【金三银四】缓存面试题-web层缓存
由于缓存的种类众多,不同场景的缓存也存在着一些不一样的特点。内容太多。本文仅限于Web应用层缓存
什么是缓存,为什么要用缓存?
速度问题
由于内存的读写速度要比磁盘的读写速度快一个数量级。
一般的ddr3代1333的速度读写在7000mb/s以上,
ssd硬盘读写大概500mb/s
如果是机械硬盘,或者其他存储设备,那读写速度可能会更低。
连接问题
假如公司网站首页有个接口。需要去数据库获取一些信息。(别和栗子较真)格式如下:
curl http://xxx.cn/homeInfo
#返回值
{
"pageName": "home",
"title": "XXXX",
"website": "http://www.xxxx.com/",
"companyName": "xxxx",
"employees": "103699人",
"desc": "XXXX网络技术有限公司(简称:XXXX集团或XXXX)是以曾担任英语教师的马某为首的18人于1999年在浙江省杭州市创立的公司"
}
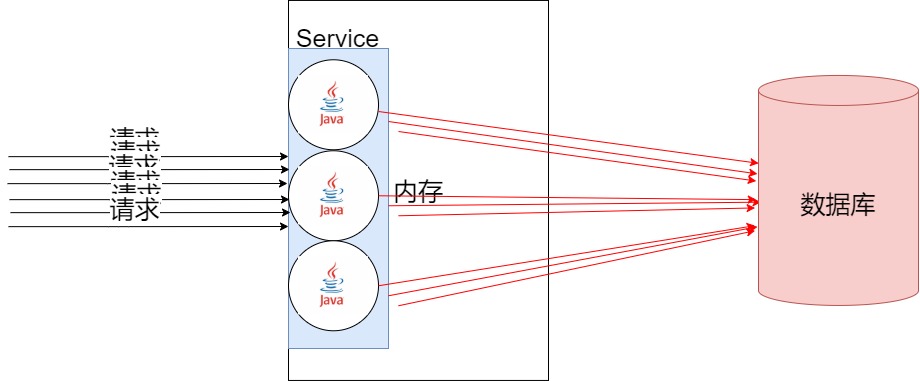
比如现在客户端有100万个用户打开了一个网站的。那么就会有100万个请求去读数据库。
这里会发现一个问题,就是我100万个人明明获取的数据都是同一份数据,但是我数据库要查100万次。
先不说数据库能不能抗的住这100万的请求。会发现这操作就很重复,很冗余,很低效。
基于上面两个问题。那么缓存就能很好的解决这两个问题。
缓存的主要任务就是为了减少数据库(硬盘)的读写次数。
没有缓存得请求方式
加了缓存的请求方式
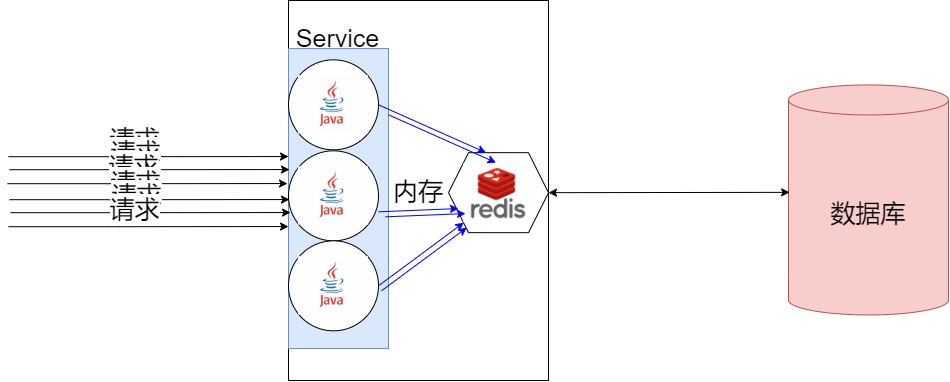
缓存的流程
请求到Java时,Java先从Redis中读取数据,如果读取到数据直接返回给前端。
如果读取不到则从数据库中读取,存入Redis中,并返回。当下次读取时redis就已经有数据了。不会再直接访问数据库了。
缓存数据一致性问题
数据库中的数据缓存在Redis之后。如果数据库数据发生修改。那么从缓存中读到的数据就会不正确。
所以为了保证缓存中的数据和数据库的数据保持一致。我们通常的做法是。
在数据库进行新增,修改,删除的时候。清楚redis中的缓存。这样当下次查询的时候,会重新读取数据库再缓存到Redis中。
缓存的三大坑
缓存穿透
- 缓存穿透是指查询的数据在数据库是没有的,那么在缓存中自然也没有,所以在缓存中查不到就会去数据库查询,这样的请求一多,我们数据库的压力自然会增大。
- 解决
对于返回为 NULL 的依然缓存,对于抛出异常的返回不进行缓存,注意不要把抛异常的也给缓存了
制定一些规则过滤一些不可能存在的数据,小数据用 BitMap,大数据可以用布隆过滤器
缓存击穿
- 对于某些 Key 设置了过期时间,但是它是热点数据,如果某个 Key 失效,可能大量的请求打过来,缓存未命中,然后去数据库访问,此时数据库访问量会急剧增加
- 解决
加分布式锁
异步加载,对这部分热点数据采取到期自动刷新的策略
缓存雪崩
- 缓存雪崩是指缓存不可用或者大量缓存由于超时时间相同在同一时间段失效,大量请求直接访问数据库,数据库压力过大导致系统雪崩。
- 解决
增加缓存系统可用性,通过监控关注缓存的健康程度,根据业务量适当的扩容缓存。
采用多级缓存,不同级别缓存设置的超时时间不同,即使某个级别缓存都过期,也有其他级别缓存兜底。
缓存的 Key 值可以取个随机值,比如以前是设置 10 分钟的超时时间,那每个 Key 都可以随机 8-13 分钟过期,尽量让不同 Key 的过期时间不同。
如图,当Redis出现问题的时候,多个JVM进程将使用从Map中获取缓存的数据。而不至于直接访问数据库。
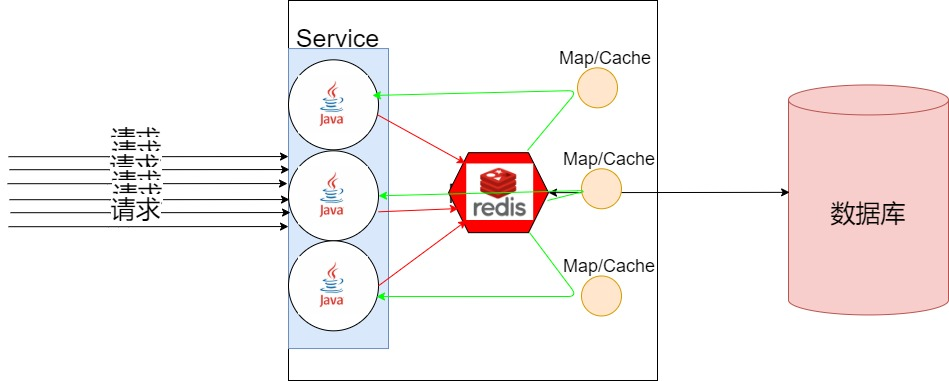
本地缓存
本地缓存可以简单的使用map或者一些第三方工具
如Guava的Cache,Hutool的Cache等。
这些工具类也都是继承了Map做了LRU缓存,失效时间缓存等功能。
其都是依赖于JVM进程的。
优点是:单个服务挂了,不会影响其他JVM进程。
缺点是:没有序列化,重启或者断电缓存数据丢失;
使用不恰当时,容易内存溢出;
总结
好的缓存系统因该让用户体验不到他的存在。而只享受它所带来的速度提升。
所以缓存一定要做好兼容。不要因为引入了缓存,导致系统不可用。那是得不偿失的。
选择适合自己的缓存方案。不一定所有的系统都需要缓存。下面列举一些简单的web应用缓存方案。
缓存方案
无缓存方式
在一些内部系统,甚至一些访问量及其小的网站。完全可以不用缓存。数据库的性能其实并没有那么不堪一击。
无依赖轻量级缓存
仅仅个别地方可能需要一些简单的缓存。那么可以直接在成员变量中使用Map(或ConcurrentHashMap)做简单的缓存。如果使用LRU缓存淘汰,或者失效缓存,可以简单引用一些第三方工具类,如Guava的Cache,Hutool的Cache等。
Redis缓存
Redis缓存也是根据自己的需要来使用。从单机Redis到高可用的Redis集群。
单机Redis比较简单,直接在一台服务器上安装一个Redis配置即可使用
高可用Redis有很多中方法。主从,哨兵,等。甚至可以买一些云服务的高可用Redis
由于Redis过于强大,使用方式也太多。这里不在一一说明。如有需要自行百度。
{
"author": "大火yzs",
"title": "【金三银四】缓存面试题-web层缓存",
"tag": "Redis,缓存,面试题",
"createTime": "2021-03-07 23:01"
}
本文由博客群发一文多发等运营工具平台 OpenWrite 发布