停止之前使用的master、worker模式,使用yarn模式
停止
[root@ke01 sbin]# ./stop-all.sh [root@ke01 sbin]# ./stop-history-server.sh [root@ke02 sbin]# ./stop-master.sh
配置spark-env.sh
//删除其他配置,只用如下 [root@ke01 conf]# vi spark-env.sh export HADOOP_CONF_DIR=/opt/bigdata/hadoop-2.6.5/etc/hadoop
配置spark-defaults.conf
// 因为没有master worker了 所以也就没必要高可用了 [root@ke01 conf]# vi spark-defaults.conf # spark.deploy.recoveryMode ZOOKEEPER # spark.deploy.zookeeper.url ke02:2181,ke03:2181,ke04:2181 # spark.deploy.zookeeper.dir /kespark spark.eventLog.enabled true spark.eventLog.dir hdfs://mycluster/spark_log spark.history.fs.logDirectory hdfs://mycluster/spark_log
配置Hadoop的yarn相关
// yarn-site.xml增加 <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>4096</value> </property> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>4</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> // mapred-site.xml增加 <property> <name>mapred.job.history.server.embedded</name> <value>true</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>ke03:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>ke03:50060</value> </property> <property> <name>mapreduce.jobhistory.intermediate-done-dir</name> <value>/work/mr_history_tmp</value> </property> <property> <name>mapreduce.jobhistory.done-dir</name> <value>/work/mr-history_done</value> </property>
启动
ke01: stop-yarn.sh start-yarn.sh
ke03、ke04: yarn-daemon.sh stop resourcemanager yarn-daemon.sh start resourcemanager
测试
// 先跑一个mr任务 看是否正常 目录:/opt/bigdata/hadoop-2.6.5/share/hadoop/mapreduce hadoop jar hadoop-mapreduce-examples-2.6.5.jar wordcount /sparktest/test.txt /20210215
MR启动有历史详细数据 可以调优就行对比
ke03:root@ke03 bigdata]# mr-jobhistory-daemon.sh start historyserver
启动spark
./spark-shell --master yarn
spark启动有历史详细数据
[root@ke04 sbin]# ./start-history-server.sh
结果:
1. 当开启spark,http://ke03:8088/页面application 状态一直是进行中,当关闭的时候状态才是SUCCEEDED 进度100%(client模式连接) 2.跑一个org.apache.spark.examples.SparkPi任务,是一个独立的MR任务,是资源层连接
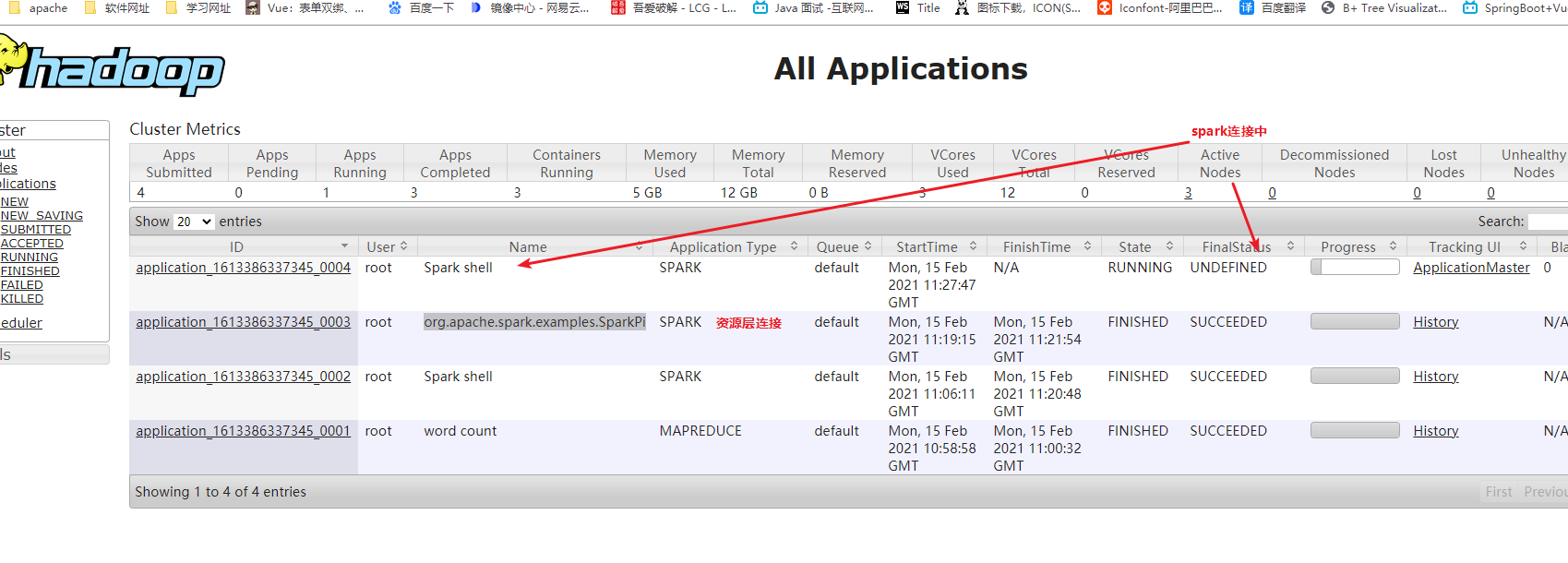
为什么spark-shell启动慢,如何优化
1.需要连接hadoop的yarn
2.需要拉取很多jar包
优化:
1.将hadoop目录下的所有jar包上传到hdfs hdfs dfs -put ./* /work/spark_lib/jars
2.spark-defaults.conf 文件增加
spark.yarn.jars hdfs://mycluster/work/spark_lib/jars/*
3. 启动spark: ./spark-shell --master yarn(日志中不在打印找不到spark.yarn.jars)
测试:
- spark-shell中
scala> sc.textFile("hdfs://mycluster/sparktest/test.txt").flatMap(x => x.split(" ")).map((_,1)).reduceByKey(_+_).collect().foreach(println) (hello,3) (msb,1) (world,1) (spark,2) (good,1) - 资源层测试
vi submit.sh class=org.apache.spark.examples.SparkPi jar=$SPARK_HOME/examples/jars/spark-examples_2.11-2.3.4.jar master=yarn $SPARK_HOME/bin/spark-submit --deploy-mode cluster --master $master --class $class $jar 1000 . submit.sh http://ke03:8088/ 可以点击History 查看历史日志