前言
对于检索式对话系统最基本的步骤就是召回(retrieval)-匹配(matching)-排序(reranking)。匹配的得分直接决定最后你要输出的答案对应FAQ中的标准问题,所以这是很重要的一步。说是文本匹配,感觉更好的措辞应该是语义匹配。这里借鉴的都是文本匹配/文本蕴含/自然语言推理这个领域的文章。
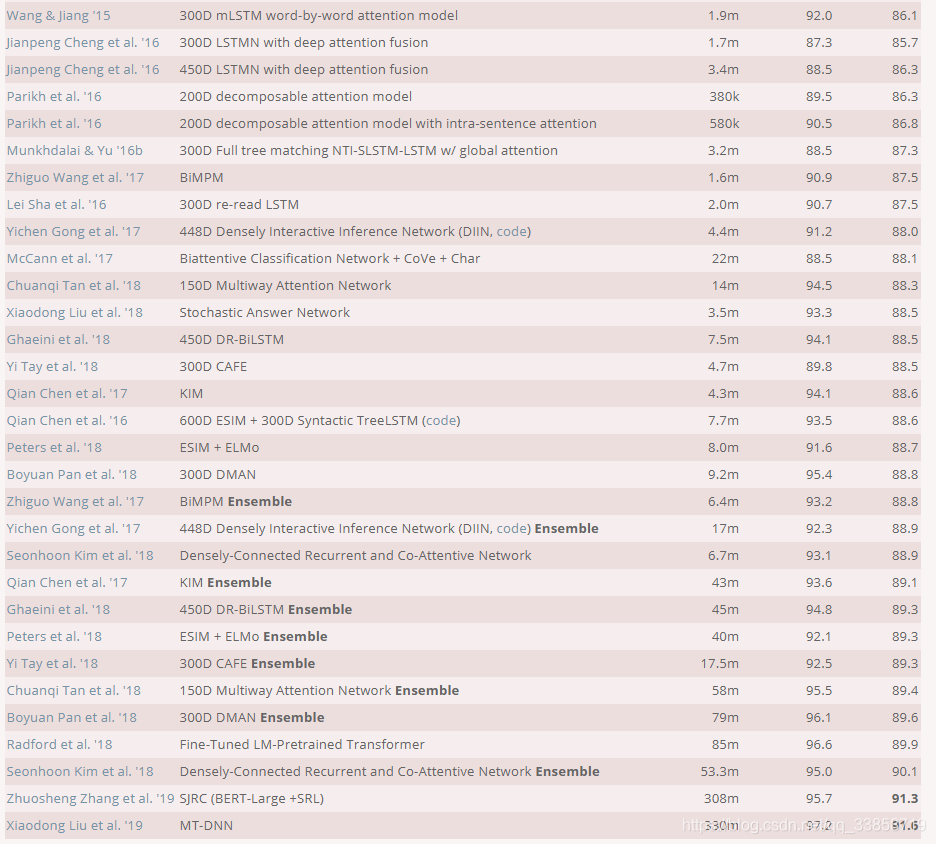
更多的论文算法可以在Standford的SNLI评测官网看到:
经典方法
传统方案统计模型各种各样,很多都是基于字面匹配做的,无法考虑到语义上的相似度,这里暂且熟悉一下wmd、bm25两种比较常用的方法。
WMD词移距离
Word2Vec得到的词向量可以反映词与词之间的语义差别,那么如果我们希望有一个距离能够反映文档和文档之间的相似度,一个想法是将文档距离建模成两个文档中词的语义距离的一个组合,比如说对两个文档中的任意两个词所对应的词向量求欧氏距离然后再加权求和,大概是这样的形式: ,其中 为两个词所对应的词向量的欧氏距离。这个加权矩阵T有些类似于HMM中的状态转移矩阵,只不过其中的概率转换为权重了而已。
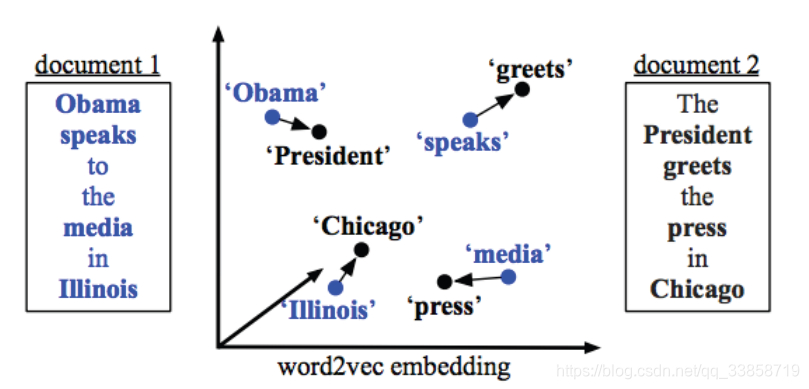
以上两个文本去除停用词后,每篇文档仅剩下4个词,我们就是要用这四个词来比较两个文档之间的相似度。在这里,我们假设’Obama’这个词在文档1中的的权重为0.5(可以简单地用词频或者TFIDF进行计算),那么由于’Obama’和’president’的相似度很高,那么我们可以给由’Obama’移动到’president’很高的权重,这里假设为0.4,文档2中其他的词由于和’Obama’的距离比较远,所以会分到更小的权重。这里的约束是,由文档1中的某个词移动到文档2中的各个词的权重之和应该与文档1中的这个词的权重相等,即’Obama’要把自己的权重(0.5)分给文档2中的各个词。同样,文档2中的某个词所接受到由文档1中的各个词所流入的权重之和应该等于词在文档2中的权重。
所以 代表的是文档1要转换为文档2所需要付出的总代价。将这种代价求得下界即最小化之后,即可求得所有文档a中单词转移到文档b中单词的最短总距离,代表两个文档之间的相似度。
BM25
bm25 是一种用来评价搜索词和文档之间相关性的算法,它是一种基于概率检索模型提出的算法,再用简单的话来描述下bm25算法:我们有一个query和一批文档D,现在要计算query和每篇文档D之间的相关性分数,我们的做法是,先对query进行切分,得到单词,然后单词的分数由3部分组成:
- 单词和D之间的相关性
- 单词和query之间的相关性
- 每个单词的权重
最后对于每个单词的分数我们做一个求和,就得到了query和文档之间的分数。
深度文本匹配
传统的文本匹配如 BoW、TFIDF、VSM等算法,主要解决词汇层面的匹配问题,而实际上基于词汇重合度的匹配算法存在着词义局限、结构局限和知识局限等问题。
- 词义局限:的士和出租车虽然字面上不相似,但实为同一种交通工具;而苹果在不同的语境下表示的东西不同,或为水果或为公司;
- 结构局限:机器学习和学习机器虽词汇完全重合,但表达的意思不同;
- 知识局限:秦始皇打 Dota,这句话虽从词法和句法上看均没问题,但结合知识看这句话是不对的。
传统的文本匹配模型需要基于大量的人工定义和抽取的特征,而这些特征总是根据特定的任务(信息检索或者自动问答)人工设计的,因此传统模型在一个任务上表现很好的特征很难用到其他文本匹配任务上。而深度学习方法可以自动从原始数据中抽取特征,省去了大量人工设计特征的开销。首先特征的抽取过程是模型的一部分,根据训练数据的不同,可以方便适配到各种文本匹配的任务当中;其次,深度文本匹配模型结合上词向量的技术,更好地解决了词义局限问题;最后得益于神经网络的层次化特性,深度文本匹配模型也能较好地建模短语匹配的结构性和文本匹配的层次性
一般来说,深度文本匹配模型分为两种类型,表示型(Representation Model)和交互型(Interaction Model)。表示型模型更侧重对表示层的构建,它会在表示层将文本转换成唯一的一个整体表示向量。典型的网络结构有 DSSM、CDSMM 和 ARC-I。这种模型的核心问题是得到的句子表示失去语义焦点,容易发生语义偏移,词的上下文重要性难以衡量。交互型模型摒弃后匹配的思路,假设全局的匹配度依赖于局部的匹配度,在输入层就进行词语间的先匹配,并将匹配的结果作为灰度图进行后续的建模。典型的网络结构有 ARC-II、DeepMatch 和 MatchPyramid。它的优势是可以很好的把握语义焦点,对上下文重要性合理建模。由于模型效果显著,业界都在逐渐尝试交互型的方法。
深度学习应用在文本匹配上可以总结为以下四个阶段:1、单语义模型,单语义模型只是简单的用全连接、CNN类或RNN类的神经网络编码两个句子然后计算句子之间的匹配度,没有考虑到句子中短语的局部结构。2、多语义模型,多语义模型从多颗粒的角度解读句子,考虑到和句子的局部结构。3、匹配矩阵模型,匹配矩阵模型更多的考虑待匹配的句子间不同单词的交互,计算两两之间的匹配度,再用深度网络提取特征,更精细的处理句子中的联系。4、深层次的句子间模型,这是近几年state of the art的模型,随着attention等交互机制论文的发表,最新的论文用更精细的结构去挖掘句子内和句子间不同单词之间的联系,得到更好的效果。
—— 以上来自深度文本匹配发展总结
DSSM
Learning Deep Structured Semantic Models for Web Search using Clickthrough Data
原理:先把 query 和 document 转换成 BOW 向量形式,然后通过 word hashing 变换做降维得到相对低维的向量(除了降维,word hashing 还可以很大程度上解决单词形态和 OOV 对匹配效果的影响),喂给 MLP 网络,输出层对应的低维向量就是 query 和 document 的语义向量(假定为 Q 和 D)。计算(D, Q)的 cosinesimilarity 后,用 softmax 做归一化得到的概率值是整个模型的最终输出,该值作为监督信号进行有监督训练。
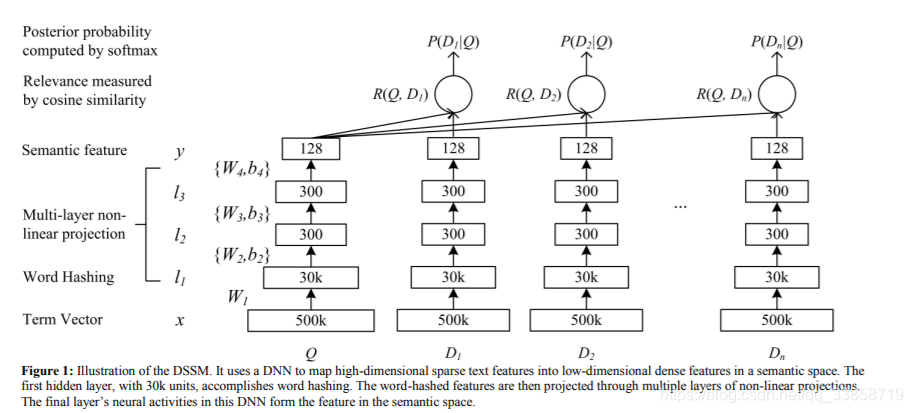
这是模型的结构图,输入Q是一个查询,D是各个候选文档,可以看到用词袋模型维度是500k,用word hashing 的方法可以将维度压缩到30k,然后通过全连接的神经网络对向量进行降维到128,接着两两计算余弦相似度得到匹配结果。后续的CDSSM和DSSM-LSTM应该算是常见的改进方式, CNN和RNN可能对不同文本数据的适用情况不同。
它有两个创新点,一个是用一种3个字母word hashing代替词袋模型(所谓的3个字母的word hashing就是先在单词上加上#表示符标记开头和结尾,例如#good#,然后每3个符号进行拆分,即变成#goo, goo, ood, od#,然后用multi-hot的形式表示这个单词,数据集的英语词汇可能会有很多),降低了单词向量的维度(由于当时word2vec论文还未发表),第二个是用全连接的神经网络处理句子,揭开深度文本匹配的篇章。
这个模型的缺陷在于:
1、没有考虑到单词之间的时序联系
2、相似度匹配用的余弦相似度是一个无参的匹配公式。
MatchPyramid
原理:借鉴做图像的方法, 把文本匹配转化成Text Matrix, 搭建了CNN金字塔模型完成匹配预测。从3个角度构建匹配矩阵,更精细的考虑句子间单词的两两关系,构建出3个矩阵进行叠加,把这些矩阵看作是图片,用卷积神经网络对矩阵进行特征提取。
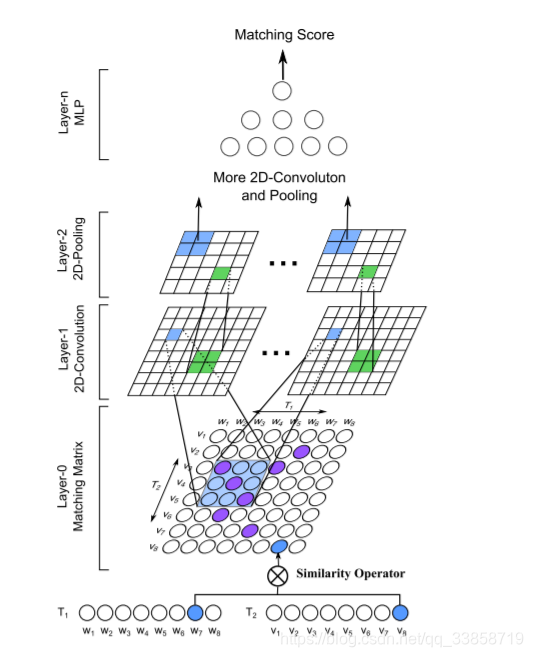
由于CNN针对的是网格型数据,而文本显然属于序列数据,那么就有必要对数据进行转换,论文中提出了三种构建相似度矩阵的方法:
- : 0-1类型,每个序列对应的词相同为1,不同为0
- : 使用预训练的Glove将词转为向量,之后计算序列对应的词的cosine距离
- : 同上,但是将cosine距离改为点积,作者在文中提到,距离矩阵使用点积的效果相对较好
根据结果显示,在文本方面使用作者提出的方法可以提取n-gram、n-term特征。
ESIM
ESIM 是最近提出的效果比较好的一个文本相似度计算模型,该模型横扫了很多比赛,它的优势在于精细的设计序列式的推断结构、考虑局部推断和全局推断。
作者主要是用句子间的注意力机制(intra-sentence attention),来实现局部的推断,进一步实现全局的推断。
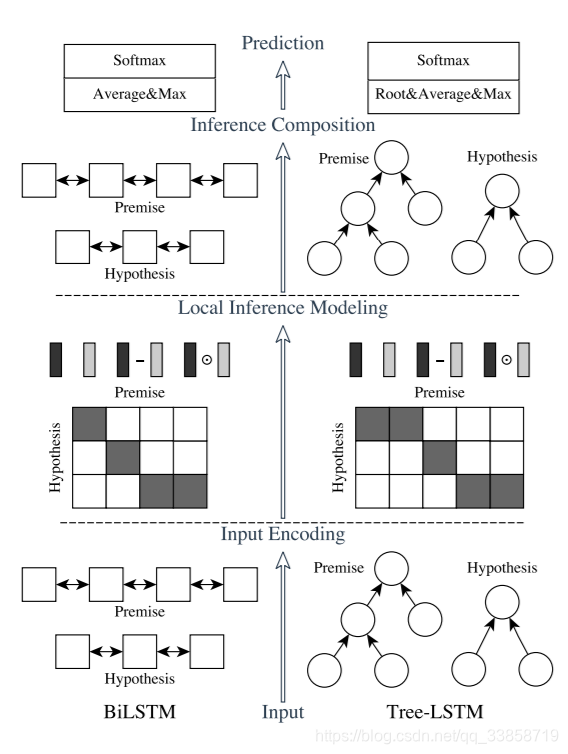
它的主要组成为:输入编码,局部推理建模和推理组合。图中垂直方向描绘了三个主要组件,水平方向,左侧代表连续语言推断模型,名为ESIM,右侧代表在树LSTM中包含语法分析信息的网络。
input encoding
输入两句话 , 分别接 embeding + BiLSTM, 使用 BiLSTM 可以学习如何表示一句话中的 word 和它上下文的关系,也就是在 word embedding 之后,在当前的语境下重新编码,得到新的 embedding 向量。
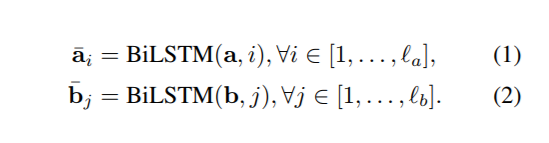
local inference modeling
local inference 之前需要将两句话进行 alignment,这里是使用soft_align_attention。具体做法是,首先计算两个句子 word 之间的相似度,得到2维的相似度矩阵,然后才进行两句话的 local inference。用之前得到的相似度矩阵,结合 a,b 两句话,互相生成彼此相似性加权后的句子,维度保持不变,其实就是点积计算attention权重。
在 local inference 之后,进行 Enhancement of local inference information。这里的 enhancement 就是计算 a 和 align 之后的 a 的差和点积来增强局部推理信息。
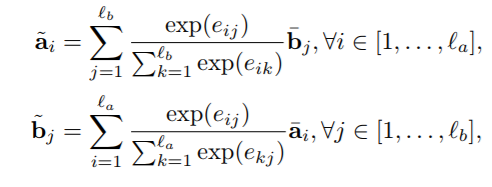
inference composition
再一次用 BiLSTM 提前上下文信息,对于 BiLSTM 提取到的信息,作者认为求和对序列长度比较敏感,不太健壮,因此他们采用了 MaxPooling 和 AvgPooling 的方案,并将池化后的结果连接为固定长度的向量,最后接一个全连接层。
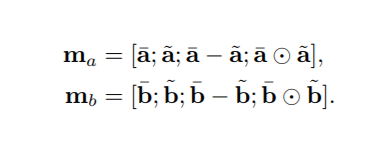
BiMPM
Bilateral Multi-Perspective Matching for Natural Language Sentences
双边多角度句子匹配,这篇文章的创新点在于:1、双边,认为句子不应该仅仅考虑一个方向,从问句出发到答句,也应该从答句去反推问句。2、多角度,在考虑句子间的交互关系时采用了4种不同的方式。这篇文章发表在2017年的IJCAIi,模型取得了很好的效果,但是缺点在于参数很多,运算速度比较慢。
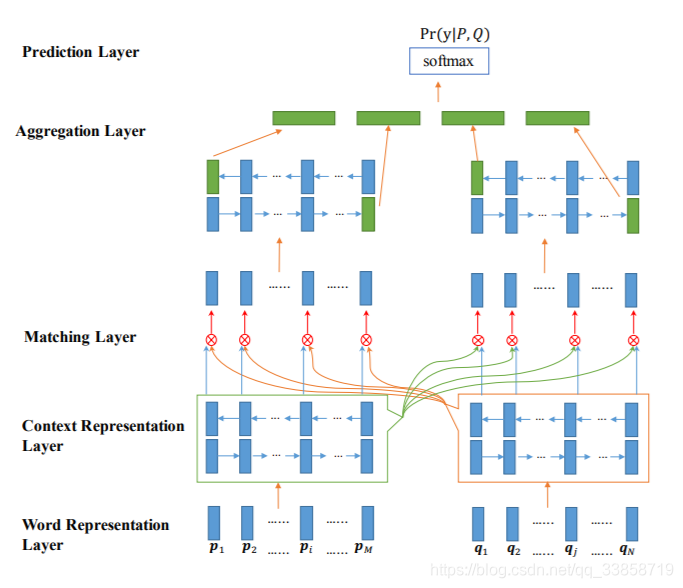
模型的整体框架图,输入是预训练的 glove embeddings 和 chars embeddings,经过 BiLSTM 的编码之后,对每一个step的 LSTM 的输出进行从p到q和从q到p的两两配对,有四种组合方式,然后将所有的结果进行拼接和预测结果。
Word Representation Layer
将句子中的每个单词表示为d维向量,这里d维向量分为两部分:一部分是固定的词向量,另一部分是字符向量构成的词向量。这里将一个单词里面的每个字符向量输入LSTM得到最后的词向量。
Context Representation Layer
将上下文信息融合到P和Q每个time-step的表示中,这里利用Bi-Lstm表示P和Q每个time-step的上下文向量。
Matching Layer
比较句子P的每个上下文向量(time-step)和句子Q的所有上下文向量(time-step),比较句子Q的每个上下文向量(time-step)和句子P的所有上下文向量(time-step)。为了比较一个句子的某个上下文向量(time-step)和另外一个句子的所有上下文向量(time-step),这里设计了一种 multi-perspective匹配方法。这层的输出是两个序列,序列中每一个向量是一个句子的某个time-step对另一个句子所有的time-step的匹配向量。
Multi-Perspective的四种方案:
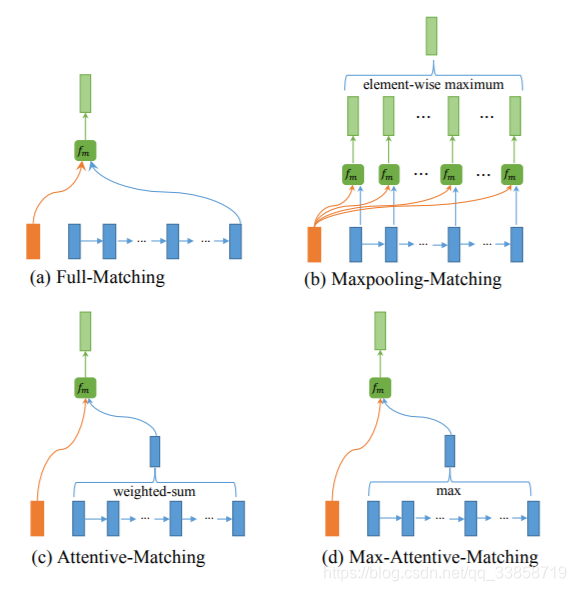
1、Full-Matching:如图a所示,将P在上层LSTM输出的隐藏层每一个 与Q在上层LSTM最后输入的 做计算
2、Maxpooling-Matching:如图b所示,图中清晰地表明了如何操作,不同于Full-matching模式,这里将P与Q在每一个时刻的上一层的隐藏层输出做相应计算,并且在每一维度上取max
3、Attentive-Matching:先计算P中每一个前向(反向)文法向量与Q中每一个前向(反向)文法向量的余弦相似度,然后利用余弦相似度作为权重对Q各个文法向量进行加权求平均作为Q的整体表示,最后P中每一个前向(后向)文法向量与Q对应的整体表示进行匹配。
4、Max-Attentive-Matching:与Attentive-Matching类似,不同的是不进行加权求和,而是直接取Q中余弦相似度最高的单词文法向量作为Q整体向量表示,与P中每一个前向(反向)文法向量进行匹配。
Aggregation Layer
聚合两个匹配向量序列为一个固定长度的匹配向量。对两个匹配序列分别应用BiLSTM,然后连接BiLSTM最后一个time-step的向量(4个)得到最后的匹配向量。
DIIN
这篇论文的创新点在于考虑到了同句间不同单词之间的交互关系,另外就是模型中采用了2016年 CVPR 的 best paper 的model DenseNet。DenseNet 可以在经过复杂的深度神经网络之后,还可以很大程度上保留原始特征的信息。
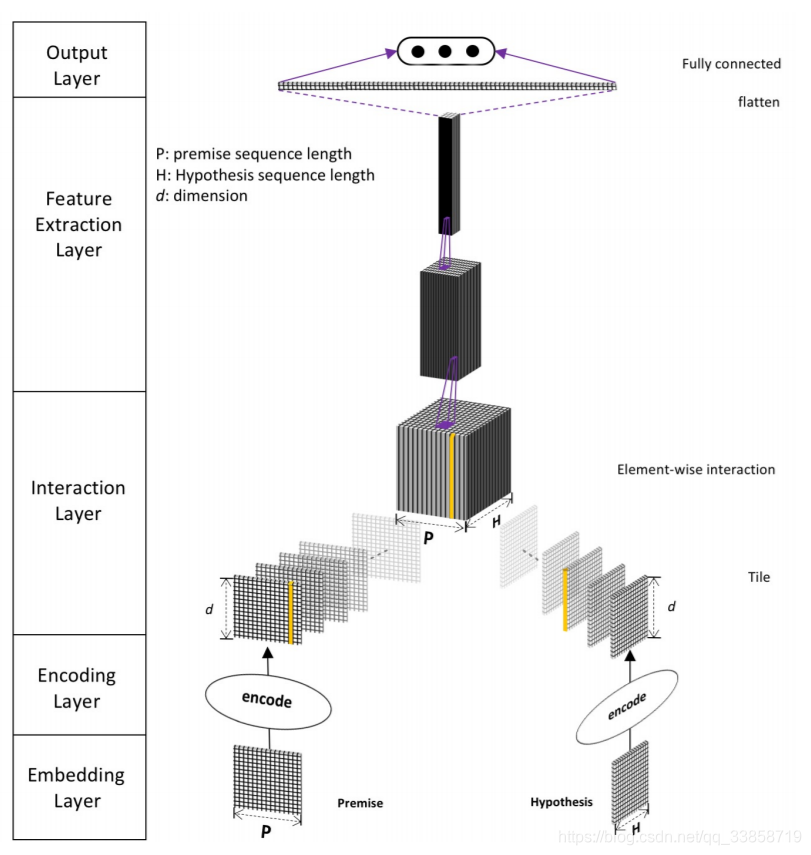
这是模型的整体框架图,可以看到模型的输入有4个部分的特征:glove、char、EM、POS。然后用 highway network 对特征进行编码,这个编码的输出构造一个句子内的 attention,具体就是里面的公式 ,对单词 和单词 的向量和它们的点积进行拼接,再做一个线性的映射得到一个权重参数,经过 softmax 归一化后成为句内 attention 的权重参数,然后是参考了LSTM的设计,对 highway 出来的向量和带了句内交互的 attention 项的向量用门机制进行了过滤,得到每个单词的向量表示,然后将向量表示两两之间做一个匹配形成匹配矩阵,最后用 DenseNet 对匹配矩阵进行特征提取。
Embedding Layer
1、word embedding:论文中使用的是通过GloVe预训练好的向量,而且论文中提到在训练时, 要打开word embedding的训练, 跟随着任务一起训练。
2、character feature:这里指的是对一个 word 中的 char 进行自动的 feature。
首先使用 char embedding 对每个 char 进行向量化, 然后对char向量进行1-D的卷积, 最后使用 MaxPool 得到这一个单词对应的char特征向量。
3、syntactical features:添加这种的目的是为 OOV(out-of-vocabulary)的word提供额外补充的信息. 论文中提到的方法有:
- part-of-speech(POS)词性特征, 使用词性的One-Hot特征
- binary exact match(EM)特征, 指的是一个句字中的某个word与另一个句子中对应的word的词干stem和辅助项lemma相同, 则是1, 否则为0. 具体的实现和作用在论文中有另外详细的阐述。
Encoding Layer
在这一层中, premise和hypothesis会经过一个两层的神经网络, 得到句子中的每一个word将会用一种新的方式表示. 然后将转换过的表示方法传入到一个 self-attention layer 中。
需要注意的是, 在这一层中, premise和hypothesis两个句子是不共享参数的, 但是为了让两个句子的参数相近, 两个句子在相同位置上的变量, 会对他们之间的差距做L2正则惩罚, 将这种惩罚计入总的loss, 从而在训练过程中, 保证了参数的近似。
Interaction Layer
对两个句子的word进行编码之后, 就要考虑两个句子相互作用的问题了. 对于长度为p的premise和长度为h的hypothesis, 对于他们的每个单词 和 , 将代表它们的向量逐元素点乘, 这样就得到了一个形状为 的两个句子相互作用后的结果. 可以把他们认为是一个2-d的图像, 有d个通道。
Feature Extraction Layer
由于两个句子相互作用产生了一个2-d的结果, 因此我们可以通过使用那些平常用在图像上的CNN方法结构, 来提取特征, 例如ResNet效果就很好. 但考虑到模型的效率, 与参数的多少, 论文中使用了DenseNet这种结构…
DRCN
Semantic Sentence Matching with Densely-connected Recurrent and Co-attentive Information
这篇论文的创新点在于:1、采用了固定的glove embedding和可变的glove embedding拼接并提升了模型效果。2、采用stack层级结构的LSTM,在层级结构上加入了DenseNet的思想,将上一层的参数拼接到下一层,一定程度上在长距离的模型中保留了前面的特征信息。(Attention 算法在刻画两个句子语义关系和对齐句子成分方面有很好的效果,但是也有不足之处。Attention 机制仅使用求和操作,这样来自于上层的特征信息就会被破坏,不能完整保留下来。)3、由于不断的拼接导致参数增多,用autoencoder进行降维,并起到了正则化效果,提升了模型准确率。
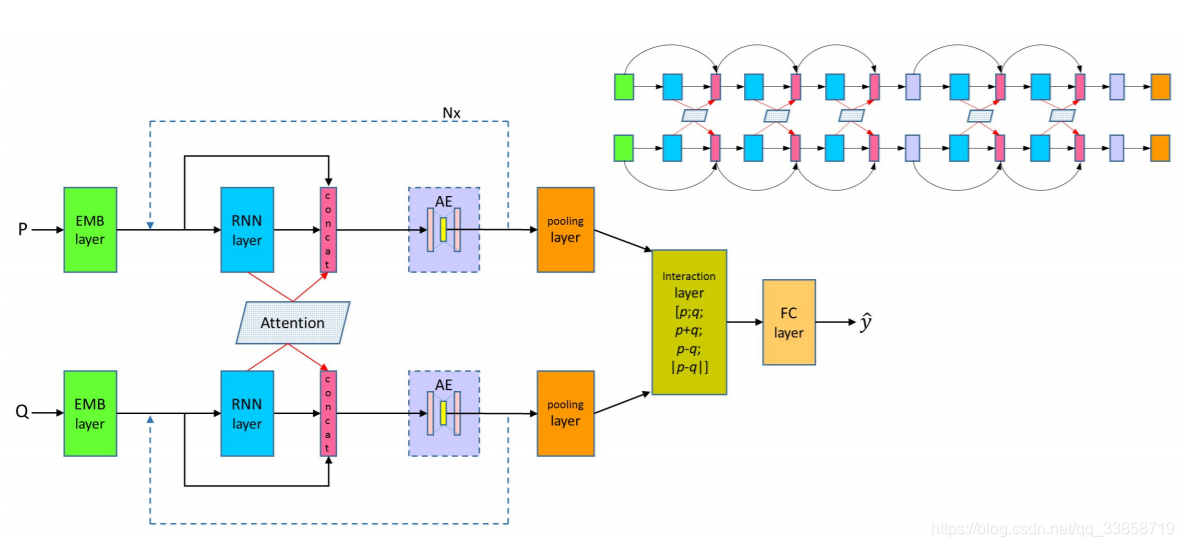
模型的输入是可变的glove向量和非可变的glove向量,chars卷积特征和一些标示特征(例如EM特征),然后经过BiLSTM对每个单词的特征编码,同时这里会加入attention机制考虑两个句子间的交互关系,计算隐藏层输出余弦相似度,softmax归一化成attention权重,加权求和后得到attention的向量,当前的单词特征向量、attention的向量、上一层的LSTM该step隐藏层输出向量同时作为当前step的输入,然后采用stack LSTM的结构叠加多层LSTM,论文中一个叠加了5层,随着层数的增加,每一层step的输入会越来越大,所以在最后两层加入了autoencoder对参数进行降维,最后用全连接网络进行预测。
Embedding Layer
四个词向量的特征:
1、与模型一起训练的Glove词向量:
2、直接拿来用的,保持不变的Glove词向量:
3、用CNN得到的字向量:
4、Match Flag特征 :这是一个0/1特征,表示该词是否在另一句话中出现。
Densely connected recurrent Co-attentive networks
RNN分别得到前提的表示和假设的表示,然后就是计算Attention,得到权重后,作者受DenseNet启发,使用了密集连接和RNN结合的方法来实现对对句子的处理。首先hlt表示的是第l层的RNN的第t的隐层状态,
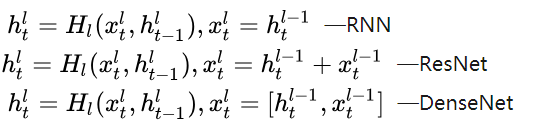
式1是传统的多层RNN的结构,前一层的RNN的 隐层状态作为当前层的输入,然后就是RNN的计算方式,式2借鉴了残差网络,当前层的输入不仅包含了前一层的隐层状态,同时包含了前一层的输入,但他们是相加的方式,作者认为这种相加的形式很可能会阻碍信息的流动,因此借鉴DenseNet,作者使用了拼接了方式,这样不仅保留了两部分信息,同时拼接方法也最大程度的保留了各自的独有信息。但这就有一个问题了,多层的RNN的参数就不一样了,因为拼接的方式导致了每一层输入对应的参数规模是在不断变大的,这样就不能做的很深了。
我们传统的做法是得到每个词在对方句子上的概率分布之后,使用对方句子中每个词向量的加权和作为当前词的向量表示,而这里作者直接使用了计算出来的权值分布,将其作为一个特征引入到当前层的输入当中:
AutoEncoder
Stack RNN 这样的结构必然会带来参数急速增长的问题,为了解决这个问题,作者使用了AutoEncoder,该模块的输出是自编码器的compressed representation,此维度是超参,在损失尽量小的情况下压缩参数。
Interaction Layer
最后对P、Q的表示做拼接、相加、相减、绝对值的运算,表示句子之间的匹配:
然后全连接和 softmax 得到P、Q之间的关系。(相减的效果要好于相减的绝对值,因为相减不仅可以表示差异,同时可以表明信息流方向,而相减的绝对值就更专注于差异了)
模型对比论文阅读
这篇文章是 COLING 2018 的 Best Reproduction Paper,文章主要对现有的做句子对任务的最好的几个模型进行了重现,并且作者实现出来的效果和原文章声称的效果相差不多,作者对语义理解的集中任务也做了相关梳理。
任务
- Semantic Textual Similarity (STS) :判断两个句子的语义相似程度(measureing the degree of equivalence in the underlying semantics of paired snippets of text);
- Natural Language Inference (NLI) :也叫 Recognizing Textual Entailment (RTE),判断两个句子在语义上是否存在推断关系,相对任务一更复杂一些,不仅仅是考虑相似,而且也考虑了推理;
- Paraphrase Identification (PI) :判断两个句子是否表达同样的意思(identifing whether two sentences express the same meaning);
- Question Answering (QA) :主要是指选择出来最符合问题的答案,是在给定的答案中进行选择,而不是生成;
- Machine Comprehension (MC) :判断一个句子和一个段落之间的关系,从大段落中找出存在答案的小段落,对比的两个内容更加复杂一些。
一般框架
- 输入层:适用预训练或者参与训练的词向量对输入中的每个词进行向量表示,比较有名的 Word2Vec,GloVe,也可以使用子序列的方法,例如 character-level embedding;
- 情境编码层:将句子所处的情境信息编码表示,从而更好的理解目标句子的语义,常用的例如 CNN,HighWay Network 等,如果是句子语义表示的方法,一般到这里就结束了,接下来会根据具体的任务直接使用这一层得到语义表示;
- 交互和注意力层:该层是可选的,句子语义表示有时候也会用到,但更多的是词匹配方法用到的,通过注意力机制建模两个句子在词层面的匹配对齐关系,从而在更细粒度上进行句子对建模,个人认为句子语义表示也会用到这些,只是句子语义表示最后会得到一个语义表示的向量,而词匹配的方法不一定得到句子语义的向量;
- 输出分类层:根据不同的任务,使用 CNN,LSTM,MLP 等进行分类判断。
模型选择:
- InferSent [1]:BiLSTM+max-pooling;
- SSE [2]:和 InferSent 比较类似;
- DecAtt [3]:词匹配模型的代表,利用注意力机制得到句子 1 中的每个词和句子 2 中的所有词的紧密程度,然后用句子 2 中的所有词的隐层状态,做加权和表示句子 1 中的每个词;
- ESIM [4]:考虑了一些词本身的特征信息,和 DecAtt 比较类似;
- PWIM [5]:在得到每个词的隐层状态之后,通过不同的相似度计算方法得到词对之间相似关系,最后利用 CNN 进行分类。
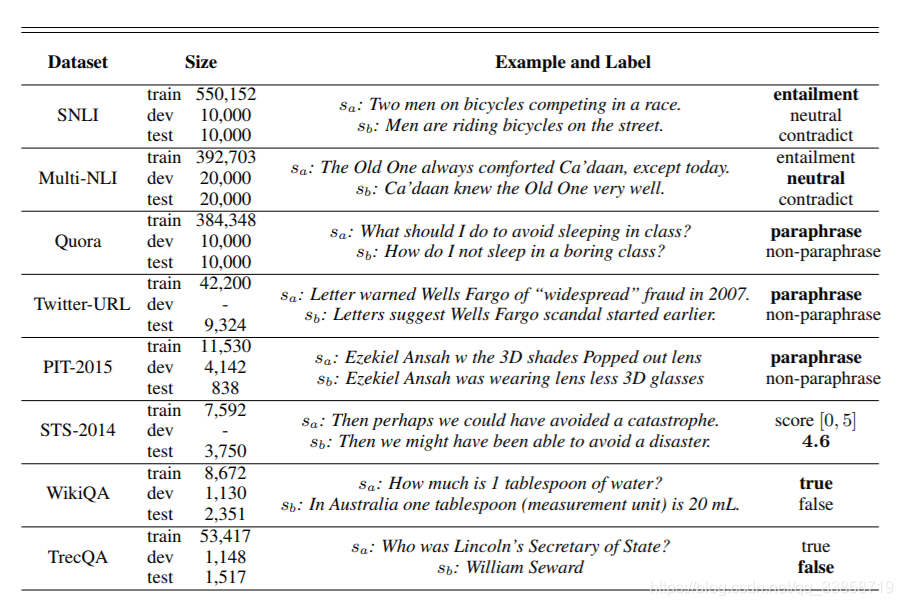
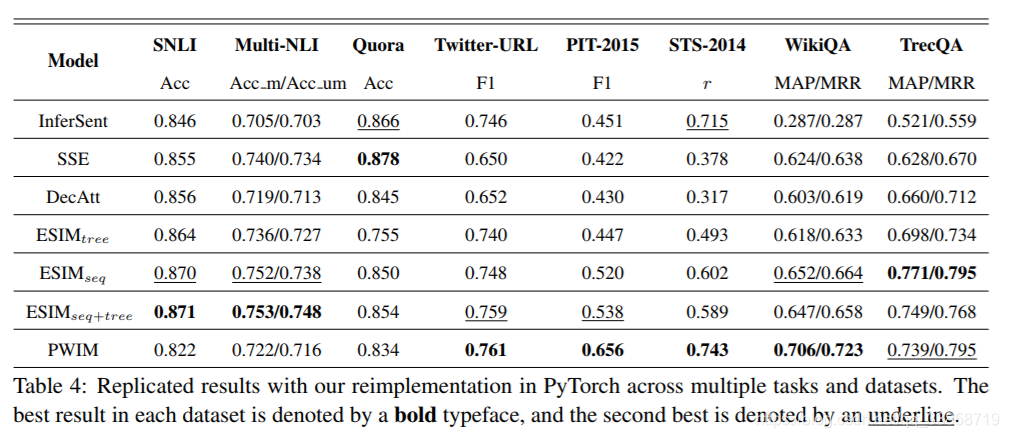
数据集及结果
参考论文
[1]. A. Conneau, D. Kiela, H. Schwenk, L. Barrault, A. Bordes, Supervised Learning of Universal Sentence Representations from Natural Language Inference Data
[2]. Shortcut-Stacked Sentence Encoders for Multi-Domain Inference, Yixin Nie and Mohit Bansal.
[3]. A Decomposable Attention Model for Natural Language Inference, AnkurP.Parikh, Oscar Täckstöm, Dipanjan Das, Jakob Uszkoreit
[4]. Enhanced LSTM for Natural Language Inference, Qian Chen, Xiaodan Zhu, Zhenhua Ling, Si Wei, Hui Jiang, Diana Inkpen
[5]. Hua He and Jimmy Lin. Pairwise Word Interaction Modeling with Deep Neural Networks for Semantic Similarity Measurement
Reference
1、衡量文档相似性的一种方法-----词移距离 Word Mover’s Distance
2、深度文本匹配发展总结
3、文本匹配方法 paper笔记
4、文本匹配模型-BiMPM
5、论文阅读笔记: Natural Language Inference over Interaction Space
6、论文笔记——Semantic Sentence Matching with DRCN
7、文本匹配模型-BiMPM
7、PaperWeekly 第37期 | 论文盘点:检索式问答系统的语义匹配模型(神经网络篇)
8、Neural Network Models for Paraphrase Identification, Semantic Textual Similarity, Natural Language Inference, and Question Answering论文阅读