步骤一:修改公共属性配置 core-site.xml 文件
[root@node-01 ~]# cd /root/apps/hadoop-3.2.1/etc/hadoop
[root@node-01 hadoop]# cp core-site.xml core-site.xml.bak
[root@node-01 hadoop]# vim core-site.xml
<configuration>
<!-- 设置hdfs文件系统-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop</value>
</property>
<!-- zookeeper 集群-->
<property>
<name>ha.zookeeper.quorum</name>
<value>node-01:2181,node-02:2181,node-03:2181</value>
</property>
<!--关闭 HDFS 的权限检查 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!-- 配置 root 用户可以访问 hdfs -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<!-- 配置 root 用户所在组可以访问 hdfs -->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
步骤二:修改 HDFS 属性配置 hdfs-site.xml 文件
[root@node-01 ~]# cd /root/apps/hadoop-3.2.1/etc/hadoop
[root@node-01 hadoop]# cp hdfs-site.xml hdfs-site.xml.bak
[root@node-01 hadoop]# vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/apps/hadoop-3.2.1/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/apps/hadoop-3.2.1/data/datanode</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node-02:9868</value>
</property>
<property>
<!-- 指定hdfs的命名服务,需要和core-site.xml中的保持一致 -->
<name>dfs.nameservices</name>
<value>hadoop</value>
</property>
<property>
<!-- hadoop下面有两个NameNode,分别是nn1,nn2 -->
<name>dfs.ha.namenodes.hadoop</name>
<value>nn1,nn2</value>
</property>
<property>
<!-- nn1的RPC通信地址 -->
<name>dfs.namenode.rpc-address.hadoop.nn1</name>
<value>node-01:9000</value>
</property>
<property>
<!-- nn1的http通信地址 -->
<name>dfs.namenode.http-address.hadoop.nn1</name>
<value>node-01:9870</value>
</property>
<property>
<!-- nn2的RPC通信地址 -->
<name>dfs.namenode.rpc-address.hadoop.nn2</name>
<value>node-02:9000</value>
</property>
<property>
<!-- nn2的http通信地址 -->
<name>dfs.namenode.http-address.hadoop.nn2</name>
<value>node-02:9870</value>
</property>
<property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node-01:8485;node-02:8485;node-03:8485/hadoop</value>
</property>
<property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<name>dfs.journalnode.edits.dir</name>
<value>/root/apps/hadoop-3.2.1/data/journal</value>
</property>
<property>
<!-- 开启NameNode故障时自动切换 -->
<name>dfs.ha.automatic-failover.enabled.hadoop</name>
<value>true</value>
</property>
<property>
<!-- 配置失败自动切换实现方式 -->
<name>dfs.client.failover.proxy.provider.hadoop</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<!-- 配置故障切换脑裂解决方案-->
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<!-- 配置namenode 连接 journalnode 重试次数-->
<name>ipc.client.connect.max.retries</name>
<value>30</value>
</property>
</configuration>
步骤三:添加 JournalNode 进程执行权限
[root@node-01 ~]# echo "export HDFS_JOURNALNODE_USER=root" >> /etc/profile
[root@node-01 ~]# source /etc/profile
[root@node-02 ~]# echo "export HDFS_JOURNALNODE_USER=root" >> /etc/profile
[root@node-02 ~]# source /etc/profile
[root@node-03 ~]# echo "export HDFS_JOURNALNODE_USER=root" >> /etc/profile
[root@node-03 ~]# source /etc/profile
步骤四:拷贝配置到 node-02、node-03
[root@node-01 hadoop]# scp core-site.xml node-02:$PWD
[root@node-01 hadoop]# scp hdfs-site.xml node-02:$PWD
[root@node-01 hadoop]# scp core-site.xml node-03:$PWD
[root@node-01 hadoop]# scp hdfs-site.xml node-03:$PWD
步骤五:删除 node-01、node-02 和 node-03 存储数据目录
[root@node-01 ~]# rm -rf /root/apps/hadoop-3.2.1/data
[root@node-02 ~]# rm -rf /root/apps/hadoop-3.2.1/data
[root@node-03 ~]# rm -rf /root/apps/hadoop-3.2.1/data
步骤六:启动所有进程
启动所有的进程可以直接执行 start-dfs.sh 脚本,但是为了对 Hadoop 的进程有所了解,这里选择一个个进程按顺序来启动(注:必须严格按照顺序启动进程)
-
启动 ZooKeeper 进程
[root@node-01 ~]# zkCluster.sh start [root@node-01 ~]# jps 1567 QuorumPeerMain -
启动 Journalnode 进程
[root@node-01 ~]# hdfs --daemon start journalnode [root@node-01 hadoop]# jps 2039 JournalNode #journalnode 进程已启动 2059 Jps [root@node-02 ~]# hdfs --daemon start journalnode [root@node-03 ~]# hdfs --daemon start journalnode -
启动 NameNode(nn1) 进程
[root@node-01 ~]# hdfs namenode -format [root@node-01 ~]# hdfs --daemon start namenode -
启动 NameNode(nn2) 进程
[root@node-02 ~]# hdfs namenode -bootstrapStandby [root@node-02 ~]# hdfs --daemon start namenode注:在 HA 中不需要启动 SecondaryNameNode 进程,因为 Standby NameNode 会执行 checkpointing 机制
-
启动 DataNode 进程
[root@node-01 hadoop]# hdfs --daemon start datanode [root@node-02 hadoop]# hdfs --daemon start datanode [root@node-03 hadoop]# hdfs --daemon start datanode -
启动 DFSZKFailoverController(ZKFC)进程
[root@node-01 hadoop]# hdfs zkfc -formatZK [root@node-01 hadoop]# hdfs --daemon start zkfc [root@node-02 hadoop]# hdfs --daemon start zkfc
步骤七:查看所有进程
[root@node-01 hadoop]# jps
2368 QuorumPeerMain
3715 DataNode
3987 DFSZKFailoverController
4435 NameNode
3430 JournalNode
[root@node-02 hadoop]# jps
2069 QuorumPeerMain
3033 DataNode
3987 DFSZKFailoverController
2379 JournalNode
5278 NameNode
[root@node-03 logs]# jps
2036 QuorumPeerMain
2170 JournalNode
2298 DataNode
步骤八:查看 HDFS HA 集群状态报告信息
[root@node-02 ~]# hdfs dfsadmin -report
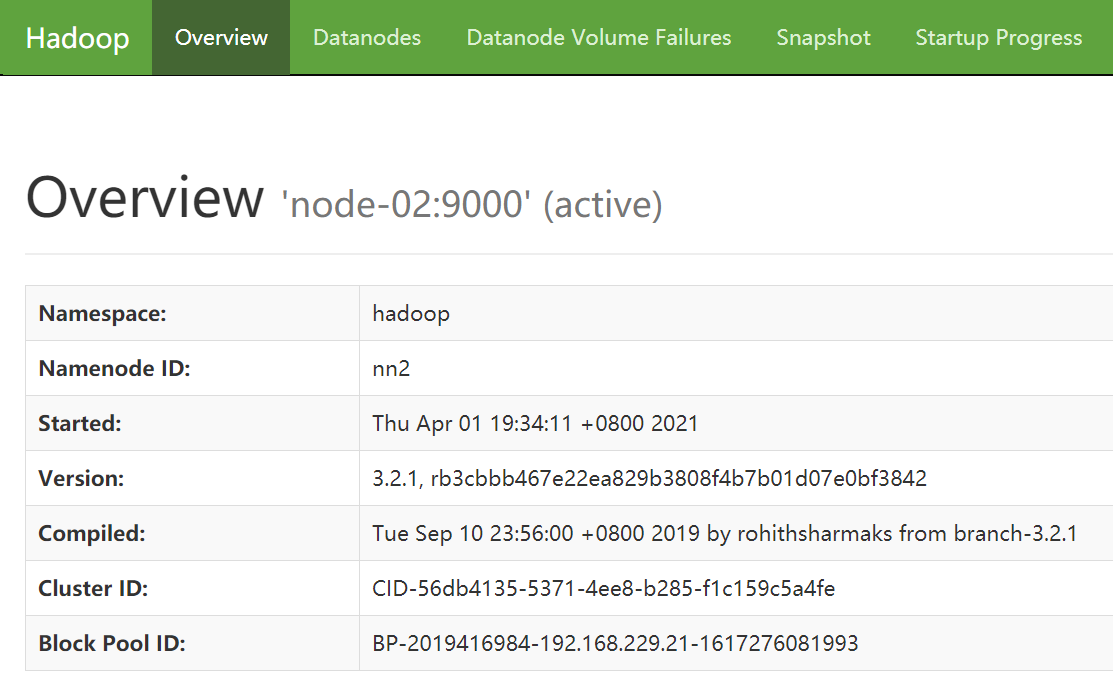
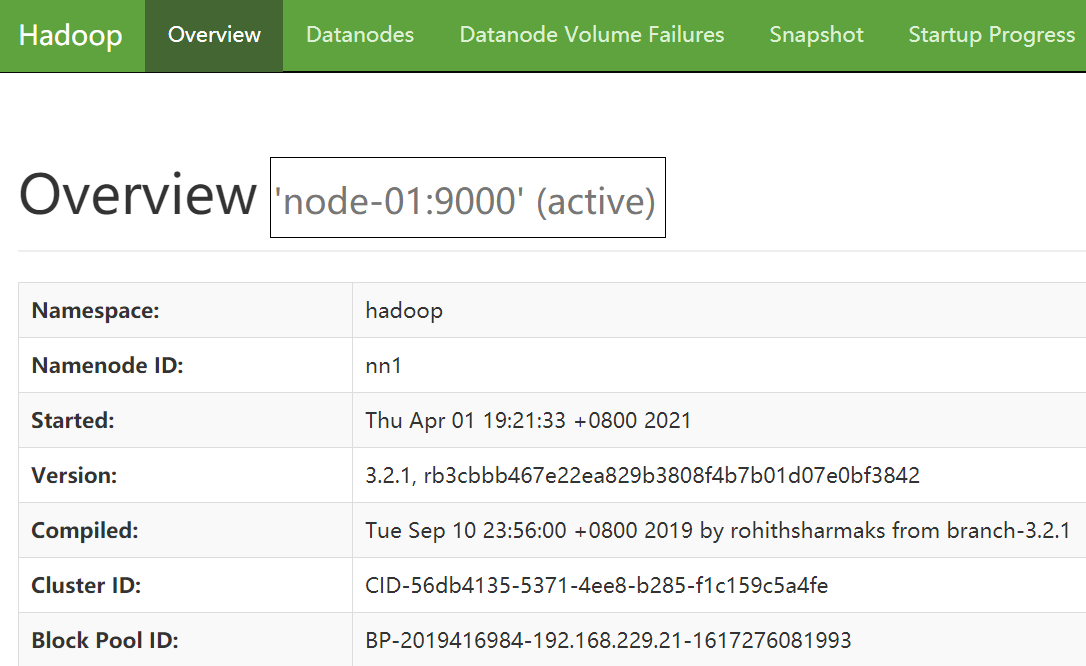
步骤九:Web UI 中 查看 NameNode(nn1)和 NameNode(nn2)状态
-
nn1地址: 192.168.229.21:9870
-
nn2 地址:192.168.229.22:9870
步骤十:故障转移测试
#安装故障转移脑裂问题解决工具
[root@node-01 hadoop]# yum install psmisc
[root@node-02 hadoop]# yum install psmisc
[root@node-03 hadoop]# yum install psmisc
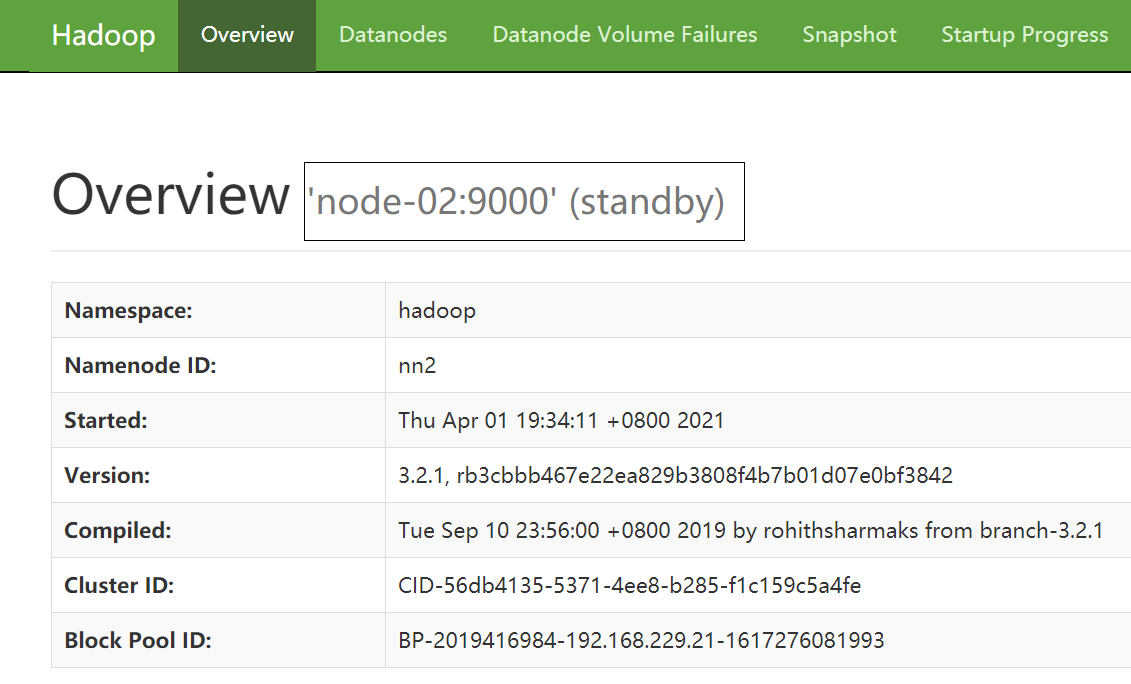
#关闭 node-01 的 NameNode(active)进程
[root@node-01 hadoop-3.2.1]# hdfs --daemon stop namenode
查看 node-02 的 NameNode,由 Standby 变为 了 Active,说明自动故障转移成功:)