Outline
前几天,数据清洗时有用到pandas去过滤大量数据中的“负值”;
把过滤出来的“负值”替换为“NaN”或者指定的值。
故做个小记录。
读取CSV文件
代码:
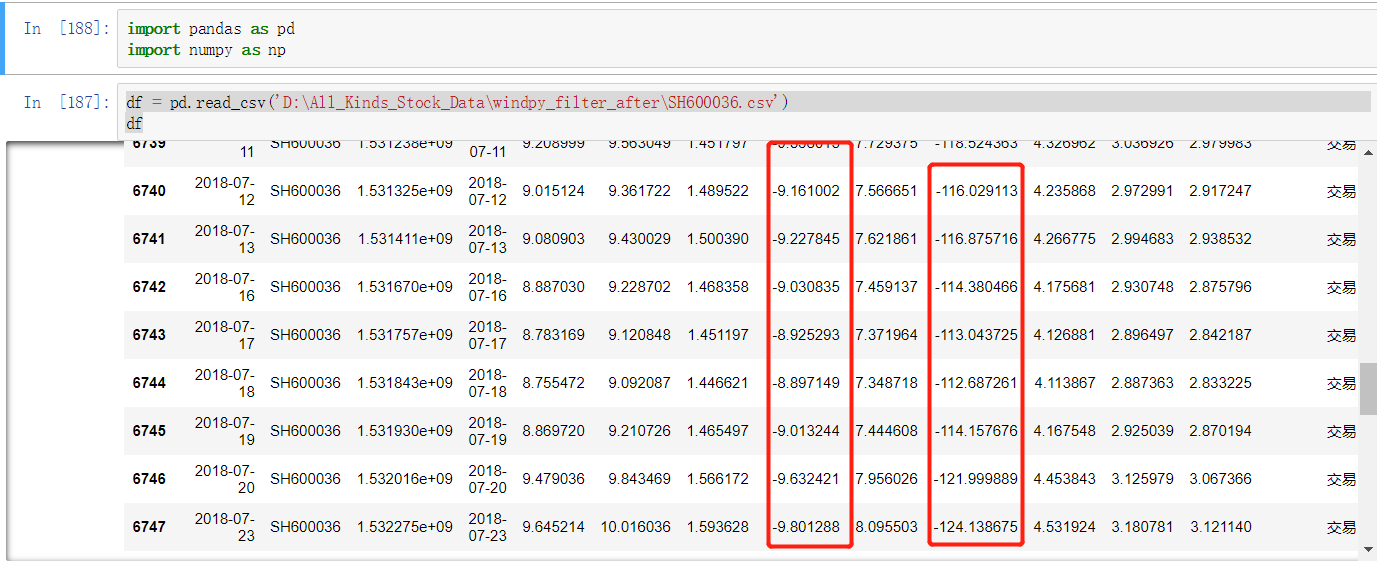
import pandas as pd import numpy as np df = pd.read_csv('D:All_Kinds_Stock_Datawindpy_filter_afterSH600036.csv') df # 开发环境: ipython notebook 下
读取本地csv文件,输出结果如下:
可见里面有很多“负值”。
目的就是将这些“负值”替换掉。
过滤“负值”
代码:
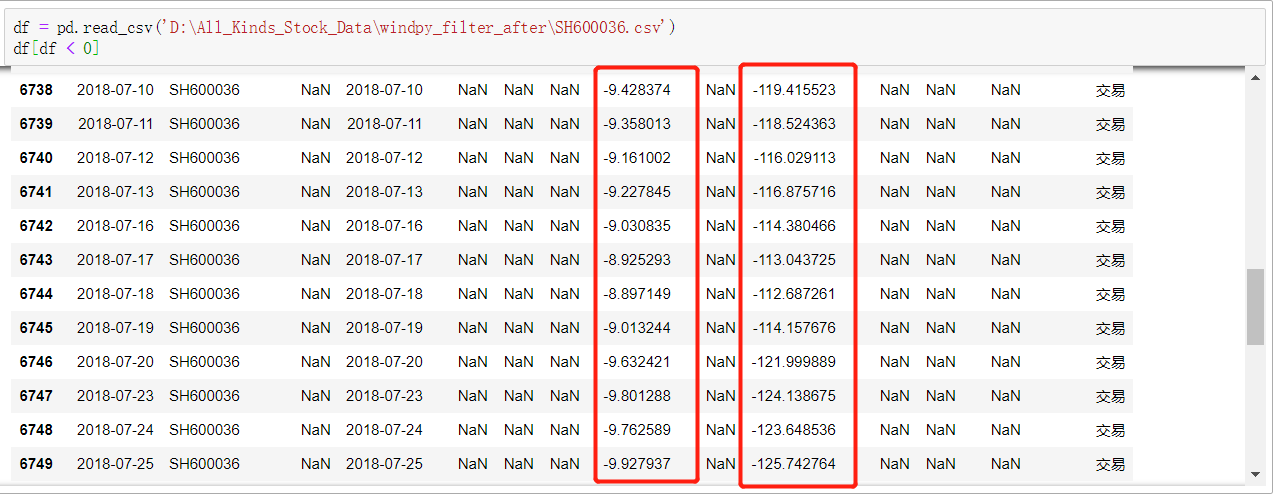
import pandas as pd import numpy as np df = pd.read_csv('D:All_Kinds_Stock_Datawindpy_filter_afterSH600036.csv') df[ df < 0 ] # 过滤出所有小于 0 的对象 # 开发环境: ipython notebook 下
此时拿到的是csv文件中所有小于 0 的元素(也即小于 0 的DateFrame对象)
替换“负值”
将过滤出来小于 0 的DateFrame对象替换成指定值。
这里我需要将它们替换为 NaN
代码:
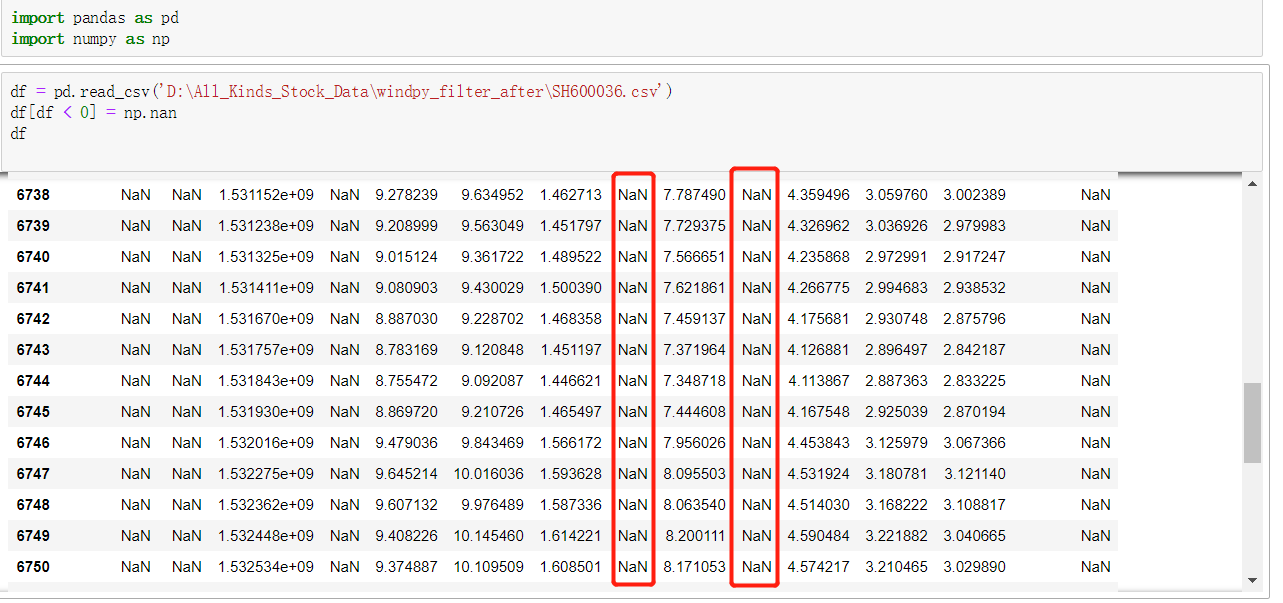
import pandas as pd import numpy as np df = pd.read_csv('D:All_Kinds_Stock_Datawindpy_filter_afterSH600036.csv') df[df < 0] = np.nan # 对过滤出来的对象进行赋值替换 df
此时,所有“负值”已被替换为 NaN
如果你想把替换后的DateFrame保存为新的csv文件的话,只需要如下操作:
df = pd.read_csv('D:All_Kinds_Stock_Datawindpy_filter_afterSH600036.csv') df[df < 0] = np.nan df.to_csv('你的保存路径', index=True) # index = True/False 表示是否把索引index一起写入csv文本。
