背景
客户最近有这样的需求,想通过统计Oracle数据库活跃会话数,并记录在案,利用比对历史的活跃会话的方式,实现对系统整体用户并发量有大概的预估。
功能分析
客户现场有不少Oracle数据库,如果每一套都进行查询,效率太慢,而且数据也不能保留,所以需要通过脚本批量查询的方式实现。具体功能要点如下:
- 编写统计会话的SQL脚本
- 通过shell 批量管理众多Oracle实例,for实现
- 输出每次查询的记录留存,根据实例分别保存
- 在有一次初始数据之后,以后的每天查出增量数据
- 众多Oracle实例统计完成之后,统一输出到一个文件便于查看
具体实现
统计会话SQL脚本
根据客户要求,统计活跃会话数,一天运行一次即可,没必要实时数据,数据可以从数据库V$SESSION,V$ACTIVE_SESSION_HISTORY,DBA_HIST_ACTIVE_SESS_HISTORY三个视图中获取,V$SESSION视图为当前实时活跃会话信息(内存中保存,实时信息),V$ACTIVE_SESSION_HISTORY视图为1s从V$SESSION获取的活跃会话信息(内存中保存,保存时长依赖内存ash_buffers参数),DBA_HIST_ACTIVE_SESS_HISTORY视图每10s从V$ACTIVE_SESSION_HISTORY视图中获取一份(持久化保存,一般为7天),经过以上分析,SQL所需数据理应通过DBA_HIST_ACTIVE_SESS_HISTORY视图获取。
以下是具体的SQL查询语句,参考redo log切换统计语句格式。
prompt
prompt Session cnt
prompt ~~~~~~~~~~~~~~~~
set linesize 200
set pages 2000
col 00 for 9999
col 01 for 9999
col 02 for 9999
col 03 for 9999
col 04 for 9999
col 05 for 9999
col 06 for 9999
col 07 for 9999
col 08 for 9999
col 09 for 9999
col 10 for 9999
col 11 for 9999
col 12 for 9999
col 13 for 9999
col 14 for 9999
col 15 for 9999
col 16 for 9999
col 17 for 9999
col 18 for 9999
col 19 for 9999
col 20 for 9999
col 21 for 9999
col 22 for 9999
col 23 for 9999
select INST_ID,
a.ttime,
sum(c0) "00",
sum(c1) "01",
sum(c2) "02",
sum(c3) "03",
sum(c4) "04",
sum(c5) "05",
sum(c6) "06",
sum(c7) "07",
sum(c8) "08",
sum(c9) "09",
sum(c10) "10",
sum(c11) "11",
sum(c12) "12",
sum(c13) "13",
sum(c14) "14",
sum(c15) "15",
sum(c16) "16",
sum(c17) "17",
sum(c18) "18",
sum(c19) "19",
sum(c20) "20",
sum(c21) "21",
sum(c22) "22",
sum(c23) "23"
from (select INST_ID,
ttime,
decode(tthour, '00', c_cnt, 0) c0,
decode(tthour, '01', c_cnt, 0) c1,
decode(tthour, '02', c_cnt, 0) c2,
decode(tthour, '03', c_cnt, 0) c3,
decode(tthour, '04', c_cnt, 0) c4,
decode(tthour, '05', c_cnt, 0) c5,
decode(tthour, '06', c_cnt, 0) c6,
decode(tthour, '07', c_cnt, 0) c7,
decode(tthour, '08', c_cnt, 0) c8,
decode(tthour, '09', c_cnt, 0) c9,
decode(tthour, '10', c_cnt, 0) c10,
decode(tthour, '11', c_cnt, 0) c11,
decode(tthour, '12', c_cnt, 0) c12,
decode(tthour, '13', c_cnt, 0) c13,
decode(tthour, '14', c_cnt, 0) c14,
decode(tthour, '15', c_cnt, 0) c15,
decode(tthour, '16', c_cnt, 0) c16,
decode(tthour, '17', c_cnt, 0) c17,
decode(tthour, '18', c_cnt, 0) c18,
decode(tthour, '19', c_cnt, 0) c19,
decode(tthour, '20', c_cnt, 0) c20,
decode(tthour, '21', c_cnt, 0) c21,
decode(tthour, '22', c_cnt, 0) c22,
decode(tthour, '23', c_cnt, 0) c23
from (select instance_number INST_ID,
to_char(sample_time, 'YYYY-MM-DD') ttime,
to_char(sample_time, 'HH24') tthour,
count(1) c_cnt
from dba_hist_active_sess_history
where sample_time >= trunc(sysdate) - 7
and sample_time < trunc(sysdate) - 1
group by instance_number,
to_char(sample_time, 'YYYY-MM-DD'),
to_char(sample_time, 'HH24'))) a
group by INST_ID, ttime
order by ttime desc;
语句执行完成之后,效果如下
批量Oracle实例 for实现
根据客户现场环境,有多台服务器,每套服务器上部署多个实例,为了避免重复的代码,此处大概需要2个嵌套for循环,外层负责服务器,内存负责实例,外层实现逻辑如下:
function Startmain
{
#machines=(Xx)
machines=(Xx Xx Xx xX Xx)
v_flag=$1
for i in ${!machines[*]}
do
local v_machine="${machines[$i]}"
if [[ $v_machine == "Xx" ]];then
v_args=("XXX,1521" "XXX,1521" "XXX,1521" "XXX,1521" "XXX,1521" "XXX,1521" "XXX,1521" "XXX,1521")
v_ip="xxx.xxx.xxx.xxx"
elif [[ $v_machine == "Xx" ]];then
v_args=("XXX,1521" "XXX,1521" "XXX,1521" "XXX,1521" "XXX,1521" "XXX,1521")
v_ip="xxx.xxx.xxx.xxx"
elif [[ $v_machine == "Xx" ]];then
v_args=("XXX,1521" "XXX,1521" "XXX,1521" "XXX,1521" "XXX,1521" "XXX,1521")
v_ip="xxx.xxx.xxx.xxx"
elif [[ $v_machine == "xx" ]];then
v_args=("XXX,1521" "XXX,1521" "XXX,1521" "XXX,1521" "XXX,1521" "XXX,1521" "XXX,1521" "XXX,1521" "XXX,1521" "xxxx,1527")
v_ip="xxx.xxx.xxx.xxx"
elif [[ $v_machine == "Xx" ]];then
v_args=("XXX,1521" "XXX,1521" "xxxx,1526")
v_ip="xxx.xxx.xxx.xxx"
else
echo "Error"
fi
echo "$v_machine------------------------------------"|tee -a $newfilename
GetSesscnt $v_machine "${v_args[*]}" $v_ip $v_flag
done
}
外层for通过调用GetSesscnt函数,实现对服务器内部实例的解析,(注:在增量查询之后调用了日志转存函数,把数据统一输出到一个文件)内层实现逻辑如下:
function GetSesscnt
{
if [[ $# -ne 4 ]];then
echo "GetSesscnt XX (XXX XXX XXX XXX XXX) xxx.xxx.xxx.xxx flag"
fi
machine=$1
args=($2)
s_ip=$3
v_flag=$4
for i in ${!args[*]}
do
local v_arg="${args[$i]}"
v_name=${v_arg%,*}
v_port=${v_arg#*,}
recho "$machine $v_name start.." |tee -a $newfilename
if [[ $v_flag == "incr" ]];then
$ORACLE_HOME/bin/sqlplus -S "system/password@$s_ip:$v_port/$v_name" <<EOF > $pathpwd/$1_$v_name
@$pathpwd/sessioncntincr.sql
exit;
EOF
LogConvert $pathpwd $1_$v_name
else
$ORACLE_HOME/bin/sqlplus -S "system/password@$s_ip:$v_port/$v_name" <<EOF > $pathpwd/$1_$v_name".log"
@$pathpwd/sessioncntinit.sql
exit;
EOF
fi
recho "$machine $v_name end"|tee -a $newfilename
done
}
上述shell脚本中,同时包含了对不同服务器不同实例的结果留存,根据传输的是增量还是全量参数,实现对不同数据的生成保存,全量数据为.log后缀,增量数据没有log后缀保存记录如下
全量数据格式如下:
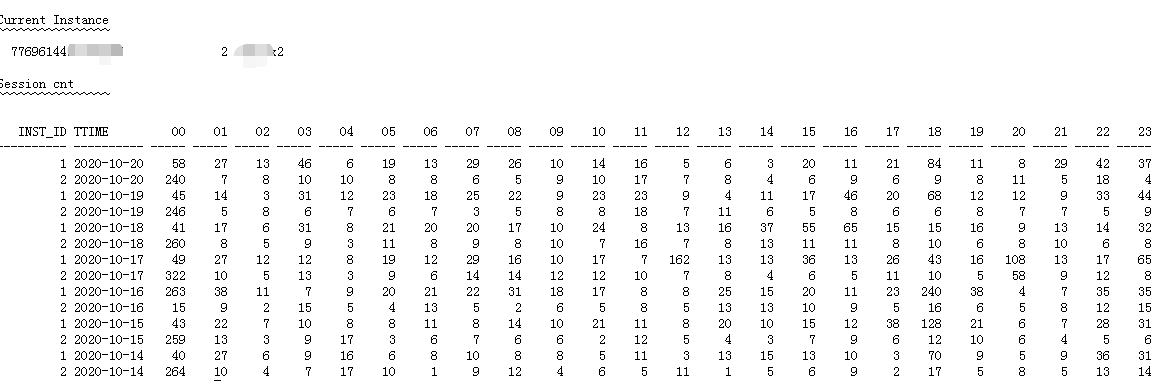
增量数据格式如下:

数据统一汇总
通过以上2步基本把所需的数据全部查询出来,有全量数据之后,每天跑增量即可,剩下工作就把每天跑的增量数据结合全量数据汇总和,统一输出到一个文件中,实现代码如下:
function LogConvert
{
v_log_path=$1
v_log_name=$2
grep -v '^$' $v_log_path/$v_log_name > $v_log_path/log_temp
v_date=(`cat $v_log_path/log_temp | awk '{print $2}'`)
v_cnt=(`grep $v_date $v_log_path/$v_log_name".log"|wc -l`)
if [[ $v_cnt == 0 ]]; then
sed -i "10 r $v_log_path/log_temp" $v_log_path/$v_log_name".log"
fi
head -40 $v_log_path/$v_log_name".log" >> $newfilename
}
至此,session 统计脚本工作完成,文章中只罗列了部分代码实现逻辑。