线性回归算法是一种有监督的算法。
聚类是一种无监督的机器学习任务,他可以自动将数据划分成类cluster.因此聚类分组不需要提前被告知所划分的组应该是什么样的。因为我们针织可能都不知道我们在寻找什么,所以聚类是用于知识发现而不是预测
KMeans聚类的原理以及聚类流程
- 随机找K个样本(中心点)
- 计算空间中所有的样本与这K个样本的距离
- 统计每一个样本与K个样本的距离大小,距离哪一个样本最近,那么这个样本就属于哪一类。
- 以上使用的是KNN思想(当k =1时满足)
- 分完类之后,每个组中重新计算一个新的中心点,中心点有可能不会坐落于某一个样本上,有可能是一个虚拟的点
- 再次计算空间中所有的样本与这K个中心点的距离
- 再次重新分类
- 一次迭代,一直到每个中心的点坐标不在发生改变(每一个中心点的坐标与上一个中心点的坐标不在发生改变)
问题1: 当数据量特别大怎么办?
- 可以随机抽样,使用抽样算法
问题2: 最开始随机找的K个中心点,如果距离很近怎么办?
- 距离近带来的问题:1.聚类效果很差,2.能比较好的聚类,但是迭代次数很高
- 使用KMeans++算法,是对KMeans算法一个升级,,主要升级的是在第一步选K个中心点,随机出来K个中心距离都比较远,不能集中在一起,思路:首先选第一个中心点C1,在选择距离比较远的C2,在选择比较远的C3等等
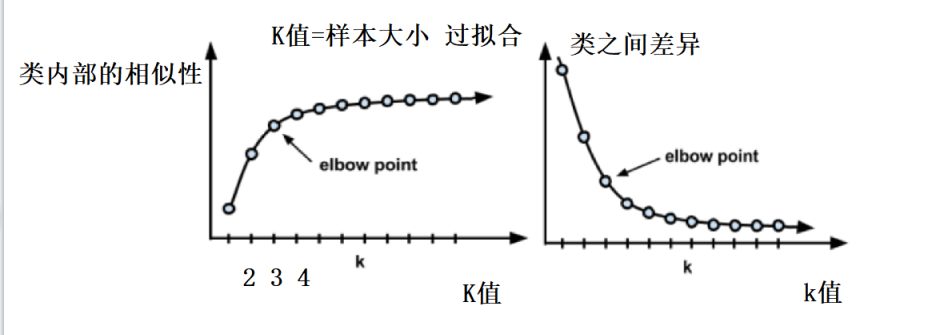
问题3: 聚类效果好不好?怎么衡量?标准是什么?
- 分类与分类之间的差异很大,但是类内部的相似性很高
问题4: K值怎么选择? 选几个?
- 肘部法 ,观看K值与分类内部的相似性,cos夹角越大,相似性变化越大,取变化相对最大的。
KMeans聚类代码
import numpy as np from sklearn.cluster import KMeans import matplotlib.pyplot as plt plt.figure(figsize=(12, 12)) def loadDataSet(fileName): dataMat = [] fr = open(fileName) for line in fr.readlines(): curLine = line.strip().split(' ') fltLine = list(map(float, curLine)) dataMat.append(fltLine) # 80 *2 的矩阵 return dataMat # 计算两点之间的距离 def distEclud(vecA, vecB): return np.sqrt(np.sum(np.power(vecA - vecB, 2))) # 生成key个中心点 def randCent(dataSet, key): # shape是80*2 n = 2 n = np.shape(dataSet)[1] ''' centroids是一个3*2的矩阵,用于存储三个中心点的坐标 生成key * n 的 0矩阵 ''' centroids = np.mat(np.zeros((key, n))) for j in range(n): minJ = np.min(dataSet[:, j]) rangeJ = np.max(dataSet[:, j]) - minJ # [:, j]纵向赋值, 第一次复制0列,第二次复制1列 centroids[:, j] = np.mat(minJ + rangeJ * np.random.rand(key, 1)) return centroids def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent): # m=80 m = np.shape(dataSet)[0] # clusterAssment是 80*2de 0矩阵, 存放所有的点到中心点的距离 clusterAssment = np.mat(np.zeros((m, 2))) # createCent找到K个随机中心点 centroids = createCent(dataSet, k) clusterChanged = True while clusterChanged: clusterChanged = False #循环80 次 for i in range(m): minDist = np.inf minIndex = -1 # 循环3次, 用数据上的点去和三个中心点比较,那个中心点最近,该点就是 minDist(离中心点最近的距离) minIndex(哪个中心点) for j in range(k): # 拿到中心的第j行 x = centroids[j, :] # 使用中心的第j行 和数据的第i行进行距离计算 distJI = distMeas(x, dataSet[i, :]) if distJI < minDist: minDist = distJI minIndex = j # 0矩阵的x值不等于 离中心点最近的距离, 跳出去的条件 if clusterAssment[i, 0] != minIndex: clusterChanged = True # 0矩阵赋值 x=中心点 y=离中心点最近的距离 clusterAssment[i, :] = minIndex, minDist for cent in range(k): # 0矩阵的所有x值 a = clusterAssment[:, 0].A # 选择矩阵上中心点=cent的值,也就是矩阵的下标, b是两个数组,b[0] = 矩阵下标 b[1] = cent b =np.nonzero(a == cent) # 根据矩阵下标取出改中心点的所有最近的点 ptsInClust = dataSet[b[0]] # 根据最近的点重新计算中心点,并将新的中心点赋值给centroids centroids[cent, :] = np.mean(ptsInClust, axis=0) return centroids, clusterAssment if __name__ == '__main__': dataMat = np.mat(loadDataSet('D:\code\python\test2\data\KMeans_testSet.txt')) k = 3 centroids, clusterAssment = kMeans(dataMat, k, distMeas=distEclud, createCent=randCent) # centroids 生成的3个中心点, clusterAssment是 80*2de 0矩阵, 存放所有的点到中心点的距离 0矩阵赋值 x=中心点 y=离中心点最近的距离 print(clusterAssment) print(centroids) dataMat = np.array(dataMat) y_pred1 = np.array([int(i) for j in clusterAssment[:, 0].A for i in j]) plt.subplot(224) plt.scatter(dataMat[:, 0], dataMat[:, 1], c=y_pred1) plt.title("kmeans04") plt.show()