列表类型可以存储一组按插入顺序排序的字符串,它非常灵活,支持在两端插入、弹出数据,可以充当栈和队列的角色。
> LPUSH fruit apple
(integer) 1
> RPUSH fruit banana
(integer) 2
> RPOP fruit
"banana"
> LPOP fruit
"apple"
本文探讨Redis中列表类型的实现。
ziplist
使用数组和链表结构都可以实现列表类型。Redis中使用的是链表结构。下面是一种常见的链表实现方式adlist.h:
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
typedef struct list {
listNode *head;
listNode *tail;
void *(*dup)(void *ptr);
void (*free)(void *ptr);
int (*match)(void *ptr, void *key);
unsigned long len;
} list;
Redis内部使用该链表保存运行数据,如主服务下所有的从服务器信息。
但Redis并不使用该链表保存用户列表数据,因为它对内存管理不够友好:
(1)链表中每一个节点都占用独立的一块内存,导致内存碎片过多。
(2)链表节点中前后节点指针占用过多的额外内存。
读者可以思考一下,用什么结构可以比较好地解决上面的两个问题?没错,数组。ziplist是一种类似数组的紧凑型链表格式。它会申请一整块内存,在这个内存上存放该链表所有数据,这就是ziplist的设计思想。
定义
ziplist总体布局如下:
<zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend>
- zlbytes:uint32_t,记录整个ziplist占用的字节数,包括zlbytes占用的4字节。
- zltail:uint32_t,记录从ziplist起始位置到最后一个节点的偏移量,用于支持链表从尾部弹出或反向(从尾到头)遍历链表。
- zllen:uint16_t,记录节点数量,如果存在超过216-2个节点,则这个值设置为216-1,这时需要遍历整个ziplist获取真正的节点数量。
- zlend:uint8_t,一个特殊的标志节点,等于255,标志ziplist结尾。其他节点数据不会以255开头。
entry就是ziplist中保存的节点。entry的格式如下:
<prevlen> <encoding> <entry-data>
- entry-data:该节点元素,即节点存储的数据。
- prevlen:记录前驱节点长度,单位为字节,该属性长度为1字节或5字节。
① 如果前驱节点长度小于254,则使用1字节存储前驱节点长度。
② 否则,使用5字节,并且第一个字节固定为254,剩下4个字节存储前驱节点长度。 - encoding:代表当前节点元素的编码格式,包含编码类型和节点长度。一个ziplist中,不同节点元素的编码格式可以不同。编码格式规范如下:
① 00pppppp(pppppp代表encoding的低6位,下同):字符串编码,长度小于或等于63(26-1),长度存放在encoding的低6位中。
② 01pppppp:字符串编码, 长度小于或等于16383(214-1),长度存放在encoding的后6位和encoding后1字节中。
③ 10000000:字符串编码,长度大于16383(214-1),长度存放在encoding后4字节中。
④ 11000000:数值编码, 类型为int16_t,占用2字节。
⑤ 11010000:数值编码,类型为int32_t,占用4字节。
⑥ 11100000:数值编码,类型为int64_t,占用8字节。
⑦ 11110000:数值编码,使用3字节保存一个整数。
⑧ 11111110:数值编码,使用1字节保存一个整数。
⑨ 1111xxxx:使用encoding低4位存储一个整数,存储数值范围为0~12。该编码下encoding低4位的可用范围为0001~1101,encoding低4位减1为实际存储的值。
⑩ 11111111:255,ziplist结束节点。
注意第②、③种编码格式,除了encoding属性,还需要额外的空间存储节点元素长度。第⑨种格式也比较特殊,节点元素直接存放在encoding属性上。该编码是针对小数字的优化。这时entry-data为空。
字节序
encoding属性使用多个字节存储节点元素长度,这种多字节数据存储在计算机内存中或者进行网络传输时的字节顺序称为字节序,字节序有两种类型:大端字节序和小端字节序。
- 大端字节序:低字节数据保存在内存高地址位置,高字节数据保存在内存低地址位置。
- 小端字节序:低字节数据保存在内存低地址位置,高字节数据保存在内存高地址位置。
数值0X44332211的大端字节序和小端字节序存储方式如图2-1所示。
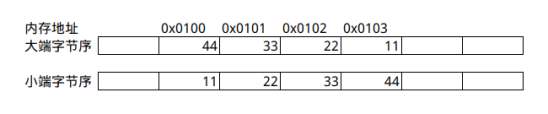
CPU处理指令通常是按照内存地址增长方向执行的。使用小端字节序,CPU可以先读取并处理低位字节,执行计算的借位、进位操作时效率更高。大端字节序则更符合人们的读写习惯。
ziplist采取的是小端字节序。
下面是Redis提供的一个简单例子:

- [0f 00 00 00]:zlbytes为15,代表整个ziplist占用15字节,注意该数值以小端字节序存储。
- [0c 00 00 00]:zltail为12,代表从ziplist起始位置到最后一个节点([02 f6])的偏移量。
- [02 00]:zllen为2,代表ziplist中有2个节点。
- [00 f3]:00代表前一个节点长度,f3使用了encoding第⑨种编码格式,存储数据为encoding低4位减1,即2。
- [02 f6]:02代表前一个节点长度为2字节,f5编码格式同上,存储数据为5。
- [ff]:结束标志节点。
ziplist是Redis中比较复杂的数据结构,希望读者结合上述属性说明和例子,理解ziplist中数据的存放格式。
操作分析
提示:本节以下代码如无特殊说明,均在ziplist.h、ziplist.c中。
ziplistFind函数负责在ziplist中查找元素:
unsigned char *ziplistFind(unsigned char *p, unsigned char *vstr, unsigned int vlen, unsigned int skip) {
int skipcnt = 0;
unsigned char vencoding = 0;
long long vll = 0;
while (p[0] != ZIP_END) {
unsigned int prevlensize, encoding, lensize, len;
unsigned char *q;
// [1]
ZIP_DECODE_PREVLENSIZE(p, prevlensize);
// [2]
ZIP_DECODE_LENGTH(p + prevlensize, encoding, lensize, len);
q = p + prevlensize + lensize;
if (skipcnt == 0) {
// [3]
if (ZIP_IS_STR(encoding)) {
if (len == vlen && memcmp(q, vstr, vlen) == 0) {
return p;
}
} else {
// [4]
if (vencoding == 0) {
if (!zipTryEncoding(vstr, vlen, &vll, &vencoding)) {
vencoding = UCHAR_MAX;
}
assert(vencoding);
}
// [5]
if (vencoding != UCHAR_MAX) {
long long ll = zipLoadInteger(q, encoding);
if (ll == vll) {
return p;
}
}
}
// [6]
skipcnt = skip;
} else {
skipcnt--;
}
// [7]
p = q + len;
}
return NULL;
}
参数说明:
- p:指定从ziplist哪个节点开始查找。
- vstr、vlen:待查找元素的内容和长度。
- skip:间隔多少个节点才执行一次元素对比操作。
【1】计算当前节点prevlen属性长度是1字节还是5字节,结果存放在prevlensize变量中。
【2】计算当前节点相关属性,结果存放在如下变量中:
encoding:节点编码格式。
lensize:额外存放节点元素长度的字节数,第②、③种格式的encoding编码需要额外的空间存放节点元素长度。
len:节点元素的长度。
【3】如果当前节点元素是字符串编码,则对比String的内容,若相等则返回。
【4】当前节点元素是数值编码,并且还没有对待查找内容vstr进行编码,则对它进行编码操作(编码操作只执行一次),编码后的数值存储在vll变量中。
【5】如果上一步编码成功(待查找内容也是数值),则对比编码后的结果,否则不需要对比编码结果。zipLoadInteger函数从节点元素中提取节点存储的数值,与上一步得到的vll变量进行对比。
【6】skipcnt不为0,直接跳过节点并将skipcnt减1,直到skipcnt为0才对比数据。
【7】p指向p + prevlensize + lensize + len(数据长度),得到下一个节点的起始位置。
提示:由于源码中部分函数太长,为了版面整洁,本书将其划分为多个代码段,并使用“// more”标志该函数后续还有其他代码段,请读者留意该标志。
下面看一下如何在ziplist中插入节点:
unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) {
...
// [1]
if (p[0] != ZIP_END) {
ZIP_DECODE_PREVLEN(p, prevlensize, prevlen);
} else {
unsigned char *ptail = ZIPLIST_ENTRY_TAIL(zl);
if (ptail[0] != ZIP_END) {
prevlen = zipRawEntryLength(ptail);
}
}
// [2]
if (zipTryEncoding(s,slen,&value,&encoding)) {
reqlen = zipIntSize(encoding);
} else {
reqlen = slen;
}
// [3]
reqlen += zipStorePrevEntryLength(NULL,prevlen);
reqlen += zipStoreEntryEncoding(NULL,encoding,slen);
// [4]
int forcelarge = 0;
nextdiff = (p[0] != ZIP_END) ? zipPrevLenByteDiff(p,reqlen) : 0;
if (nextdiff == -4 && reqlen < 4) {
nextdiff = 0;
forcelarge = 1;
}
// more
}
参数说明:
- zl:待插入ziplist。
- p:指向插入位置的后驱节点。
- s、slen:待插入元素的内容和长度。
【1】计算前驱节点长度并存放到prevlen变量中。
如果p没有指向ZIP_END,则可以直接取p节点的prevlen属性,否则需要通过ziplist.zltail找到前驱节点,再获取前驱节点的长度。
【2】对待插入元素的内容进行编码,并将内容的长度存放在reqlen变量中。
zipTryEncoding函数尝试将元素内容编码为数值,如果元素内容能编码为数值,则该函数返回1,这时value指向编码后的值,encoding存储对应编码格式,否则返回0。
【3】zipStorePrevEntryLength函数计算prevlen属性的长度(1字节或5字节)。
zipStoreEntryEncoding函数计算额外存放节点元素长度所需字节数(encoding编码中第②、③种格式)。reqlen变量值添加这两个函数的返回值后成为插入节点长度。
【4】zipPrevLenByteDiff函数计算后驱节点prevlen属性长度需调整多少个字节,结果存放在nextdiff变量中。
假如p指向节点为e2,而插入前e2的前驱节点为e1,e2的prevlen存储e1的长度。
插入后e2的前驱节点为插入节点,这时e2的prevlen应该存储插入节点长度,所以e2的prevlen需要修改。图2-2展示了一个简单示例。

从图2-2可以看到,后驱节点e2的prevlen属性长度从1变成了5,则nextdiff变量为4。
如果插入节点长度小于4,并且原后驱节点e2的prevlen属性长度为5,则这时设置forcelarge为1,代表强制保持后驱节点e2的prevlen属性长度不变。读者可以思考一下,为什么要这样设计?
继续分析__ziplistInsert函数:
unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) {
...
// [5]
offset = p-zl;
zl = ziplistResize(zl,curlen+reqlen+nextdiff);
p = zl+offset;
if (p[0] != ZIP_END) {
// [6]
memmove(p+reqlen,p-nextdiff,curlen-offset-1+nextdiff);
// [7]
if (forcelarge)
zipStorePrevEntryLengthLarge(p+reqlen,reqlen);
else
zipStorePrevEntryLength(p+reqlen,reqlen);
// [8]
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+reqlen);
// [9]
zipEntry(p+reqlen, &tail);
if (p[reqlen+tail.headersize+tail.len] != ZIP_END) {
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
}
} else {
// [10]
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(p-zl);
}
// [11]
if (nextdiff != 0) {
offset = p-zl;
zl = __ziplistCascadeUpdate(zl,p+reqlen);
p = zl+offset;
}
// [12]
p += zipStorePrevEntryLength(p,prevlen);
p += zipStoreEntryEncoding(p,encoding,slen);
if (ZIP_IS_STR(encoding)) {
memcpy(p,s,slen);
} else {
zipSaveInteger(p,value,encoding);
}
// [13]
ZIPLIST_INCR_LENGTH(zl,1);
return zl;
}
【5】重新为ziplist分配内存,主要是为插入节点申请空间。新ziplist的内存大小为curlen+reqlen+nextdiff(curlen变量为插入前ziplist长度)。将p重新赋值为zl+offset(offset变量为插入节点的偏移量),是因为ziplistResize函数可能会为ziplist申请新的内存地址。
下面针对存在后驱节点的场景进行处理。
【6】将插入位置后面所有的节点后移,为插入节点腾出空间。移动空间的起始地址为p-nextdiff,减去nextdiff是因为后驱节点的prevlen属性需要调整nextdiff长度。移动空间的长度为curlen-offset-1+nextdiff,减1是因为最后的结束标志节点已经在ziplistResize函数中设置了。
memmove是C语言提供的内存移动函数。
【7】修改后驱节点的prevlen属性。
【8】更新ziplist.zltail,将其加上reqlen的值。
【9】如果存在多个后驱节点,则ziplist.zltail还要加上nextdiff的值。
如果只有一个后驱节点,则不需要加上nextdiff,因为这时后驱节点大小变化了nextdiff,但后驱节点只移动了reqlen。
提示:zipEntry函数会将给定节点的所有信息赋值到zlentry结构体中。zlentry结构体用于在计算过程中存放节点信息,实际存储数据格式并不使用该结构体。读者不要被tail这个变量名误导,它只是指向插入节点的后驱节点,并不一定指向尾节点。
【10】这里针对不存在后驱节点的场景进行处理,只需更新最后一个节点偏移量ziplist.zltail。
【11】级联更新。
【12】写入插入数据。
【13】更新ziplist节点数量ziplist.zllen。
解释一下以下代码:
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+reqlen);
intrev32ifbe函数完成以下工作:如果主机使用的小端字节序,则不做处理。如果主机使用的大端字节序,则反转数据字节序(数据第1位与第4位、第2位与第3位交换),这样会将大端字节序数据转化为小端字节序,或者将小端字节序数据转化为大端字节序。
在上面的代码中,如果主机CPU使用的是小端字节序,则intrev32ifbe函数不做任何处理。
如果主机CPU使用的是大端字节序,则从内存取出数据后,先调用intrev32ifbe函数将数据转化为大端字节序后再计算。计算完成后,调用intrev32ifbe函数将数据转化为小端字节序后再存入内存。
级联更新
例2-1:
考虑一种极端场景,在ziplist的e2节点前插入一个新的节点ne,元素数据长度为254,如图2-3所示。

插入节点如图2-4所示。

插入节点后e2的prevlen属性长度需要更新为5字节。
注意e3的prevlen,插入前e2的长度为253,所以e3的prevlen属性长度为1字节,插入新节点后,e2的长度为257,那么e3的prevlen属性长度也要更新了,这就是级联更新。在极端情况下,e3后续的节点也要继续更新prevlen属性。
我们看一下级联更新的实现:
unsigned char *__ziplistCascadeUpdate(unsigned char *zl, unsigned char *p) {
size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), rawlen, rawlensize;
size_t offset, noffset, extra;
unsigned char *np;
zlentry cur, next;
// [1]
while (p[0] != ZIP_END) {
// [2]
zipEntry(p, &cur);
rawlen = cur.headersize + cur.len;
rawlensize = zipStorePrevEntryLength(NULL,rawlen);
if (p[rawlen] == ZIP_END) break;
// [3]
zipEntry(p+rawlen, &next);
if (next.prevrawlen == rawlen) break;
// [4]
if (next.prevrawlensize < rawlensize) {
// [5]
offset = p-zl;
extra = rawlensize-next.prevrawlensize;
zl = ziplistResize(zl,curlen+extra);
p = zl+offset;
// [6]
np = p+rawlen;
noffset = np-zl;
if ((zl+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))) != np) {
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+extra);
}
// [7]
memmove(np+rawlensize,
np+next.prevrawlensize,
curlen-noffset-next.prevrawlensize-1);
zipStorePrevEntryLength(np,rawlen);
// [8]
p += rawlen;
curlen += extra;
} else {
// [9]
if (next.prevrawlensize > rawlensize) {
zipStorePrevEntryLengthLarge(p+rawlen,rawlen);
} else {
// [10]
zipStorePrevEntryLength(p+rawlen,rawlen);
}
// [11]
break;
}
}
return zl;
}
参数说明:
- p:p指向插入节点的后驱节点,为了描述方便,下面将p指向的节点称为当前节点。
【1】如果遇到ZIP_END,则退出循环。
【2】如果下一个节点是ZIP_END,则退出。
rawlen变量为当前节点长度,rawlensize变量为当前节点长度占用的字节数。
p[rawlen]即p的后驱节点的第一个字节。
【3】计算后驱节点信息。如果后驱节点的prevlen等于当前节点的长度,则退出。
【4】假设存储当前节点长度需要使用actprevlen(1或者5)个字节,这里需要处理3种情况。情况1:后驱节点的prevlen属性长度小于actprevlen,这时需要扩容,如例2-1中的场景。
【5】重新为ziplist分配内存。
【6】如果后驱节点非ZIP_END,则需要修改ziplist.zltail属性。
【7】将当前节点后面所有的节点后移,腾出空间用来修改后驱节点的prevlen。
【8】将p指针指向后驱节点,继续处理后面节点的prevlen。
【9】情况2:后驱节点的prevlen属性长度大于actprevlen,这时需要缩容。为了不让级联更新继续下去,这时强制后驱节点的prevlen保持不变。
【10】情况3:后驱节点的prevlen属性长度等于actprevlen,只要修改后驱节点prevlen值,不需要调整ziplist的大小。
【11】情况2和情况3中级联更新不需要继续,退出。
回到上面__ziplistInsert函数中为什么要设置forcelarge为1的问题,这样是为了避免插入小节点时,导致级联更新现象的出现,所以强制保持后驱节点的prevlen属性长度不变。
从上面的分析我们可以看到,级联更新下的性能是非常糟糕的,而且代码复杂度也高,那么怎么解决这个问题呢?我们先看一下为什么需要使用prevlen这个属性?这是因为反向遍历时,每向前跨过一个节点,都必须知道前面这个节点的长度。
既然这样,我们把每个节点长度都保存一份到节点的最后位置,反向遍历时,直接从前一个节点的最后位置获取前一个节点的长度不就可以了吗?而且这样每个节点都是独立的,插入或删除节点都不会有级联更新的现象。基于这种设计,Redis作者设计另一种结构listpack。设计listpack的目的是取代ziplist,但是ziplist使用范围比较广,替换起来比较复杂,所以目前只应用在新增加的Stream结构中。等到我们分析Stream时再讨论listpack的设计。由此可见,优秀的设计并不是一蹴而就的。
ziplist提供常用函数如表2-1所示。
| 函数 | 作用 |
|---|---|
| ziplistNew | 创建一个空的ziplist |
| ziplistPush | 在ziplist头部或尾部添加元素 |
| ziplistInsert | 插入元素到ziplist指定位置 |
| ziplistFind | 查找给定的元素 |
| ziplistDelete | 删除给定节点 |
即使使用新的listpack格式,每插入一个新节点,也还可能需要进行两次内存拷贝。
(1)为整个链表分配新内存空间,主要是为新节点创建空间。
(2)将插入节点所有后驱节点后移,为插入节点腾出空间。
如果链表很长,则每次插入或删除节点时都需要进行大量的内存拷贝,这个性能是无法接受的,那么如何解决这个问题呢?这时就要用到quicklist了。
限于篇幅,关于quicklist内容,我们在下一文章分析。
本文内容摘自作者新书《Redis核心原理与实践》。本书通过深入分析Redis 6.0源码,总结了Redis核心功能的设计与实现。通过阅读本书,读者可以深入理解Redis内部机制及最新特性,并学习到Redis相关的数据结构与算法、Unix编程、存储系统设计,分布式系统架构等一系列知识。
经过该书编辑同意,我会继续在个人技术公众号(binecy)发布书中部分章节内容,作为书的预览内容,欢迎大家查阅,谢谢。
语雀平台预览:《Redis核心原理与实践》
京东链接