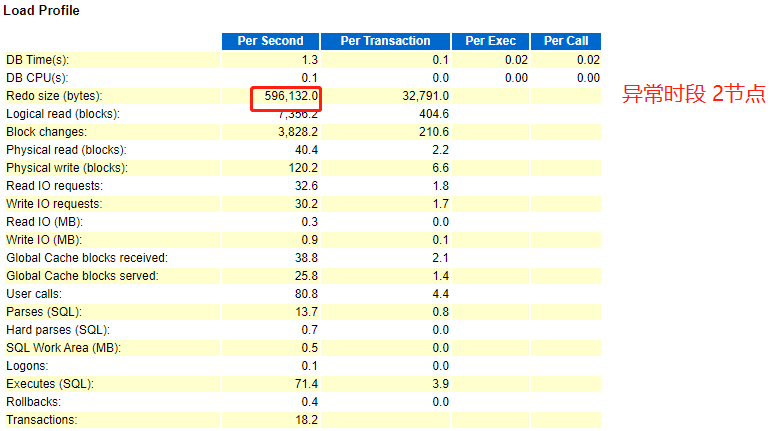
根据跑批时段产生的redo size 大小,我们可以判断,正常时段节点1和异常时段节点2,产生redo size 大小一致,对此,我们可以断定,异常时段的跑批任务肯定是在2节点运行。
4、异常时段在2节点跑批验证
仅仅根据redo size如果不能说服,我们可以进一步分析,执行跑批的具体SQL。和客户沟通后,我们在正常时段节点1找到跑批的主SQL语句,同样的,我们在异常时段的2节点发现执行跑批SQL,且运行时间较长,这就进一步验证异常时段跑批任务是在2节点进行。
- 正常时段
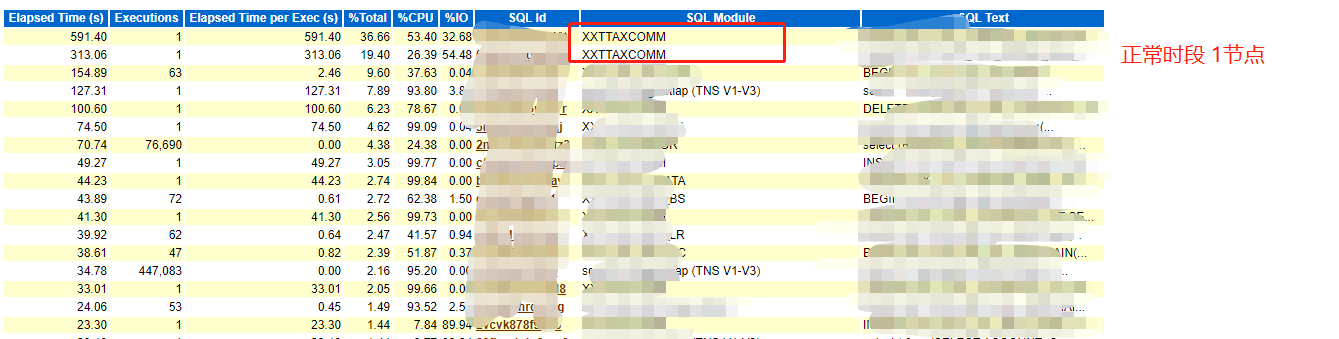
- 异常时段

5、结论
由于本次跑批任务,由于某种原因,在2节点执行,所以导致跑批较慢???
如果只给客户一个这样的回复,相信是没有说服力,毕竟是RAC环境,数据是一样,为什么在2节点,就会变慢,且看下面分析。
问题深入分析
1、异常时段AWR等待事件
通过分析异常时段AWR,可以发现,在1、2节点,均有大量的GC相关的等待事件,gc buffer busy acquire、gc buffer busy release、gc cr block busy等,而正常时段也有类似的等待事件,但远远没有异常时段的严重。
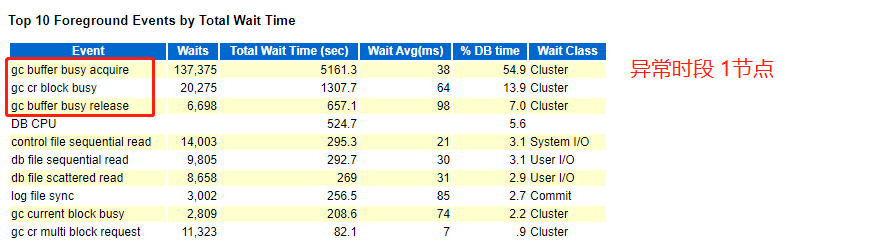
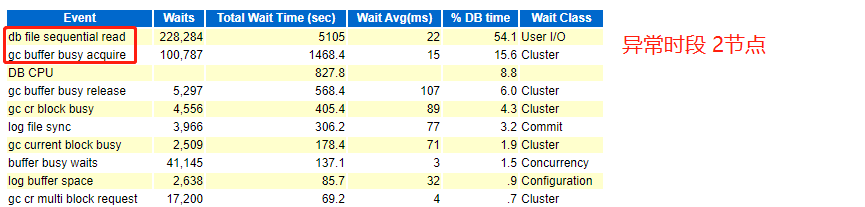
关于GC,在网上都有比较详细的说明,我们在此简单提下,在RAC环境,有Cache Fusion(内存融合)机制,可以实现多节点的缓存数据共享,如果比较频繁,就会有大量的GC相关等待事件,类似今天处理的故障AWR中一样,说白了就是跨节点访问内存数据,针对本案例,此事件的发生是比较正常,因为平时数据都缓存在1节点,突然在2节点执行任务,就会有过多的GC,而GC的处理方法,基本都是分割应用,或者分割表,尽量避免频繁的多节点数据访问。
问题总结
对于本案例中,问题的本源比较容易发现,这也依赖前期与客户沟通的结果,提前预知跑批任务主要在1节点,给接下来的问题分析带来了极大的帮助,另外客户同时提供正常和异常时段的报告,也有助于进行的事件对比,所以,我们在以后的问题处理中,可遵循以下几点。
- 事先和客户沟通故障情况(本次沟通结果,正常时段1节点执行 20分钟完成,异常时段2个小时)
- 故障前是否有变更操作(本次沟通结果,无此步,但应该是其他原因造成的跑批任务漂移)
- 采取正常和异常对比快速定位(本次客户直接提供正常和异常的AWR)
- 交付客户结果(本次案例,通过定位在节点2执行,产生大量GC)
当然,处理问题的方式不是一成不变,针对不同情况还需不同对待,但整体先后流程不能少,比如一上去就敲键盘的工程师是不可能真正处理问题。