1 信息标记的三种方式:



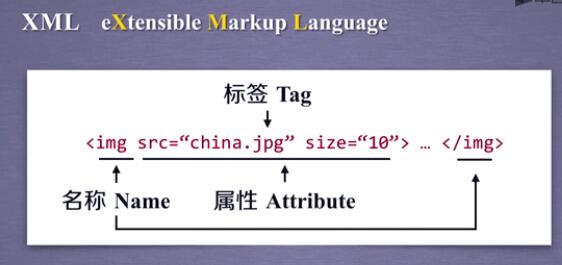
XML:


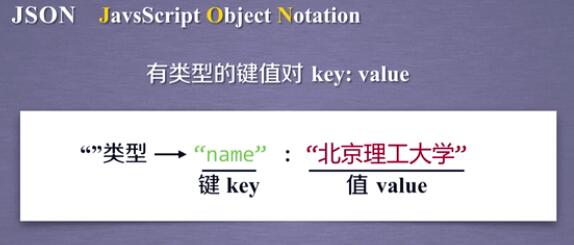
JSON:


YAML:


1 缩进 表示所属关系:

2 - 表示并列关系:

3 | 表示整块数据:


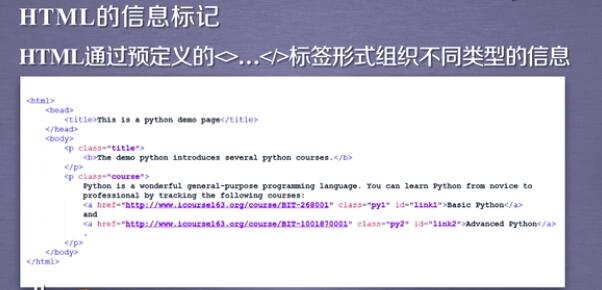
HTML----XML的一种形式:

2 信息提取的方法:
信息提取的方法 1 完整解析信息的标记形式,再提取关键信息---需要标记解析器 优点 信息解析准确 缺点 提取过程繁琐 速度慢 2 无视标记信息,直接搜索关键字 搜索===对文本查找函数即可 优点 信息解析速度快,过程简洁 缺点 提取准确性低


形式解析 + 正则(或者其他匹配规则)---融合方法

3 基于bs4库的HTML内容查找:
BeautifulSoup类的查找方法:
1 soup.find_all ( name,attrs,recursive,string,**kwargs )
from bs4 import BeautifulSoup import requests import re r=requests.get('http://www.baidu.com') demo=r.text[:1000] soup=BeautifulSoup(demo,'html.parser') # for tag in soup.find_all(id=re.compile('k')): # print(tag) print( soup.find_all('head') ) # 查找 head标签 # print(soup.find_all(re.compile('a')),len(soup.find_all(re.compile('b'))))


例子 大学排名
# <tr class="alt"> <td>9</td> <td><div align="left">南京大学</div></td> <td>江苏</td> <td>87.1 </td> </tr>
from bs4 import BeautifulSoup
import requests
def getHTMLText(url):
try:
r=requests.get(url)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
print('error!!')
def fillUniverList(ulist,html):
soup=BeautifulSoup(html,'html.parser')
for tr in soup.find('tbody').children:
if not isinstance(tr,str):
tds=tr.find_all('td')
ulist.append([tds[0].string,tds[1].string,tds[2].string])
def printUniverList(ulist,num):
print('{0:^10} {1:^10} {2:^10}'.format('排名','学校名称','总分'))
for i in range(num):
u=ulist[i]
print('{0:^10} {1:^10} {2:^10}'.format(u[0], u[1], u[2]))
def main():
ulist=[]
url='http://www.zuihaodaxue.cn/shengyuanzhiliangpaiming2017.html'
html=getHTMLText(url)
fillUniverList(ulist,html)
printUniverList(ulist,20) # 20 unis
main()
