说明:
Flink是一个有状态的流式计算引擎,所以会将中间计算结果(状态)进行保存,默认保存到TaskManager
的堆内存中,但是当task挂掉,那么这个task所对应的状态都会被清空,造成了数据丢失,无法保证结
果的正确性,哪怕想要得到正确结果,所有数据都要重新计算一遍,效率很低。想要保证At -least-
once和Exactly-once,需要把数据状态持久化到更安全的存储介质中,Flink提供了堆内内存、堆外内
存、HDFS、RocksDB等存储介质
Flink中状态分为两种类型
-
Keyed State
基于KeyedStream上的状态,这个状态是跟特定的Key绑定,KeyedStream流上的每一个Key都对 应一个State,每一个Operator可以启动多个Thread处理,但是相同Key的数据只能由同一个 Thread处理,因此一个Keyed状态只能存在于某一个Thread中,一个Thread会有多个Keyed state - Non-Keyed State(Operator State)
Operator State与Key无关,而是与Operator绑定,整个Operator只对应一个State。比如:Flink 中的Kafka Connector就使用了Operator State,它会在每个Connector实例中,保存该实例消费 Topic的所有(partition, offset)映射
Flink针对Keyed State提供了以下可以保存State的数据结构
-
ValueState:类型为T的单值状态,这个状态与对应的Key绑定,最简单的状态,通过update更新值,通过value获取状态值
-
ListState:Key上的状态值为一个列表,这个列表可以通过add方法往列表中添加值,也可以通过get()方法返回一个Iterable来遍历状态值
-
ReducingState:每次调用add()方法添加值的时候,会调用用户传入的reduceFunction,最后合并到一个单一的状态值
-
MapState<UK, UV>:状态值为一个Map,用户通过put或putAll方法添加元素,get(key)通过指定的key获取value,使用entries()、keys()、values()检索
-
AggregatingState <IN, OUT> :保留一个单值,表示添加到状态的所有值的聚合。和ReducingState 相反的是, 聚合类型可能与添加到状态的元素的类型不同。使用 add(IN) 添加的元素会调用用户指定的 AggregateFunction 进行聚合
-
FoldingState<T, ACC>:已过时建议使用AggregatingState 保留一个单值,表示添加到状态的所有值的聚合。 与 ReducingState 相反,聚合类型可能与添加到状态的元素类型不同。 使用add(T) 添加的元素会调用用户指定的 FoldFunction 折叠成聚合值
案例1:使用ValueState keyed state检查车辆是否发生了急加速
package com.text.state import org.apache.flink.api.common.functions.RichMapFunction import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor} import org.apache.flink.configuration.Configuration import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.streaming.api.scala._ case class CarInfo(carId: String, speed: Long) object ValueStateTest { def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment val stream = env.socketTextStream("ke01", 8888) stream.map(data => { val arr = data.split(" ") CarInfo(arr(0), arr(1).toLong) }).keyBy(_.carId) .map(new RichMapFunction[CarInfo, String] { //保存上一次车速 private var lastTempState: ValueState[Long] = _ override def open(parameters: Configuration): Unit = { val lastTempStateDesc = new ValueStateDescriptor[Long]("lastTempState", createTypeInformation[Long]) lastTempState = getRuntimeContext.getState(lastTempStateDesc) } override def map(value: CarInfo): String = { val lastSpeed = this.lastTempState.value() this.lastTempState.update(value.speed) if (lastSpeed != 0 && (value.speed - lastSpeed).abs > 30) { "over speed" + value.toString } else { value.carId } } }).print() env.execute() } }
案例2:使用MapState 统计单词出现次数 仅供大家理解MapState
package com.text.state import org.apache.flink.api.common.functions.RichMapFunction import org.apache.flink.api.common.state.{MapState, MapStateDescriptor} import org.apache.flink.configuration.Configuration import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.streaming.api.scala._ // 使用MapState 统计单词出现次数 object MapStateTest { def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment val stream = env.fromCollection(List("I love you", "hello spark", "hello flink", "hello hadoop")) val pairStream = stream.flatMap(_.split(" ")).map((_, 1)).keyBy(_._1) pairStream.map(new RichMapFunction[(String, Int), (String, Int)] { private var map: MapState[String, Int] = _ override def open(parameters: Configuration): Unit = { // 定义map state存储的数据类型 val desc = new MapStateDescriptor[String, Int]("sum", createTypeInformation[String], createTypeInformation[Int]) map = getRuntimeContext.getMapState(desc) } override def map(value: (String, Int)): (String, Int) = { val key = value._1 val v = value._2 if (map.contains(key)) { map.put(key, map.get(key) + 1) } else { map.put(key, 1) } val iterator = map.keys().iterator() while (iterator.hasNext) { val key = iterator.next() println("word:" + key + " count:" + map.get(key)) } value } }).setParallelism(3) env.execute() } }
案例3:使用ReducingState统计每辆车的速度总和
package com.text.state import org.apache.flink.api.common.functions.{ReduceFunction, RichMapFunction} import org.apache.flink.api.common.state.{ReducingState, ReducingStateDescriptor} import org.apache.flink.configuration.Configuration import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.streaming.api.scala._ case class CarInfo(carId: String, speed: Long) // 使用ReducingState统计每辆车的速度总和 object ReducingStateTest { def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment val stream = env.socketTextStream("ke01", 8899) stream.map(data => { val arr = data.split(" ") CarInfo(arr(0), arr(1).toLong) }).keyBy(_.carId) .map(new RichMapFunction[CarInfo, CarInfo] { private var reduceState: ReducingState[Long] = _ override def open(parameters: Configuration): Unit = { val reduceDesc = new ReducingStateDescriptor[Long]("reduceSpeed", new ReduceFunction[Long] { override def reduce(value1: Long, value2: Long): Long = value1 + value2 }, createTypeInformation[Long]) reduceState = getRuntimeContext.getReducingState(reduceDesc) } override def map(value: CarInfo): CarInfo = { reduceState.add(value.speed) println("carId:" + value.carId + " speed count:" + reduceState.get()) value } }) env.execute() } }
案例4:使用AggregatingState统计每辆车的速度总和
package com.text.state import org.apache.flink.api.common.functions.{AggregateFunction, RichMapFunction} import org.apache.flink.api.common.state.{AggregatingState, AggregatingStateDescriptor} import org.apache.flink.configuration.Configuration import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.streaming.api.scala._ //统计每辆车的速度总和 object AggregatingState { def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment val stream = env.socketTextStream("ke01", 8899) stream.map(data => { val arr = data.split(" ") CarInfo(arr(0), arr(1).toLong) }).keyBy(_.carId) .map(new RichMapFunction[CarInfo, CarInfo] { private var aggState: AggregatingState[Long, Long] = _ override def open(parameters: Configuration): Unit = { val aggDesc = new AggregatingStateDescriptor[Long, Long, Long]("agg", new AggregateFunction[Long, Long, Long] { // 初始化累加器值 override def createAccumulator(): Long = 0 // 往累加器中累加值 override def add(value: Long, accumulator: Long): Long = accumulator + value // 返回最终结果 override def getResult(accumulator: Long): Long = accumulator // 合并两个累加器值 override def merge(a: Long, b: Long): Long = a + b }, createTypeInformation[Long]) aggState = getRuntimeContext.getAggregatingState(aggDesc) } override def map(value: CarInfo): CarInfo = { aggState.add(value.speed) println("carId:" + value.carId + " speed count:" + aggState.get()) value } }) env.execute() } }
案例5:统计每辆车的运行轨迹 所谓运行轨迹就是这辆车的信息 按照时间排序,卡口号串联起来
package com.text.state import java.text.SimpleDateFormat import java.util.Properties import org.apache.flink.api.common.functions.RichMapFunction import org.apache.flink.api.common.serialization.SimpleStringSchema import org.apache.flink.api.common.state.{ListState, ListStateDescriptor} import org.apache.flink.configuration.Configuration import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer import org.apache.kafka.common.serialization.StringSerializer import org.apache.flink.streaming.api.scala._ import scala.collection.JavaConverters._ object ListStateTest { def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment val props = new Properties() props.setProperty("bootstrap.servers", "ke04:9092,ke02:9092,ke03:9092") props.setProperty("group.id", "group_id") props.setProperty("key.deserializer", classOf[StringSerializer].getName) props.setProperty("value.deserializer", classOf[StringSerializer].getName) val stream = env.addSource(new FlinkKafkaConsumer[String]("flink-kafka", new SimpleStringSchema(), props)) val format = new SimpleDateFormat("yyyy-MM-dd HH:mm:sss") stream.map(data => { val arr = data.split(" ") // 卡口、车牌、事件时间、车速 val time = format.parse(arr(2)).getTime (arr(0), arr(1), time, arr(3).toLong) }).keyBy(_._2) .map(new RichMapFunction[(String, String, Long, Long), (String, String)] { private var speedInfos: ListState[(Long, String)] = _ override def open(parameters: Configuration): Unit = { val listStateDesc = new ListStateDescriptor[(Long, String)]("speedInfos", createTypeInformation[(Long, String)]) speedInfos = getRuntimeContext.getListState(listStateDesc) } override def map(value: (String, String, Long, Long)): (String, String) = { speedInfos.add(value._3, value._1) val infos = speedInfos.get().asScala.seq val sortList = infos.toList.sortBy(x => x._1).reverse val builder = new StringBuilder for (elem <- sortList) { builder.append(elem._2 + " ") } (value._2, builder.toString()) } }).print() env.execute() } }
案例6:自系统启动以来,总共处理了多少条数据量
package com.text.state import org.apache.flink.api.common.functions.RichFlatMapFunction import org.apache.flink.api.common.state.{ListState, ListStateDescriptor} import org.apache.flink.runtime.state.{FunctionInitializationContext, FunctionSnapshotContext} import org.apache.flink.streaming.api.checkpoint.CheckpointedFunction import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.streaming.api.scala._ import org.apache.flink.util.Collector import scala.collection.JavaConverters._ object FlatMapOperatorStateTest { def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment val stream = env.fromCollection(List("I love you", "hello spark", "hello flink", "hello hadoop")) val value = stream.map(data => { (data, 1) }).keyBy(_._1).flatMap(new MyFlatMapFunction()) env.execute() } } class MyFlatMapFunction extends RichFlatMapFunction[(String, Int), (String, Int, Int)] with CheckpointedFunction { private var operatorCount: Long = _ private var operatorState: ListState[Long] = _ override def flatMap(value: (String, Int), out: Collector[(String, Int, Int)]): Unit = { operatorCount += 1 val subtasks = getRuntimeContext.getTaskNameWithSubtasks println(subtasks + "==" + operatorState.get()) } // 进行checkpoint的时候,会被调用,然后持久化到远端 override def snapshotState(context: FunctionSnapshotContext): Unit = { operatorState.clear() operatorState.add(operatorCount) } // 初始化方法 override def initializeState(context: FunctionInitializationContext): Unit = { operatorState = context.getOperatorStateStore.getListState(new ListStateDescriptor[Long]("operateState", createTypeInformation[Long])) if (context.isRestored) { operatorCount = operatorState.get().asScala.sum println("operatorCount" + operatorCount) } } }
CheckPoint
说明:
Flink中基于异步轻量级的分布式快照技术提供了Checkpoint容错机制,分布式快照可以将同一时间点
Task/Operator的状态数据全局统一快照处理,包括上面提到的用户自定义使用的Keyed State和
Operator State,当未来程序出现问题,可以基于保存的快照容错
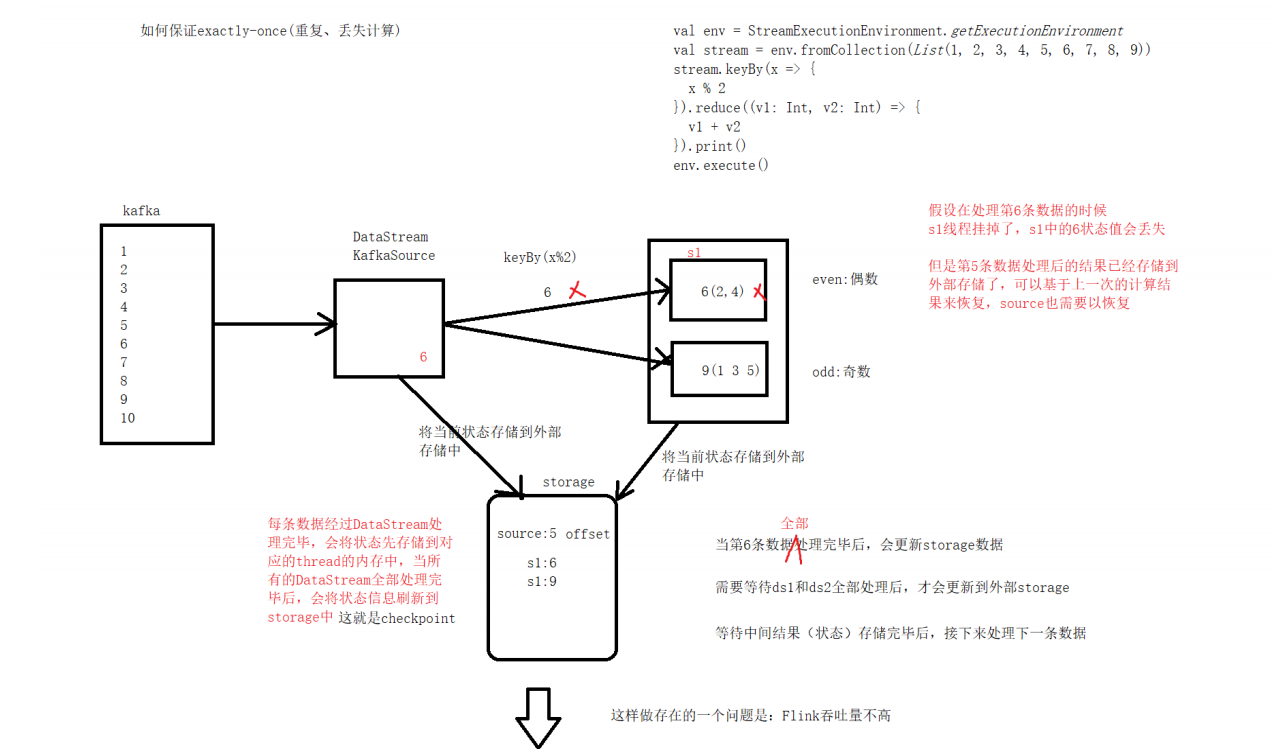
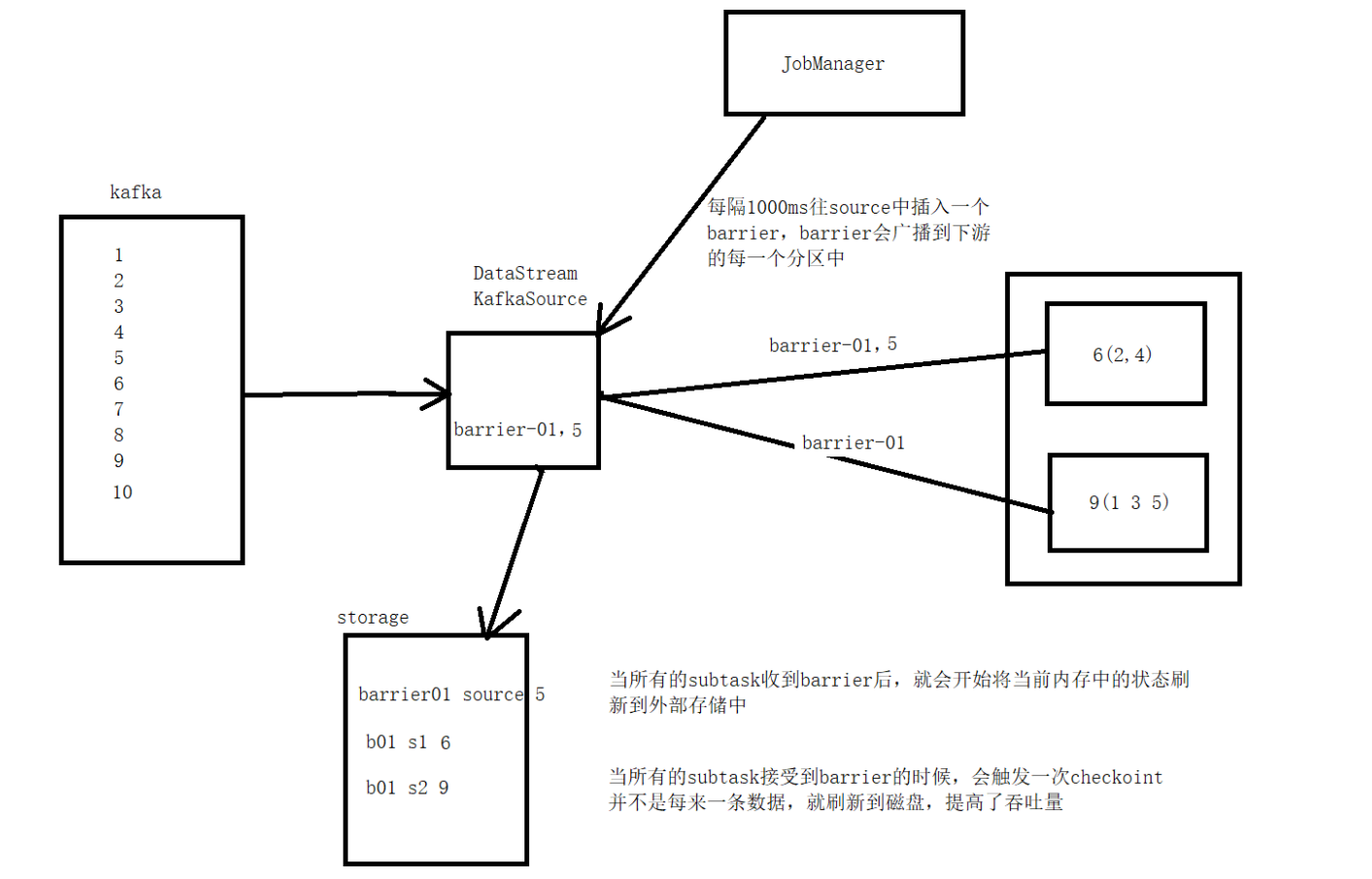
CheckPoint原理
Flink会在输入的数据集上间隔性地生成checkpoint barrier,通过栅栏(barrier)将间隔时间段内的数
据划分到相应的checkpoint中。当程序出现异常时,Operator就能够从上一次快照中恢复所有算子之
前的状态,从而保证数据的一致性。例如在KafkaConsumer算子中维护offffset状态,当系统出现问题无
法从Kafka中消费数据时,可以将offffset记录在状态中,当任务重新恢复时就能够从指定的偏移量开始消
费数据
流程图:
默认情况Flink不开启检查点,用户需要在程序中通过调用方法配置和开启检查点,另外还可以调整其他相关参数
1.Checkpoint开启和时间间隔指定 开启检查点并且指定检查点时间间隔为1000ms,根据实际情况自行选择,如果状态比较大,则建议适当增加该值 env.enableCheckpointing(1000) 2.exactly-ance和at-least-once语义选择 选择exactly-once语义保证整个应用内端到端的数据一致性,这种情况比较适合于数据要求比较高,不允许出现丢数据或者数据重复,与此同时,Flink的性能也相对较弱,而at-least-once语义更适合于时廷和吞吐量要求非常高但对数据的一致性要求不高的场景。通过 setCheckpointingMode()方法来设定语义模式,默认情况下使用的是exactly-once模式 env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE) 3.Checkpoint超时时间 超时时间指定了每次Checkpoint执行过程中的上限时间范围,一旦Checkpoint执行时间超过该阈值,Flink将会中断Checkpoint过程,并按照超时处理。该指标可以通过setCheckpointTimeout方法设定,默认为10分钟 env.getCheckpointConfig.setCheckpointTimeout(5 * 60 * 1000) 4.Checkpoint之间最小时间间隔 该参数主要目的是设定两个Checkpoint之间的最小时间间隔,防止Flink应用密集地触发Checkpoint操作,会占用了大量计算资源而影响到整个应用的性能 env.getCheckpointConfig.setMinPauseBetweenCheckpoints(600) 5.最大并行执行的Checkpoint数量 在默认情况下只有一个检查点可以运行,根据用户指定的数量可以同时触发多个Checkpoint,进而提升Checkpoint整体的效率 env.getCheckpointConfig.setMaxConcurrentCheckpoints(1) 6.任务取消后,是否删除Checkpoint中保存的数据 设置为RETAIN_ON_CANCELLATION:表示一旦Flink处理程序被cancel后,会保留CheckPoint数据,以便根据实际需要恢复到指定的CheckPoint 设置为DELETE_ON_CANCELLATION:表示一旦Flink处理程序被cancel后,会删除CheckPoint数据,只有Job执行失败的时候才会保存CheckPoint env.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpoint Cleanup.RETAIN_ON_CANCELLATION) 7.容忍的检查的失败数 设置可以容忍的检查的失败数,超过这个数量则系统自动关闭和停止任务 env.getCheckpointConfig.setTolerableCheckpointFailureNumber(1)
系统的升级关机 使用savepoint
1. 先savepoint flink savepoint 91708180bc440568f47ab0ec88087b43 hdfs://node01:9000/flink/sasa 2. cancel job flink cancel 91708180bc440568f47ab0ec88087b43 3. 重启job flink run -c com.msb.state.WordCountCheckpoint -s hdfs://node01:9000/flink/sasa/savepoint-917081-0a251a5323b7 StudyFlink- 1.0-SNAPSHOT.jar