
01 我们一起学大数据
老刘今天分享的是大数据Hadoop框架中的分布式计算MapReduce模块,MapReduce知识点有很多,大家需要耐心看,用心记,这次先分享出MapReduce的第一部分。老刘这次根据自学的资料分享出这些知识点,一是希望能够帮助对大数据感兴趣的同学,二是希望得到大佬的批评和指导。
02 MapReduce知识点
第1点:MapReduce的概念
MapReduce,它是一个分布式的计算框架,并且采用了一种分而治之的思想。从单词上就可以看出MapReduce由两个阶段组成:
Map阶段(把大任务切分成一个个小的任务)
Reduce阶段(汇总一个个小任务的结果)
那什么是分而治之呢?
比如一个复杂、计算量大、耗时长的的任务,暂且称为“大任务”;如果此时使用单台服务器无法计算或较短时间内计算没有出结果时,就可以将这个大任务切分成一个个小的任务,小任务可以分别在不同的服务器上并行执行,最终再汇总每个小任务的结果。
第2点:Map阶段的介绍
map阶段有一个关键的map()函数,这个map()函数的输入是(k,v)键值对,输出也是一系列的(k,v)键值对,最后将输出结果写入到本地磁盘。
第3点:Reduce阶段的介绍
reduce阶段有一个关键的reduce()函数,这个reduce()函数的输入也是键值对(也就是map输出的键值对),输出也是一系列(k,v)键值对,结果最后会写入HDFS中。
将第2点和第3点的介绍总结成一张图,如下:

第4点:MapReduce编程
讲完上述一些概念后,老刘当时处于似懂非懂的状态,于是就看了资料给出的编程实例,搞懂这个实例的原理和每行代码后,当时就感觉豁然开朗了,贼开心!
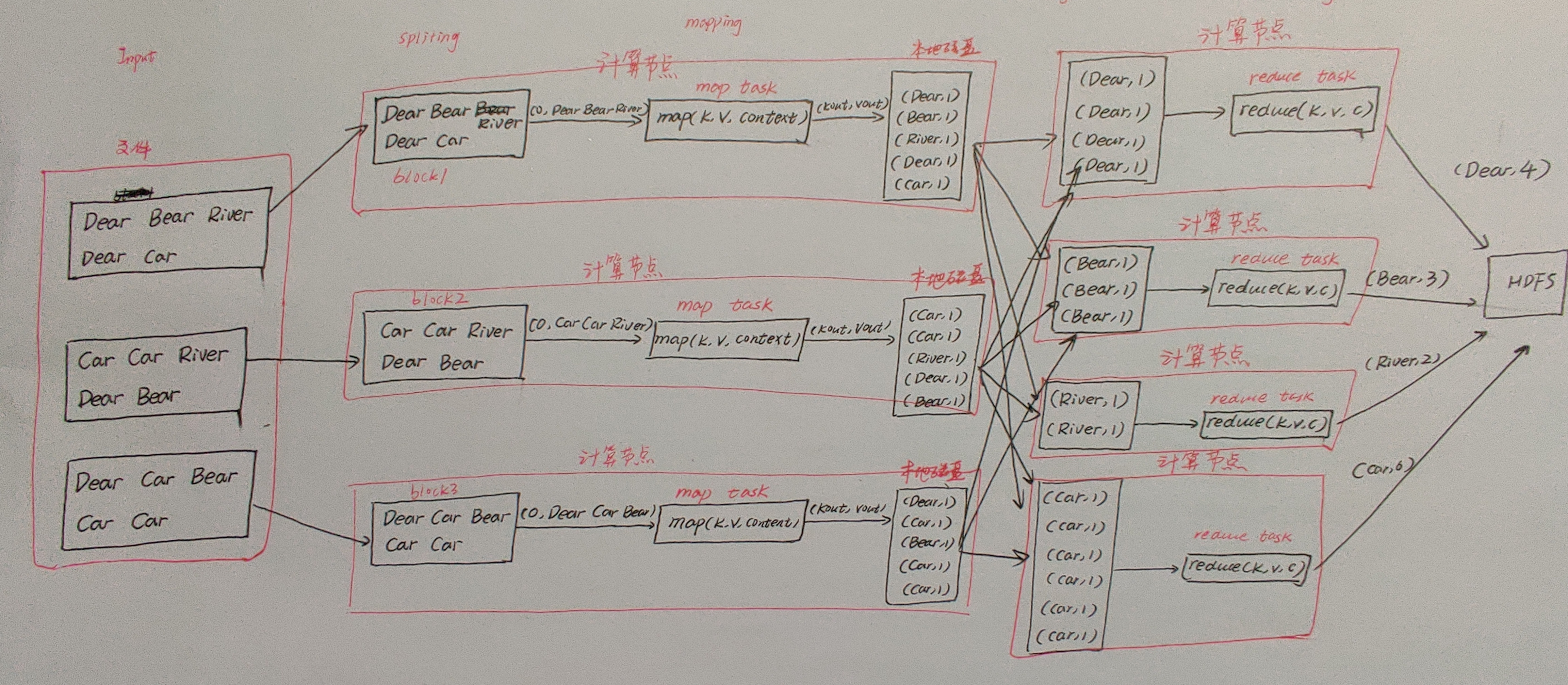
我们以MapReduce的词频统计为例:统计一批英文文章当中,每个单词出现的总次数。
MapReduce词频统计原理图
图片有点模糊,大家将就着看看,先分享出map端和reduce端的关键代码,完整代码分享在最后面。
在map端:
String line = value.toString(); //按照 进行分割,得到当前行所有单词 String[] words = line.split(" "); for (String word : words) { //将每个单词word变成键值对形式(word, 1)输出出去 //同样,输出前,要将kout, vout包装成对应的可序列化类型,如String对应Text,int对应IntWritable context.write(new Text(word), new IntWritable(1)); }
在reduce端:
//定义变量,用于累计当前单词出现的次数 int sum = 0; for (IntWritable count : values) { //从count中获得值,累加到sum中 sum += count.get(); } //将单词、单词次数,分别作为键值对,输出 context.write(key, new IntWritable(sum));// 输出最终结果
关于代码,老刘想说的是MapReduce中每个参数都要搞清楚!上面只是核心代码,虽然看起来很简单,但是还有很多细节,各种参数,都要仔细搞清楚!
接下来就来好好说说这个流程,
在Map阶段:
假设MR的输入文件有三个block:block1,block2,block3,每一个block对应一个split分片,每一个split对应一个map任务(map task)。
看上面这个图,一共有3个map任务(map1,map2,map3),这3个任务的逻辑大致上相同的,就直接讲讲第一个就行了。
map1读取block1的数据,一次读取block1的一行数据,将当前所读行的行首相对于当前block开始处的字节偏移量作为key(0),当前行的内容作为value。
然后键值对会作为map()的参数传入,调用map()。
在map()函数中,就会根据各种需求写代码,如果是单词统计,就会将value当前行的内容按照空格切分,得到三个单词Dear,Bear,River。
在将每个单词变成键值对,输出出去得到(Dear, 1) | (Bear, 1) | (River, 1)。
最终结果写入map任务所在节点的本地磁盘中(这里面还有很多细节,会涉及shuffle知识点,在这篇文章的后面会慢慢展开)。
block的第一行的数据被处理完后,接着处理第二行,原理和上面的一样。当map任务将当前block中所有的数据全部处理完后,此map任务即运行结束。
在Reduce阶段:
reduce任务(即reduce task)的个数由自己写的程序指定的,在main()内写job.setNumReduceTasks(4),就可以指定reduce任务是4个(reduce1、reduce2、reduce3、reduce4)。
每一个reduce任务的逻辑差不多,所以就拿第一个reduce任务做分析。
map1任务完成后,reduce1通过http网络,连接到map1,将map1输出结果中属于reduce1的分区的数据(采用的是默认哈希分区),通过网络获取到reduce1端,同样也是这样连接到map2、map3获取结果。
最终reduce1端获得4个(Dear, 1)键值对;由于他们的key键是相同的,它们分到同一组;这4个(Dear, 1)键值对,在转换成[Dear, Iterable(1, 1, 1, )],作为两个参数传入reduce()。
在reduce()内部,计算Dear的总数为4,并将(Dear, 4)作为键值对输出,每个reduce任务最终输出文件将写入到HDFS。这里也会涉及到shuffle。
大致就是这样的流程,代码写完后,生成Jar包,然后在Hadoop集群中运行。
讲完这个实例,老刘有句话说,MapReduce实例有很多很多,这只是其中一个,大家可以自己找找更多的实例,老刘继续分享出MapReduce编程:数据清洗,搜索用户次数两个例子的相关代码,放在最后,大家可以去看看。
第5点:shuffle
这是个重点,相当重要的重点。shuff主要指的是map端的输出作为reduce端输入的过程。它的中文意思是洗牌。
先给出它的细节图:

分区用到了分区器,默认分区器是HashPartitioner,代码如下:
public class HashPartitioner<K2, V2> implements Partitioner<K2, V2> { public void configure(JobConf job) {} /** Use {@link Object#hashCode()} to partition. */ public int getPartition(K2 key, V2 value, int numReduceTasks) { return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks; } }
接下来说说具体流程,
在map端:
1、每个map任务都有一个对应的环形内存缓冲区;输出的是kv对,先写入到环形缓冲区(默认大小100M),当内容占据80%缓冲区空间后,由一个后台线程将缓冲区中的数据溢出写到一个磁盘文件。
2、在溢出写的过程中,map任务继续向环形缓冲区写入数据;但是若写入速度大于溢出写的速度,最终造成100m占满后,map任务会暂停向环形缓冲区中写数据的过程;只执行溢出写的过程;直到环形缓冲区的数据全部溢出写到磁盘,才恢复向缓冲区写入。
3、后台线程溢写磁盘过程,有以下几个步骤:
① 先对每个溢写的kv对做分区;分区的个数由MR程序的reduce任务数决定;默认使用HashPartitioner计算当前kv对属于哪个分区;计算公式为(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks
② 每个分区中,根据kv对的key做内存中排序;
③ 若设置了map端本地聚合combiner,则对每个分区中,排好序的数据做combine操作;
④ 若设置了对map输出压缩的功能,会对溢写数据压缩;
注意:第二步中的排序,老刘看了很多资料上都没讲,就自行搜索了一些资料,该排序操作属于Hadoop的默认行为。任何应用程序中的数据均会被排序,而不管逻辑上是否需要。
排序分类有5个分类:部分排序、全排序、利用分区器实现全部排序、辅助排序、二次排序,具体概念就不阐述了,自行搜索吧!
4、随着不断的向环形缓冲区中写入数据,会多次触发溢写(每当环形缓冲区写满100m),本地磁盘最终会生成多个溢出文件。
5、在map task完成之前,所有溢出文件会被合并成一个大的溢出文件;并且是已分区、已排序的输出文件。
这里,有一些小细节,大家记一下:
在合并溢写文件时,如果至少有3个溢写文件,并且设置了map端combine的话,会在合并的过程中触发combine操作;
但是若只有2个或1个溢写文件,则不触发combine操作(因为combine操作,本质上是一个reduce,需要启动JVM虚拟机,有一定的开销)
在reduce端:
1、reduce task会在每个map task运行完成后,通过HTTP获得map task输出中,属于自己的分区数据(许多kv对)。
2、如果map输出数据比较小,先保存在reduce的jvm内存中,否则直接写入Reduce磁盘。
3、一旦内存缓冲区达到阈值(默认0.66)或map输出数的阈值(默认1000),则触发归并merge,结果写到本地磁盘。若MR编程指定了combine,在归并过程中会执行combine操作。
4、随着溢出写的文件的增多,后台线程会将它们合并大的、排好序的文件。
5、reduce task将所有map task复制完后,将合并磁盘上所有的溢出文件,默认一次合并10个,最后一批合并,部分数据来自内存,部分来自磁盘上的文件。
6、进入“归并、排序、分组阶段”
7、每组数据调用一次reduce方法
8、最后结果写入到HDFS
03 知识点总结
说实话,今天知识点有点多,刚开始学的时候,有一些东西确实很难理解,但是当你记住它的时候,对以后学习spark、flink真的特别有用,会发现这个模块的很多内容原理大致差不多,请一定要记住今天分享的内容。
最后要说的是MapReduce的编程实例都放在老刘的公众号了,大家感兴趣的可以去看看。
有事,联系公众号:努力的老刘;没事,和老刘一起学大数据。