参考:https://blog.csdn.net/p812438109/article/details/81807440
1、Document介绍。
答:API来源:在JDK中javax.xml.*包下。
2、Document使用场景:
1)、需要知道XML文档所有结构。
2)、需要把文档一些元素排序。
3)、文档中的信息被多次使用的情况。
3、Document的优势和缺点:
1)、优势:由于Document是java中自带的解析器,兼容性强。
2)、缺点:由于Document是一次性加载文档信息,如果文档太大,加载耗时长,不太适用。
4、Document生成XML,步骤如下所示:
1 package com.demo.utils; 2 3 import java.io.File; 4 5 import javax.xml.parsers.DocumentBuilder; 6 import javax.xml.parsers.DocumentBuilderFactory; 7 import javax.xml.parsers.ParserConfigurationException; 8 import javax.xml.transform.OutputKeys; 9 import javax.xml.transform.Transformer; 10 import javax.xml.transform.TransformerConfigurationException; 11 import javax.xml.transform.TransformerException; 12 import javax.xml.transform.TransformerFactory; 13 import javax.xml.transform.dom.DOMSource; 14 import javax.xml.transform.stream.StreamResult; 15 16 import org.w3c.dom.Document; 17 import org.w3c.dom.Element; 18 19 /** 20 * Document生成XML 21 * 22 * @author 23 * 24 */ 25 public class CreateDocument { 26 27 public static void main(String[] args) { 28 // 执行Document生成XML方法 29 createDocument(new File("E:\person.xml")); 30 } 31 32 public static void createDocument(File file) { 33 try { 34 // 第一步:初始化一个XML解析工厂。 35 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); 36 37 // 第二步:创建一个DocumentBuilder实例。 38 DocumentBuilder builder = factory.newDocumentBuilder(); 39 40 // 第三步:构建一个Document实例。 41 Document doc = builder.newDocument(); 42 // standalone用来表示该文件是否呼叫其它外部的文件。若值是 "yes"表示没有呼叫外部文件 43 doc.setXmlStandalone(true); 44 45 // 第四步:创建一个根节点,名称为root,并设置一些基本属性。 46 // 创建一个根节点 47 // 说明: doc.createElement("元素名")、 48 // element.setAttribute("属性名","属性值")、设置节点属性 49 // element.setTextContent("标签间的内容"),设置标签之间的内容 50 Element element = doc.createElement("root"); 51 element.setAttribute("attr", "root"); 52 53 // 创建根节点第一个子节点 54 Element elementChildOne = doc.createElement("userInfo"); 55 elementChildOne.setAttribute("attr", "userInfo1"); 56 element.appendChild(elementChildOne); 57 58 // 第一个子节点的第一个子节点 59 Element childOneOne = doc.createElement("zhangsansan"); 60 childOneOne.setAttribute("attr", "userInfo1"); 61 childOneOne.setTextContent("attr zhangsansan"); 62 elementChildOne.appendChild(childOneOne); 63 64 // 第一个子节点的第二个子节点 65 Element childOneTwo = doc.createElement("lisisi"); 66 childOneTwo.setAttribute("attr", "userInfo1"); 67 childOneTwo.setTextContent("attr lisisi"); 68 elementChildOne.appendChild(childOneTwo); 69 70 // 创建根节点第二个子节点 71 Element elementChildTwo = doc.createElement("userInfo"); 72 elementChildTwo.setAttribute("attr", "userInfo2"); 73 element.appendChild(elementChildTwo); 74 75 // 第二个子节点的第一个子节点 76 Element childTwoOne = doc.createElement("lisisi"); 77 childTwoOne.setAttribute("attr", "userInfo2"); 78 childTwoOne.setTextContent("attr lisisi"); 79 elementChildTwo.appendChild(childTwoOne); 80 81 // 第二个子节点的第二个子节点 82 Element childTwoTwo = doc.createElement("wangwuwu"); 83 childTwoTwo.setAttribute("attr", "userInfo2"); 84 childTwoTwo.setTextContent("attr wangwuwu"); 85 elementChildTwo.appendChild(childTwoTwo); 86 87 // 第五步:把节点添加到Document中,再创建一些子节点加入,添加根节点 88 doc.appendChild(element); 89 90 // 第六步:把构造的XML结构,写入到具体的文件中 91 // 把构造的XML结构,写入到具体的文件中 92 TransformerFactory formerFactory = TransformerFactory.newInstance(); 93 Transformer transformer = formerFactory.newTransformer(); 94 // 换行 95 transformer.setOutputProperty(OutputKeys.INDENT, "YES"); 96 // 文档字符编码 97 transformer.setOutputProperty(OutputKeys.ENCODING, "utf-8"); 98 99 // 可随意指定文件的后缀,效果一样,但xml比较好解析,比如: E:\person.txt等 100 transformer.transform(new DOMSource(doc), new StreamResult(file)); 101 102 System.out.println("XML CreateDocument success!"); 103 } catch (ParserConfigurationException e) { 104 e.printStackTrace(); 105 } catch (TransformerConfigurationException e) { 106 e.printStackTrace(); 107 } catch (TransformerException e) { 108 e.printStackTrace(); 109 } 110 } 111 112 }
演示效果,如果是实际业务,可能要结合具体的业务进行分析,随时这东西,不常用吧,但是遇到了还是得会处理这种业务和需求的,如下所示:
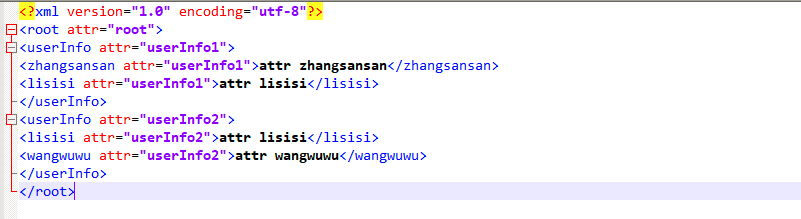
5、Document解析XML,步骤如下所示:
1 package com.demo.utils; 2 3 import java.io.File; 4 import java.io.IOException; 5 6 import javax.xml.parsers.DocumentBuilder; 7 import javax.xml.parsers.DocumentBuilderFactory; 8 import javax.xml.parsers.ParserConfigurationException; 9 10 import org.w3c.dom.Attr; 11 import org.w3c.dom.Document; 12 import org.w3c.dom.Element; 13 import org.w3c.dom.NamedNodeMap; 14 import org.w3c.dom.Node; 15 import org.w3c.dom.NodeList; 16 import org.xml.sax.SAXException; 17 18 /** 19 * 20 * @author Document解析XML 21 * 22 */ 23 public class ParseDocument { 24 25 public static void main(String[] args) { 26 File file = new File("E:\person.xml"); 27 if (!file.exists()) { 28 System.out.println("xml文件不存在,请确认!"); 29 } else { 30 // 第一步:先获取需要解析的文件,判断文件是否已经存在或有效 31 parseDocument(file); 32 } 33 } 34 35 public static void parseDocument(File file) { 36 try { 37 // 第二步:初始化一个XML解析工厂 38 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); 39 40 // 第三步:创建一个DocumentBuilder实例 41 DocumentBuilder builder = factory.newDocumentBuilder(); 42 43 // 第四步:创建一个解析XML的Document实例 44 Document doc = builder.parse(file); 45 46 // 第五步:先获取根节点的信息,然后根据根节点递归一层层解析XML 47 // 获取根节点名称 48 String rootName = doc.getDocumentElement().getTagName(); 49 System.out.println("根节点: " + rootName); 50 51 System.out.println("递归解析--------------begin------------------"); 52 // 递归解析Element 53 Element element = doc.getDocumentElement(); 54 parseElement(element); 55 System.out.println("递归解析--------------end------------------"); 56 } catch (ParserConfigurationException e) { 57 e.printStackTrace(); 58 } catch (SAXException e) { 59 e.printStackTrace(); 60 } catch (IOException e) { 61 e.printStackTrace(); 62 } 63 } 64 65 // 递归方法 66 public static void parseElement(Element element) { 67 System.out.print("<" + element.getTagName()); 68 NamedNodeMap attris = element.getAttributes(); 69 for (int i = 0; i < attris.getLength(); i++) { 70 Attr attr = (Attr) attris.item(i); 71 System.out.print(" " + attr.getName() + "="" + attr.getValue() + """); 72 } 73 System.out.println(">"); 74 75 NodeList nodeList = element.getChildNodes(); 76 Node childNode; 77 for (int temp = 0; temp < nodeList.getLength(); temp++) { 78 childNode = nodeList.item(temp); 79 80 // 判断是否属于节点 81 if (childNode.getNodeType() == Node.ELEMENT_NODE) { 82 // 判断是否还有子节点 83 if (childNode.hasChildNodes()) { 84 parseElement((Element) childNode); 85 } else if (childNode.getNodeType() != Node.COMMENT_NODE) { 86 System.out.print(childNode.getTextContent()); 87 } 88 } 89 } 90 System.out.println("</" + element.getTagName() + ">"); 91 } 92 93 }
解析效果,如下所示:
1 根节点: root 2 递归解析--------------begin------------------ 3 <root attr="root"> 4 <userInfo attr="userInfo1"> 5 <zhangsansan attr="userInfo1"> 6 </zhangsansan> 7 <lisisi attr="userInfo1"> 8 </lisisi> 9 </userInfo> 10 <userInfo attr="userInfo2"> 11 <lisisi attr="userInfo2"> 12 </lisisi> 13 <wangwuwu attr="userInfo2"> 14 </wangwuwu> 15 </userInfo> 16 </root> 17 递归解析--------------end------------------