本文介绍SQL Server如何编译存储过程并使用计划缓存。如果你的应用程序完全没有用到存储过程,而是直接使用SQL语句提交请求,那么本文大部分内容也是有效的。但是关于动态SQL的编译会在后面章节介绍,这里重点关注让人头痛的存储过程问题。
什么是存储过程?
虽然这个问题有点愚蠢,但是实际的问题是:什么对象有自己的查询计划?SQL Server为下面四类对象创建查询计划:
1. 存储过程。
2. 标量用户自定义函数。
3. 多步表值函数。
4. 触发器
这里使用一个更加通用和严谨的技术术语“模组(modules)”来标识,但是由于存储过程的极其广泛的使用,所以这里还是保留原有称呼。
除了上面列举的四类对象之外,SQL Server不创建查询计划。特别是对视图和内联表值函数(inline-table functions),SQL Server并不创建查询计划,比如:
SELECT abc, def FROM myview
SELECT a, b, c FROM mytablefunc(9)
它们跟直接使用即席查询(ad-hoc queries)访问基础表没有什么区别。在编译这些查询时,SQL Server会把视图/函数展开成实际语句,并基于这些实际语句进行优化。
关于存储过程的结构,如果类似下面写法,那么意味着你实际上有两个过程,外层调用内层:
CREATE PROCECURE Outer_sp AS
...
EXEC Inner_sp
...
我猜大部分人会觉得Inner_sp和Outer_sp是独立的,确实如此。Outer_sp的执行计划并不包含Inner_sp,仅仅是调用它而已。但是有一个很类似的写法:
CREATE PROCEDURE Some_sp AS
DECLARE @sql nvarchar(MAX),
@params nvarchar(MAX)
SELECT @sql = 'SELECT ...'
...
EXEC sp_executesql @sql, @params, @par1, ...
需要知道的是,这种写法与嵌套存储过程没有区别。产生的SQL字符串“不”属于“Some_sp”,也不出现在Some_sp执行计划中的任何部分,但是它有一个关于自己的查询计划和缓存条目(cache entry)。这种方式适合于使用EXEC()执行的动态SQL或者使用sp_executesql执行的动态SQL语句。
SQL Server如何生成查询计划:
概述:
当你输入以CREATE PROCEDURE(或者CREATE FUNCTION、CREATE TRIGGER同理)的存储过程时,SQL Server会先判断代码语法是否正确,同时也会检查是否使用了不存在的列(但是如果你使用了不存在的表,编译依旧会通过,因为这里使用了一个叫推迟命名解析(deferred named resolution)的功能)。但是在这个阶段,SQL Server并不创建任何查询计划,而是仅存储查询文本在数据库中。
直到执行存储过程时,SQL Server才会对其创建执行计划。对于每个语句,SQL Server会从统计信息中查找针对这个查询,在对应表中的数据分布情况。通过这个信息得到关于执行这个语句的最佳预估方式,这个过程成为“优化(optimisation)”。当存储过程被编译一次之后,每个语句都被独自优化,并且不会分析后续步骤。这就衍生出一个很重要的 特性:优化器对运行时传入的变量毫不知晓。但是对于存储过程传入的参数,优化器是可以知道的。
参数和变量:
现在看看在Northwind库中的这三个存储过程:
USE Northwind
GO
CREATE PROCEDURE List_orders_1
AS
SELECT *
FROM Orders
WHERE OrderDate > '20000101'
GO
CREATE PROCEDURE List_orders_2 @fromdate DATETIME
AS
SELECT *
FROM Orders
WHERE OrderDate > @fromdate
GO
CREATE PROCEDURE List_orders_3 @fromdate DATETIME
AS
DECLARE @fromdate_copy DATETIME
SELECT @fromdate_copy = @fromdate
SELECT *
FROM Orders
WHERE OrderDate > @fromdate_copy
GO ---------------------------------------------------------------------------------------------------------------------------
注意,在生产环境中使用SELECT *并不是什么好的习惯。这里只是为了演示起见。
---------------------------------------------------------------------------------------------------------------------------
接下来按下面方式执行存储过程,并使用“包含实际执行计划”(或Ctrl+M再执行),语句及结果如下:
EXEC List_orders_1
EXEC List_orders_2 '20000101'
EXEC List_orders_3 '20000101'
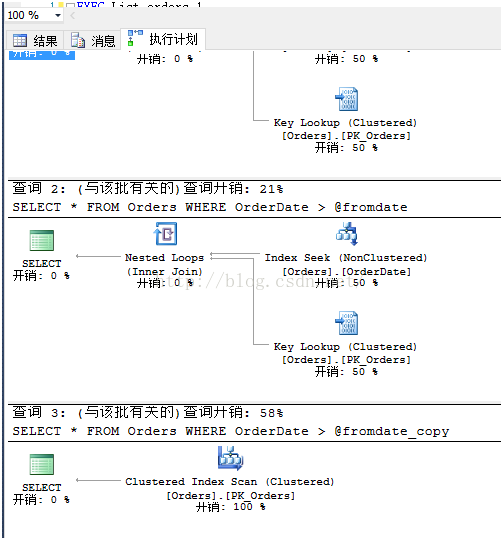
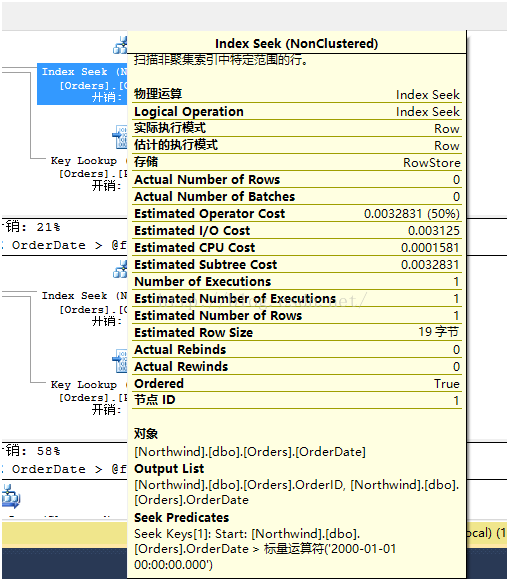
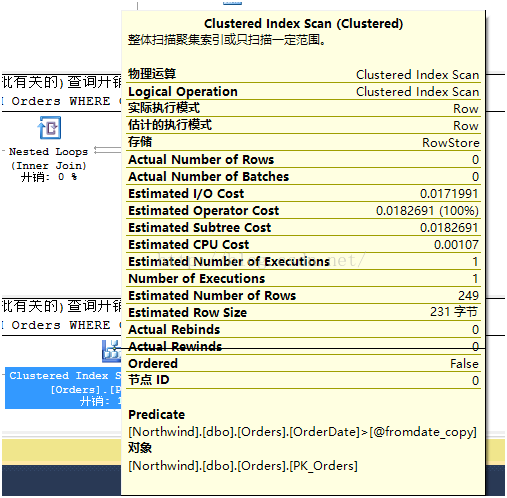
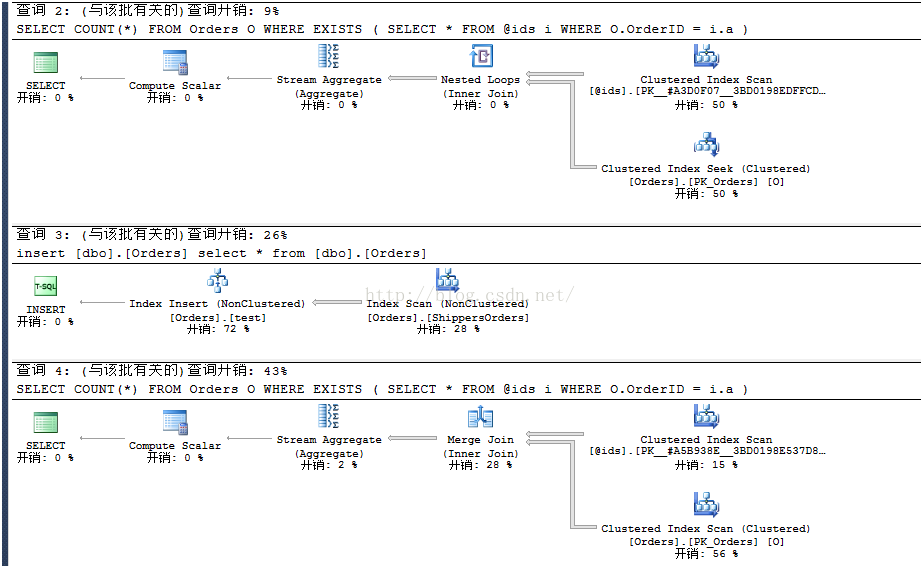
前两个存储过程的执行计划如上图“查询2”所示,使用了索引查找操作,而第三个存储过程使用的是聚集索引扫描操作,如上图“查询3”所示。此时SQL Server进行了全表扫描(注意,聚集索引的叶节点存储了数据本身,索引聚集索引扫描和表扫描是一样的),为什么会发生这种情况呢?为了明白优化器的决定,一般做法是检查影响的预估行数,如果把鼠标移到查找和扫描两个操作符上,可以看到下面两个结果:
查询1

查询2
查询3
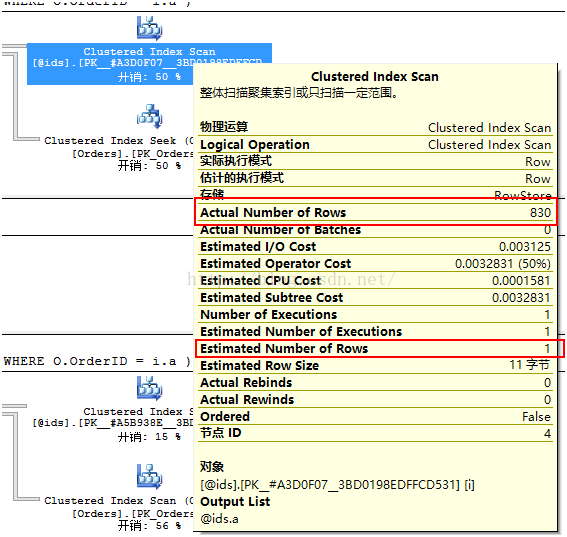
其中值得关注的是“预估影响行数”(Estimated Number of Rows)。对于前两个存储过程,SQL Server预估只会返回1行数据,但是对于第三个存储过程,预估返回249行。这个差异导致了优化器选择不同的执行计划。对于一个表返回少量数据而言,索引查找+键值查找(Key Lookup)是很好的策略,但是对于相对较大规模的返回结果而言,开销就会增加,此时SQL Server底层更愿意使用直接扫描一次全表来降低开销。对于返回表的大部分甚至全部行而言,表扫描/聚集索引扫描会更加高效。因为此时SQL Server只需要访问一次表数据,而查找加键值查找,数据页中的每一行都会触发一次访问。在Northwind数据库中的Orders表,有830行数据,而SQL Server预估要返回249行,所以它觉得扫描是最佳选择。
预估数据的出处?
前面说了为什么会出现不同的执行计划:因为预估数量的不同。但是这又仅仅引出了下一个问题:为什么会不同呢?这也是本系列的关键点之一。对于第一个存储过程,日期是常量,意味着SQL Server只需要考虑这个值的情况。通过查询Orders表的统计信息,即可知道预估行数。但是统计信息毕竟是表的取样数据,所以SQL Server不能确定查询是否有数据返回,所以它认为只返回1行数据。对于第二个存储过程,查询使用了一个变量,更准确地说是一个参数。当优化器进行优化时,SQL Server知道这个存储过程会传入2000-01-01这个值。但是并不知道后续操作,所以它也不确定后续是否真的会用这个参数值。尽管如此,优化器根据输入值计算出对应的预估行数,也和第一个存储过程一样,只有1行,这种策略叫做参数嗅探(parameter sniffing)。对于第三个存储过程,就有所不同了,输入值被复制到一个本地变量,但是在SQL Server产生执行计划时,它真不知道这个值最终会是怎么样子的,所以使用一个标准假设,也就是假设会有30%的命中率,830行的30%就是249行。针对这种情况,有一个变种情景,如下面的第四个存储过程:
USE Northwind
GO
CREATE PROCEDURE List_orders_4 @fromdate DATETIME = NULL
AS
IF @fromdate IS NULL
SELECT @fromdate = '19900101'
SELECT *
FROM Orders
WHERE OrderDate > @fromdate
在这个存储过程中,参数是可选的,如果不传参数,默认就是null,即返回所有订单数,也就是等价于EXEC List_orders_4,它的执行计划和第一、第二个存储过程一样。使用索引查找+键值查找,尽管返回所有订单数据。如果你查看索引查找操作符的属性,可以看到除了“实际影响行数”(actual number of rows)之外其他都和第二个存储过程一样。在编译这个存储过程时,SQL Server并不知道@fromdate值的改变,假设@fromdate值为NULL。因为在关系数据库中,NULL代表着“未知”,也就是说,如果@fromdate在运行过程中依旧是这个值的话,查询可能返回任意数据。如果SQL Server把这值作为最后的输入,那么它会构造一个只有常量的扫描操作而完全不需要访问表(可以使用SELECT * FROM Orders WHERE OrderDate > NULL 来检验)。但是SQL Server又不得不生成一个满足不管@fromdate在运行时传入什么值都能返回正确结果的执行计划。另外一方面,SQL Server没有义务创建一个对所有值都是最佳的执行计划,所以它假设没有任意值返回,SQL Server因此决定使用索引查找。(但是依旧是返回1行,因为SQL Server永远不会使用0行作为预估行数)这是一个关于参数嗅探的反效果的例子,在实践中,更加合理的方式已更改是改写成下面第五个存储过程的样子:
USE Northwind
GO
CREATE PROCEDURE List_orders_5 @fromdate DATETIME = NULL
AS
DECLARE @fromdate_copy DATETIME
SELECT @fromdate_copy = coalesce(@fromdate, '19900101')
SELECT *
FROM Orders
WHERE OrderDate > @fromdate_copy
如果你执行这个存储过程,会看到这次使用了聚集索引扫描操作。
关键点:
在本节中,提到了以下一些关键内容:
• 当一个查询包含一个常量时,SQL Server会完全信任这个常量,如果它从约束中推断出不会返回任何数据,甚至可以使用短路模式不访问底层表。
• 对于参数,SQL Server并不知道运行时的具体值,但是会在编译过程中“嗅探”输入值。
• 对于本地变量,SQL Server对此一无所知,所以使用标准假设。(这个假设依赖于语句的操作符和从唯一索引中推导出来的信息) 从中我们得出一个结论:如果你从一个存储过程中提取一个查询,并使用一个常量替换变量和参数,你可能实际上得到了一个不同的查询,这一点在后续小节介绍。
把查询计划放入缓存:
如果每一次存储过程被执行时,SQL Server都要编译(也就是优化和产生查询计划),那么对于SQL Server来说,会因为所有CPU资源被耗尽而带来巨大危机。但是实际上并不是所有系统都这样,因为这个并不适合所有系统。在大型的数据仓库里面,通常会有几百个复杂查询的、可能需要分钟级别才能运行完的查询在执行,这些即使每次都编译,也不会带来什么危险,反而有好处。但是对于有大量用于在短时间内执行大量存储过程的OLTP系统,这个问题就变得很现实了。
基于这个原因,SQL Server缓存存储过程的查询计划,以便下一次用户执行它的时候,能跳过编译阶段,然后直接执行。这个计划会驻留在缓存中,直到某些事件导致计划被移出缓存。常见的事件有:
• SQL Server 的缓冲池(buffer cache)已满,SQL Server需要把“过时”的内容清除出去。这个缓存池通常包含了数据和查询计划。
• 执行了ALTER PROC/PROCEDURE命令。
• 执行了对存储过程的sp_recompile命令。
• 执行了DBCC FREEPROCCACHE命令。
• SQL Server重启,因为缓冲池是存储在内存中,重启会清空内存。
• 使用sp_configure或SSMS修改了某些影响查询计划的配置参数。
一旦上面提到的事件被触发,在下一次执行存储过程的时候,新的查询计划就会被编译、优化然后创建。SQL Server重新“嗅探”参数的输入,如果这时候的参数值和之前的不同,那么查询计划也可能和之前的不同(意味着性能会有差异甚至巨大差异)。
但是也有一些时间不会影响整个存储过程的计划缓存,但是会触发存储过程内部某些语句的重编译。在下一次执行时,重编译就会触发。这种情况下就算存储过程已经开始执行也可能触发。常见的有:
• 语句中涉及的表定义被修改。
• 语句中涉及的表上的索引变更,包含使用ALTER INDEX或DBCC DBREINDEX重建索引。
• 语句涉及的表的统计信息更新或新建统计信息。这些统计信息可能被SQL Server自动创建和更新,也可能被DBA操作。
• 语句涉及的表被执行了sp_recompile。
提醒:SQL Server 2000中没有语句级别的重编译,只有整个存储过程的重编译。
上面列举的并不是完整的列表,但是应该注意到其中一个没提到的点:同一个存储过程不同参数的情况.也就是说,比如调用第二个存储过程:
EXEC List_orders_2 '19900101'
执行计划依旧使用OrderDate上的索引,尽管返回所有的订单数据.这个现象表明一个很重要的事实:存储过程首次执行时的参数值对后续的执行有非常大的影响.如果因为某些原因,第一次执行时的值非常不典型,那么对于后续的执行来说,缓存的查询计划可能并不合理,所以参数嗅探才会变得如此的重要.
不同设置的查询计划:
在缓存中,一个存储过程有一个查询计划是不是意味着所有人都可以用它?其实不是,本节介绍关于缓存中同一个存储过程也可能有多个查询计划.为了演示需要,下面构造一个特制的存储过程:
USE Northwind
GO
CREATE PROCEDURE List_orders_6
AS
SELECT *
FROM Orders
WHERE OrderDate > '12/01/1998'
GO
SET DATEFORMAT dmy
GO
EXEC List_orders_6
GO
SET DATEFORMAT mdy
GO
EXEC List_orders_6
GO
按上面方式,打开实际执行计划并运行,会发现第一个返回很多数据,而第二个没有数据.检查执行计划可以发现也完全不同.第一个执行使用了聚集索引扫描(对于返回大量数据来说是最佳方式),而第二个执行使用了索引查找+键值查找(对于没数据返回时是最佳方式)。
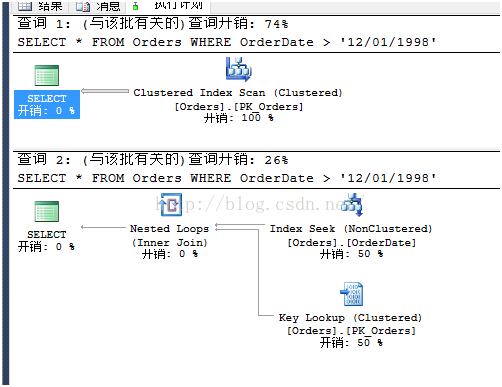
那么发生了什么事?是不是因为SET DATEFORMAT触发了重编译?不是,如果是这样就太不聪明了。在这个例子里面,执行是一个接一个地进行,但是也可以在由不同的用户使用不同的日期格式并行提交。注意存储过程的计划缓存并不绑定到特定会话或用户,但是全局来说是允许所有已连接的用户使用。
答案是SQL Server针对第二个存储过程的执行创建了第二个缓存条目。可以使用下面查询查看:
SELECT qs.plan_handle, a.attrlist
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) est
CROSS APPLY (SELECT epa.attribute + '=' + convert(nvarchar(127), epa.value) + ' '
FROM sys.dm_exec_plan_attributes(qs.plan_handle) epa
WHERE epa.is_cache_key = 1
ORDER BY epa.attribute
FOR XML PATH('')) AS a(attrlist)
WHERE est.objectid = object_id ('dbo.List_orders_6')
AND est.dbid = db_id('Northwind')
里面的DMV sys.dm_exec_query_stats分别针对当前每个查询记录一个计划缓存条目。如果存储过程有多个语句,那么会每个语句对应一行。这里比较需要注意的是sql_handle和plan_handle列,sql_handle用于确定缓存条目中是关于那个存储过程的,所以可以通过它去筛选掉其他 缓存中不相干的条目。同时可以使用plan_handle去查找查询计划。但是这个语句中查询查询计划的属性(cache keys),属性里面很多信息是相同的,这里挑出不同的展示,这个cache key是一个实际运行时的设置,可以显示出不同调用时的设置,里面大部分设置由SET命令控制,但是不是全部都这样。去掉不必要的信息之后,在我本机的结果如下:
1. plan_handle attrlist
2. ------------------------------------------------------------------------------------------- --------------------------------------------------
3. 0x05000D009D13BF5E30DF8F550300000001000000000000000000000000000000000000000000000000000000 compat_level=120 date_first=7 date_format=2
4. 0x05000D009D13BF5ED0678F590300000001000000000000000000000000000000000000000000000000000000 compat_level=120 date_first=7 date_format=1
具体的说明可以查阅联机丛书:https://msdn.microsoft.com/zh-cn/library/ms189472.aspx ,正如前面说的,这个存储过程是特制的,用于说明为什么查询计划会不同:不同的日期格式导致了不同的结果,又比如下面的调用方式:
USE Northwind
GO
EXEC sp_recompile List_orders_2
GO
SET DATEFORMAT dmy
GO
EXEC List_orders_2 '12/01/1998'
GO
SET DATEFORMAT mdy
GO
EXEC List_orders_2 '12/01/1998'
GO
第一句sp_recompile是为了刷掉旧的计划缓存确保对演示没有影响。这一次,参数值是一样的,但是由于日期格式不一样,所以第一个查询实际上是使用了1998-01-12而第二个查询实际上使用了1998-12-01。
cache key中非常重要的值是set_options。这是一个位掩码,标识一系列SET选项是否开启。如果两个连接使用了不同的SET选项,那么同一个存储过程就会使用不同的缓存条目,从而导致不同的执行计划,最终出现不同的性能差异。
其中一个转换SET_OPTIONS成可识别的值的方式是:
SELECT convert(binary(4), 4347)
默认设置:
SQL Server的默认值具有一定的历史遗留问题,时至今日一些默认值还是依赖于客户端的连接方式,部分值的明细如下:
|
|
使用ADO.NET/ODBC/OLE DB的应用程序 |
SSMS/查询分析器 |
SQLCMD/OSQL/BCP/SQL Agent |
ISQL/DB-Library |
|
ANSI_NULL_DFLT_ON |
ON |
ON |
ON |
OFF |
|
ANSI_NULLS |
ON |
ON |
ON |
OFF |
|
ANSI_PADDING |
ON |
ON |
ON |
OFF |
|
ANSI_WARNING |
ON |
ON |
ON |
OFF |
|
CONCATE_NULLS_YIELD_NULL |
ON |
ON |
ON |
OFF |
|
QUOTED_IDENTIFIER |
ON |
ON |
OFF |
OFF |
|
ARITHABORT |
OFF |
ON |
OFF |
OFF |
上面可以看到,如果你用应用程序连接SQL Server,那么ARITHABORT是OFF的,但是使用SSMS连接,却是ON,所以应用程序和SSMS执行的同一个存储过程也使用不同的缓存条目,但是SQL Server也会编译存储过程,嗅探当前参数值,然后得到可能和应用调用的存储过程不同的查询计划。那么现在差不多可以回答一开始的问题了。后续章节会做更加深入的探讨,但是最常见的关于“在应用程序中很慢,在SSMS中很快”的原因是参数嗅探和不同的ARITHABORT默认值。
对于SET选项,并不总是在运行时才会使用,当你创建一个存储过程、视图、表等等时,ANSI_NULLS和QUOTED_IDENTIFIER设置都会记录在对象中。也就是说如果你按下面方式运行:
SET ANSI_NULLS, QUOTED_IDENTIFIER OFF
go
CREATE PROCEDURE stupid @x int AS
IF @x = NULL PRINT "@x is NULL"
go
SET ANSI_NULLS, QUOTED_IDENTIFIER ON
go
EXEC stupid NULL
结果将是: @x is NULL
当QUOTED_IDENTIFIER为OFF时,双引号(“)被认为和单引号(')等价。当设为ON时,双引号被认为和中括号([])一样。另外,ANSI_PADDING是针对表上的每个列单独存储(数据类型为varchar/nvarchar/varbinary)。
这些选项和不同的默认值确实让人困惑,但还是有一些建议可用:
1. 记得上面表格中的前六个是仅仅为了向后兼容,所以建议设为OFF。虽然不是强制,但是通常而言,设为OFF很少会有问题。
2. 对于ARITHABORT,在SQL 2005及其后续版本中,ANSI_WARNING是否为ON也不对其有任何影响。在SSMS中,可以通过设置来修改。但是这回在使用SSMS连接SQL Server时改变ARITHABORT的默认设置,并且不能让你的应用跑得更快,但是最起码你不会因为在SSMS中得到不同的性能而感到困惑。
作为提醒,下面几个ANSI页的选项应该如下图所示,强烈 建议“不要修改”
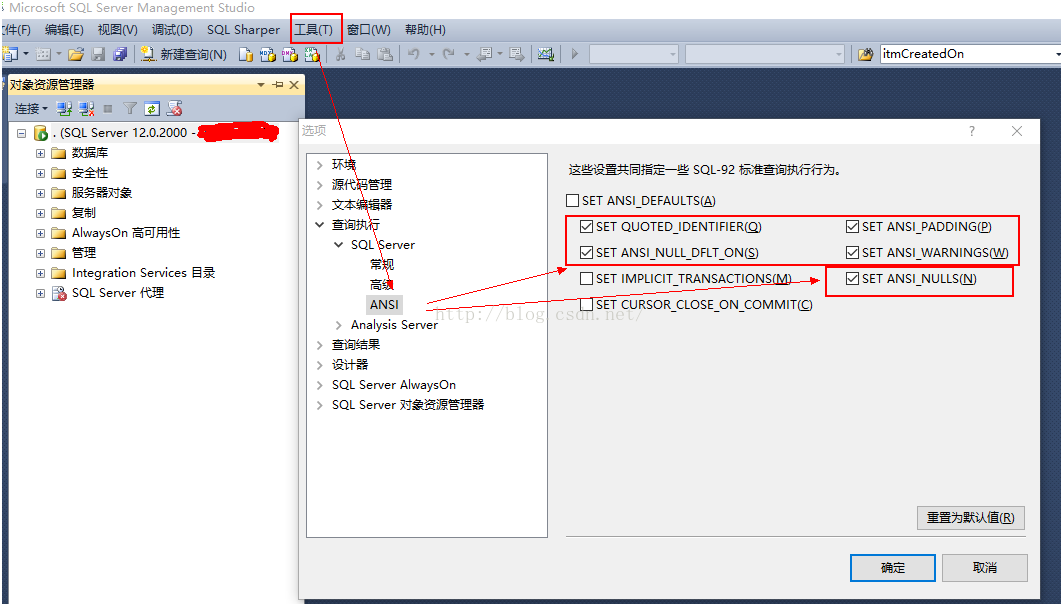
当使用SQLCMD和OSQL连接时,应该总是带上-I选项,让工具运行在“QUOTED_IDENTIFIER ON”下。相对的BCP参数为-q。但是对于SQL Agent而言就稍微麻烦一点。目前为止还没有找到对应的修改。所以如果你仅在SQL Agent中运行存储过程,问题不大,只需要把对应的SET命令写入存储过程中即可。但是如果你在SQL Agent要实现松散的批处理语句,你很可能因为QUOTED_IDENTIFER的不同默认值导致不同的执行计划。对于这类语句,建议在SQL Agent作业的第一步总带上SET QUOTED_IDENTIFIER ON。
前面看到了SET DATEFORMAT带来的影响,除了这个之外还有两个选项:LANGUAGE和DATEFIRST。默认语言是基于每个用户配置的,并且由服务器范围的配置来控制新用户的默认语言。如果每个用户的默认语言不同,则在cache keys中可能得到不同的查询计划。
对此我的建议是尽可能避免在SQL Server中存在独立于语言和日期设置。比如,总是使用统一的日期格式。
语句重编译的效果:
为了完整地了解SQL Server如何产生查询计划,我们必须研究独立的语句在重编译时是怎样的。前面提到过什么时候会触发语句级别的重编译,但是当时没有做深入研究。下面看一个人为特制的存储过程,但是它能很好地演示发生了什么:
USE Northwind
GO
CREATE PROCEDURE List_orders_7 @fromdate DATETIME,
@ix BIT
AS
SELECT @fromdate = dateadd(YEAR, 2, @fromdate)
SELECT *
FROM Orders
WHERE OrderDate > @fromdate
IF @ix = 1
CREATE INDEX test ON Orders (ShipVia)
SELECT *
FROM Orders
WHERE OrderDate > @fromdate
GO
EXEC List_orders_7 '19980101',
1
实际执行计划如下:
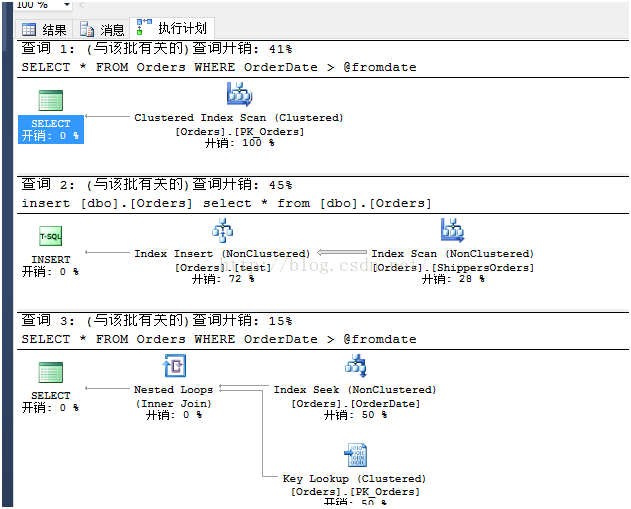
查看实际执行计划可以看到第一个SELECT语句使用了聚集索引扫描,因为SQL Server嗅探到值为“1998-01-01”并且预估查询会返回267行数据,使用索引查找+键值查找会过高开销,所以允许使用聚集索引扫描。但是SQL Server不知道@fromdate的值在下一个查询时会改变。而由于第二个语句在执行之前出现了CREATE INDEX语句,触发了第二个语句的重编译,从而使优化器重新优化第二个语句,在得知预估行数只有1行时,查询适合使用索引查找+键值查找操作。当出现语句重编译时,SQL Server重新嗅探当前参数值,并编译出一个更佳的查询计划。
重新执行存储过程,但是使用不同的参数:
EXEC List_orders_7 '19960101', 0
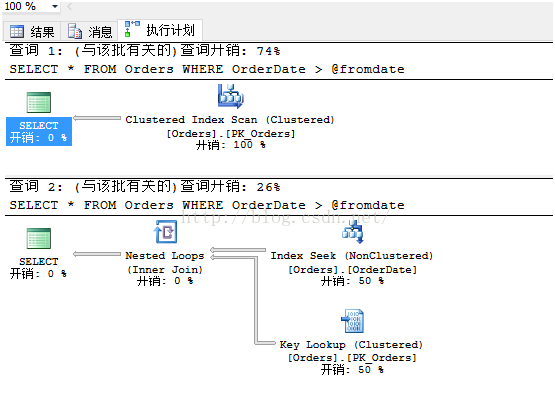
实际执行计划和第一次执行一样,在第二次执行中,第一个语句因为新加的索引导致了重编译,但是这次使用扫描操作是合理的,因为这次查找的是接近1/3的订单数据。但是现在第二个语句不再重编译了。虽然此时不是最佳的查询计划,但是它依旧使用上次执行的索引查找作为执行计划。
为了避免对后续的影响,我们需要清空演示时的效果:
USE Northwind
GO
DROP INDEX test
ON Orders
DROP PROCEDURE List_orders_7
正如一开始说的,这个存储过程是人为的,因为我希望以简洁的方式演示。在现实环境中,你的存储过程可能对不同的表使用相同的参数。DBA们会对其中一个表创建一个新索引,以触发这个表的重编译,而另外一个查询就不会。这里的关键点是:存储过程中的两个语句,可能由于嗅探不同的参数值而编译得出不同的查询计划。
当看到这里,我们可以把思维扩展到本地变量中:
USE Northwind
GO
CREATE PROCEDURE List_orders_8
AS
DECLARE @fromdate DATETIME
SELECT @fromdate = '20000101'
SELECT *
FROM Orders
WHERE OrderDate > @fromdate
CREATE INDEX test ON Orders (ShipVia)
SELECT *
FROM Orders
WHERE OrderDate > @fromdate
DROP INDEX test
ON Orders
GO
EXEC List_orders_8
GO
DROP PROCEDURE List_orders_8
执行计划如下:
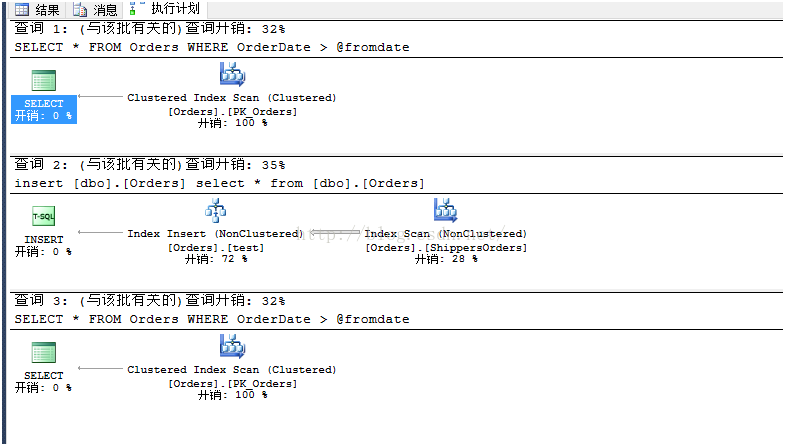
在这个例子中,所有SELECT语句都使用了聚集索引扫描,虽然第二个SELECT因为@fromdate的不可知而发生了重编译。但是也有例外,就是表变量。通常SQL Server对表变量的预估永远是1行,但是当重编译发生时,预估就不一样了:
USE Northwind
GO
CREATE PROCEDURE List_orders_9
AS
DECLARE @ids TABLE (a INT NOT NULL PRIMARY KEY)
INSERT @ids (a)
SELECT OrderID
FROM Orders
SELECT COUNT(*)
FROM Orders O
WHERE EXISTS (
SELECT *
FROM @ids i
WHERE O.OrderID = i.a
)
CREATE INDEX test ON Orders (ShipVia)
SELECT COUNT(*)
FROM Orders O
WHERE EXISTS (
SELECT *
FROM @ids i
WHERE O.OrderID = i.a
)
DROP INDEX test
ON Orders
GO
EXEC List_orders_9
GO
DROP PROCEDURE List_orders_9
执行计划及预估行数如下:
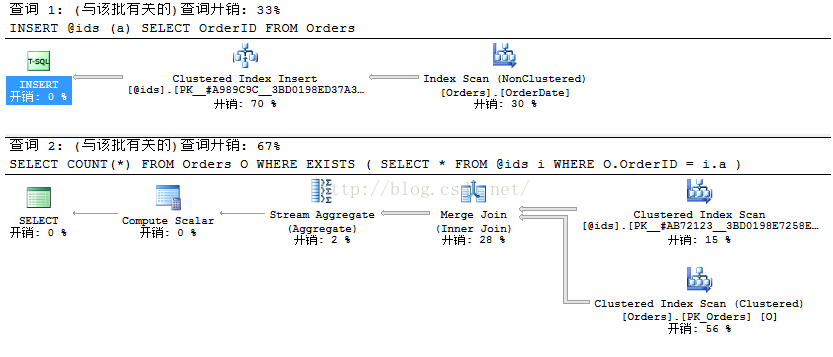
表变量重编译之前的预估行数

表变量重编译之后的预估行数
在第一个SELECT中,使用了嵌套循环联接关联Order表的聚集索引“查找”和表变量的聚集索引,表变量的预估行数为1,符合常规。在第二个SELECT中,Order表上使用了聚集索引“扫描”,并使用合并联接操作符与表变量关联,从图中可以看到表变量的预估行数变成了830行,因为这次触发了重编译,SQL Server嗅探出表变量上面的基数。
在某些情况下它就类似于参数嗅探。我(作者)曾经经历过一次在系统中一个关键存储过程突然建变慢,通过检查发现语句中的表变量预估行数为41,不幸的是,这个存储过程在每天运行中都是一个接一个地运行,所以预估1行会更加合理。
说到表变量,你可能会好奇从SQL 2008引入的“表值”参数。它们类似表变量的方式处理,但是是在作为参数时已被处理而不是在存储过程中被处理,所以SQL Server会按照超过1行的预估数量来编译优化,下面是例子:
USE Northwind
GO
CREATE TYPE temptype AS TABLE (a INT NOT NULL PRIMARY KEY)
GO
CREATE PROCEDURE List_orders_10 @ids temptype READONLY
AS
SELECT COUNT(*)
FROM Orders O
WHERE EXISTS (
SELECT *
FROM @ids i
WHERE O.OrderID = i.a
)
GO
DECLARE @ids temptype
INSERT @ids (a)
SELECT OrderID
FROM Orders
EXEC List_orders_10 @ids
GO
DROP PROCEDURE List_orders_10
DROP TYPE temptype
查询计划和List_orders_9的第二个SELECT一样,使用合并联接+Orders表的聚集索引扫描,同时可以看到在查询被编译时,是按830行预估行数进行。
小结:
在本文中,我们看到了SQL Server如何编译一个存储过程和实际参数值对编译的影响。我们也知道了SQL Server把查询计划放入缓存,以便后续被重用。另外也演示了在缓存中的同一个存储过程可以有多个条目。多个不同缓存键会导致同一个存储过程存在不同查询计划的潜在风险。最后就是某些影响缓存键的SET配置是历史遗留配置,不应该改动。
在实际应用中,最重要的SET选项是ARITHABORT,因为在应用程序和SSMS中,该选项的默认值是不同的。这也是为什么你的语句在应用程序中慢但是在SSMS中能运行良好的原因之一。应用程序使用了计划因为参数的实际值不同而被嗅探成不同的查询计划,而当你在SSMS中运行语句是,很可能没有ARITHABORT ON 的计划在计划缓存中,所以SQL Server会对当前参数值创建查询计划。因此,你可以通过在SSMS的执行界面中加上SET ARITHABORT OFF命令来验证这个问题。
而且极有可能你现在在应用程序中执行的慢查询在SSMS中也一样很慢,如果发生这种情况,你就可能是遇到了参数嗅探的情况。你可能还不知道怎么处理这种性能问题,但是在下一节我会讨论解决方案,然后回到之前的主题,对特定查询,也就是动态SQL的讨论。