CPU和GPU内存交互
在CUDA编程中,内存拷贝是非常费时的一个动作.
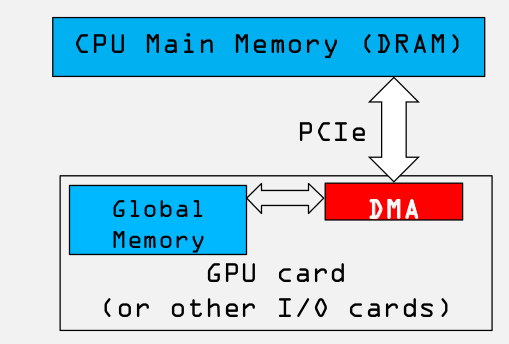
从上图我们可以看出:
1. CPU和GPU之间的总线bus是PCIe,是双向传输的.
2. CPU和GPU之间的数据拷贝使用DMA机制来实现,非常容易理解,为了更快的传输速度.
虚拟内存(virtual memory)
我们都知道,虽然在运行速度上硬盘不如内存,但在容量上内存是无法与硬盘相提并论的。当运行一个程序需要大量数据、占用大量内存时,内存就会被“塞满”,并将那些暂时不用的数据放到硬盘中,而这些数据所占的空间就是虚拟内存。
分页(英语:Paging),是一种操作系统里存储器管理的一种技术,可以使电脑的主存可以使用存储在辅助存储器中的数据。操作系统会将辅助存储器(通常是磁盘)中的数据分区成固定大小的区块,称为“页”(pages)。当不需要时,将分页由主存(通常是内存)移到辅助存储器;当需要时,再将数据取回,加载主存中。相对于分段,分页允许存储器存储于不连续的区块以维持文件系统的整齐。[1]分页是磁盘和内存间传输数据块的最小单位.
固定内存(pinned memory)
我们用cudaMalloc()为GPU分配内存,用malloc()为CPU分配内存.除此之外,CUDA还提供了自己独有的机制来分配host内存:cudaHostAlloc(). 这个函数和malloc的区别是什么呢?
malloc()分配的标准的,可分页的主机内存(上面有解释到),而cudaHostAlloc()分配的是页锁定的主机内存,也称作固定内存pinned memory,或者不可分页内存,它的一个重要特点是操作系统将不会对这块内存分页并交换到磁盘上,从而保证了内存始终驻留在物理内存中.也正因为如此,操作系统能够安全地使某个应用程序访问该内存的物理地址,因为这块内存将不会被破坏或者重新定位.
由于GPU知道内存的物理地址,因此就可以使用DMA技术来在GPU和CPU之间复制数据.当使用可分页的内存进行复制时(使用malloc),CUDA驱动程序仍会通过dram把数据传给GPU,这时复制操作会执行两遍,第一遍从可分页内存复制一块到临时的页锁定内存,第二遍是再从这个页锁定内存复制到GPU上.当从可分页内存中执行复制时,复制速度将受限制于PCIE总线的传输速度和系统前段速度相对较低的一方.在某些系统中,这些总线在带宽上有着巨大的差异,因此当在GPU和主机之间复制数据时,这种差异会使页锁定主机内存比标准可分页的性能要高大约2倍.即使PCIE的速度于前端总线的速度相等,由于可分页内训需要更多一次的CPU参与复制操作,也会带来额外的开销.
当我们在调用cudaMemcpy(dest, src, ...)时,程序会自动检测dest或者src是否为Pinned Memory,若不是,则会自动将其内容拷入一不可见的Pinned Memory中,然后再进行传输。可以手动指定Pinned Memory,对应的API为:cudaHostAlloc(address, size, option)分配地址,cudaFreeHost(pointer)释放地址。注意,所谓的Pinned Memory都是在Host端的,而不是Device端。
有的人看到这里,在写代码的过程中把所有的malloc都替换成cudaHostAlloc()这样也是不对的.
固定内存是一把双刃剑.当时使用固定内存时,虚拟内存的功能就会失去,尤其是,在应用程序中使用每个页锁定内存时都需要分配物理内存,而且这些内存不能交换到磁盘上.这将会导致系统内存会很快的被耗尽,因此应用程序在物理内存较少的机器上会运行失败,不仅如此,还会影响系统上其他应用程序的性能.
综上所述,建议针对cudaMemcpy()调用中的源内存或者目标内存,才使用页锁定内存,并且在不在使用他们的时候立即释放,而不是在应用程序关闭的时候才释放.我们使用下面的测试实例:
float cuda_malloc_test( int size, bool up ) { cudaEvent_t start, stop; int *a, *dev_a; float elapsedTime; HANDLE_ERROR( cudaEventCreate( &start ) ); HANDLE_ERROR( cudaEventCreate( &stop ) ); a = (int*)malloc( size * sizeof( *a ) ); HANDLE_NULL( a ); HANDLE_ERROR( cudaMalloc( (void**)&dev_a, size * sizeof( *dev_a ) ) ); HANDLE_ERROR( cudaEventRecord( start, 0 ) ); for (int i=0; i<100; i++) { if (up) HANDLE_ERROR( cudaMemcpy( dev_a, a,size * sizeof( *dev_a ),cudaMemcpyHostToDevice ) ); else HANDLE_ERROR( cudaMemcpy( a, dev_a,size * sizeof( *dev_a ),cudaMemcpyDeviceToHost ) ); } HANDLE_ERROR( cudaEventRecord( stop, 0 ) ); HANDLE_ERROR( cudaEventSynchronize( stop ) ); HANDLE_ERROR( cudaEventElapsedTime( &elapsedTime,start, stop ) ); free( a ); HANDLE_ERROR( cudaFree( dev_a ) ); HANDLE_ERROR( cudaEventDestroy( start ) ); HANDLE_ERROR( cudaEventDestroy( stop ) ); return elapsedTime; } float cuda_host_alloc_test( int size, bool up ) { cudaEvent_t start, stop;int *a, *dev_a; float elapsedTime; HANDLE_ERROR( cudaEventCreate( &start ) ); HANDLE_ERROR( cudaEventCreate( &stop ) ); HANDLE_ERROR( cudaHostAlloc( (void**)&a,size * sizeof( *a ),cudaHostAllocDefault ) ); HANDLE_ERROR( cudaMalloc( (void**)&dev_a,size * sizeof( *dev_a ) ) ); HANDLE_ERROR( cudaEventRecord( start, 0 ) ); for (int i=0; i<100; i++) { if (up) HANDLE_ERROR( cudaMemcpy( dev_a, a,size * sizeof( *a ),cudaMemcpyHostToDevice ) ); else HANDLE_ERROR( cudaMemcpy( a, dev_a,size * sizeof( *a ),cudaMemcpyDeviceToHost ) ); } HANDLE_ERROR( cudaEventRecord( stop, 0 ) ); HANDLE_ERROR( cudaEventSynchronize( stop ) ); HANDLE_ERROR( cudaEventElapsedTime( &elapsedTime,start, stop ) ); HANDLE_ERROR( cudaFreeHost( a ) ); HANDLE_ERROR( cudaFree( dev_a ) ); HANDLE_ERROR( cudaEventDestroy( start ) ); HANDLE_ERROR( cudaEventDestroy( stop ) ); return elapsedTime; }
Main 函数代码:
#include "../common/book.h" #define SIZE (10*1024*1024) int main( void ) { float elapsedTime; float MB = (float)100*SIZE*sizeof(int)/1024/1024; elapsedTime = cuda_malloc_test( SIZE, true ); printf( "Time using cudaMalloc:%3.1f ms ",elapsedTime ); printf( " MB/s during copy up:%3.1f ",MB/(elapsedTime/1000) ); elapsedTime = cuda_malloc_test( SIZE, false ); printf( "Time using cudaMalloc:%3.1f ms ",elapsedTime ); printf( " MB/s during copy down:%3.1f ",MB/(elapsedTime/1000) ); elapsedTime = cuda_host_alloc_test( SIZE, true ); printf( "Time using cudaHostAlloc:%3.1f ms ",elapsedTime ); printf( " MB/s during copy up:%3.1f ",MB/(elapsedTime/1000) ); elapsedTime = cuda_host_alloc_test( SIZE, false ); printf( "Time using cudaHostAlloc:%3.1f ms ",elapsedTime ); printf( " MB/s during copy down:%3.1f ",MB/(elapsedTime/1000) ); }
cuda_malloc_test()的参数up为true,因此前一次调用将测试从主机到设备的复制性能.false则测试相反方向设备到主机的性能.
同时也执行了相同的步骤来测试cudaHostAlloc()的性能,在GeForce GTX 285上,当使用固定内存而不是可分页内存时,从主机拷贝到设备的性能从2.77GB/s 提升到5.11GB/s.当从设备复制到主机时,性能从2.43GB/s提升到5.46GB/s.因此对于大多数PCIE宽带有限的应用程序,当使用固定内存而不是标准分页内存时,可以看到显著的性能提升.