前面已经提到过关于存储过程在SSMS中运行很快,但在应用程序中运行很慢的可能原因:因为ARITHABORT的不同选项会导致不同的缓存词目,另外由于SQL Server使用了参数嗅探导致获得了不同的执行计划。
虽然已经说明了这个现象的原因,但是还没解释:如何定位和解决这个问题?到目前为止,大家都知道了如何快速处理,如果这个问题很紧急,可以直接使用:
EXEC sp_recompile 存储过程名
前面提到过,这个操作会刷新计划缓存。下次存储过程被调用时,会产生新的查询计划。如果通过这种方式可以解决,那么认为这个已经不是问题了。
但是如果问题依旧,那么就需要做更深入的研究,并且不适合再用sp_recompile或者类似的方式去修改存储过程。另外请一直打开显示执行计划的选项以便用于对比和检查,最起码可以获取参数的值(可以通过右键执行计划→【显示执行计划XML】的方式在XML格式的执行计划中搜索ParameterList的值)。这是本节的主题。
在开始本节之前,给个小建议:修改SSMS的默认值,以便因为ARITHABORT的默认值带来困惑。建议把这个值设为OFF。但是与应用程序相同设置确实会有一些小缺点:你可能观察不到与参数嗅探有关的性能问题。但是如果你已经养成了都校验ARITHABORT ON和OFF的结果,那么这个问题就不成问题了。
获取必要的事实:
所有的性能侦测都需要事实。如果没有事实,那么就想一首歌里面说的:
We've been running round in our present stateHoping help will come from above
But even angels there make the same mistakes
重点在:即使天使也会犯错。如果没有充足的理由,即使天使也帮不了你。下面五个为处理关于参数嗅探性能问题的基础事实:
- 哪个语句慢?
- 不同的查询计划是怎样的?
- SQL Server嗅探了哪些参数?
- 表和索引的定义是怎样的?
- 统计信息的分布情况如何?实时更新吗?
这些方面也几乎可以覆盖所有查询优化的方面。只有第三点是特别针对参数嗅探问题的。另外,注意“复数”,你需要看两个执行计划:好的和坏的。下面章节将会逐个说明。
哪个语句慢?
首先我们得找到慢查询,大部分情况下,问题代码属于单语句级别。如果存储过程仅有一个语句,那么这步可以忽略。否则,可以使用Profiler找出来:其中Duration列可以显示出来。
另外一个可选方案就是使用由Lee Tudor编写的存储过程:sqltrace (http://www.sommarskog.se/sqlutil/sqltrace.html ),sqltrace使用SQL批语句作为参数,开始一个服务器级别的跟踪,运行这个批,然后停止跟踪,就可以得到所需的结果。里面也提供了很多选项可供输出。
在SSMS中获取查询计划和参数:
大部分情况下,在SSMS中运行存储过程可以很容易地得到查询计划,只要启用“包含实际执行计划”按钮即可。在不包含多个语句的情况下,这种方式很好用,但是在多语句的情况下,这种方式会显得很复杂。后面会演示替代方案。
一般情况下,你可能用下面这种方式运行:
SET ARITHABORT ON
go
EXEC that_very_sp 4711, 123, 1
go
SET ARITHABORT OFF
go
EXEC that_very_sp 4711, 123, 1
这里假设存储过程运行在默认配置上面。第一个执行可以得到好的查询计划——因为嗅探了参数并生成了执行计划,而第二次调用因为已经存在了执行计划在计划缓存中,所以依旧使用原有执行计划(这个计划不适合第二次调用)。关于获取缓存键,可以查看上一篇文章的相关内容:不同设置的查询计划 。
一旦你获得了执行计划,那么获得嗅探的参数值就容易了,右键查询计划最左边的操作符(一般是SELECT/INSERT等),然后选择【属性】,可以看到如下图的内容:
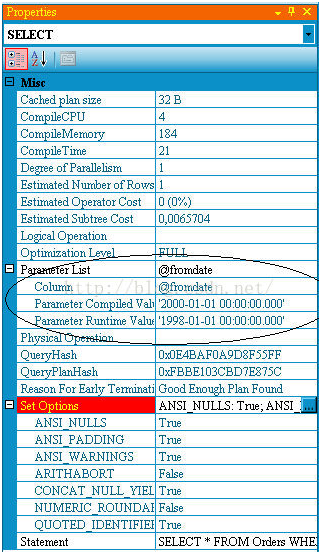
第一个【Parameter Compiled Values】是嗅探值,也就是引起问题的值。如果你了解你的应用程序和使用方式,可能马上从中知道问题。如果不是,最起码你可以知道程序调用存储过程时使用了这个可能有问题的值。
另外可以看到在缓存键中的不同的SET选项。但是注意在SQL 2005中的bug,但是这个跟SSMS的版本没关系。
虽然SSMS提供了很好的研究查询计划的接口,但是我还是建议使用一个更好的插件:SQL Sentry Plan Explorer ,这个工具允许你从不同的方式查看查询计划,并且很容易地在大量批语句中定位。
当你研究一个查询计划时,不仅仅要研究开销的百分比,还要研究箭头的粗细。箭头越粗,传入到下一个操作符的数据量越大。实际上,我(作者)很少完全关注在操作符的开销百分比上。因为他们总是预估的,可能会偏离很远。
从计划缓存中直接获取查询计划和参数:
从实践来说,从SSMS中不会总是那么轻易就能获取到查询计划和嗅探值。特别是次优执行计划可能由于会运行很久导致你接受不了,或者存储过程由于包含了太多语句导致在SSMS中看起来很乱。更麻烦的是存储过程以循环方式执行,使得在SSMS中查看查询计划变得几乎不可能。
对此,其中一个方法是从计划 缓存中直接获取查询计划及其参数。这种方式很方便,但是也有一个明显的限制:你能获取的仅仅是预估执行计划。而实际影响行数和实际执行次数这两个用于分析为什么执行计划很差的重要因素却被丢失了。
查询语句:
下面这个语句用于返回计划缓存中存储过程的语句、嗅探值和查询计划:
DECLARE @dbname NVARCHAR(256),
@procname NVARCHAR(256)
SELECT @dbname = 'Northwind',
@procname = 'dbo.List_orders_11';
WITH basedata
AS (
SELECT qs.statement_start_offset / 2 AS stmt_start,
qs.statement_end_offset / 2 AS stmt_end,
est.encrypted AS isencrypted,
est.TEXT AS sqltext,
epa.value AS set_options,
qp.query_plan,
charindex('<ParameterList>', qp.query_plan) + len('<ParameterList>') AS paramstart,
charindex('</ParameterList>', qp.query_plan) AS paramend
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) est
CROSS APPLY sys.dm_exec_text_query_plan(qs.plan_handle, qs.statement_start_offset, qs.statement_end_offset) qp
CROSS APPLY sys.dm_exec_plan_attributes(qs.plan_handle) epa
WHERE est.objectid = object_id(@procname)
AND est.dbid = db_id(@dbname)
AND epa.attribute = 'set_options'
),
next_level
AS (
SELECT stmt_start,
set_options,
query_plan,
CASE
WHEN isencrypted = 1
THEN '-- ENCRYPTED'
WHEN stmt_start >= 0
THEN substring(sqltext, stmt_start + 1, CASE stmt_end
WHEN 0
THEN datalength(sqltext)
ELSE stmt_end - stmt_start + 1
END)
END AS Statement,
CASE
WHEN paramend > paramstart
THEN CAST(substring(query_plan, paramstart, paramend - paramstart) AS XML)
END AS params
FROM basedata
)
SELECT set_options AS [SET],
n.stmt_start AS Pos,
n.Statement,
CR.c.value('@Column', 'nvarchar(128)') AS Parameter,
CR.c.value('@ParameterCompiledValue', 'nvarchar(128)') AS [Sniffed Value],
CAST(query_plan AS XML) AS [Query plan]
FROM next_level n
CROSS APPLY n.params.nodes('ColumnReference') AS CR(c)
ORDER BY n.set_options,
n.stmt_start,
Parameter
如果再次之前你从来没用过DMVs,估计对你而言会有点难懂。但是为了把注意力集中在我们的主题上。在这里需要提醒的是语句中需要制定数据库和存储过程名。
结果输出:
为了检查上面语句的输出情况,可以使用下面这个定制的存储过程:
USE Northwind
GO
CREATE PROCEDURE List_orders_11 @fromdate DATETIME,
@custid NCHAR(5)
AS
SELECT @fromdate = dateadd(YEAR, 2, @fromdate)
SELECT *
FROM Orders
WHERE OrderDate > @fromdate
AND CustomerID = @custid
IF @custid = 'ALFKI'
CREATE INDEX test ON Orders (ShipVia)
SELECT *
FROM Orders
WHERE CustomerID = @custid
AND OrderDate > @fromdate
IF @custid = 'ALFKI'
DROP INDEX test
ON Orders
GO
SET ARITHABORT ON
EXEC List_orders_11 '19980101',
'ALFKI'
GO
SET ARITHABORT OFF
EXEC List_orders_11 '19970101',
'BERGS'
然后运行上面的获取查询计划的语句,可以得到类似下面的效果:

其中里面有几列:
- SET——表示查询计划中set_options属性。正如前面提到的,这是一个位掩码。上图中可以看到两个值:251 为默认设置,4347为默认设置+ARITHABORT ON。如果看到其他值,可以用作者编写的一个函数反编译:setoptions 。
- Pos——表示该语句在存储过程的起始位置,从存储过程创建语句起算,包括任何CREATE PROCEDURE之前的注释。虽然大部分情况下作用不大,但是可以看到语句在存储过程中的出现顺序。
- Statement——SQL语句,但是注意对于每个参数,都会重复一次。
- Parameter——参数名,仅列出语句中出现的参数。也就是说,如果该查询语句没有使用到的参数,是不会出现在这里的。
- Sniffed Value——在编译时的参数值,也就是在嗅探优化并产生查询计划的参数值。因为这是从计划缓存中获取的信息,所以这里的值并不是实际参数值,从上图中可以看到,对于不同的语句可能会出现不同的参数值。
- Query Plan——对应的预估执行计划。
从Trace文件中获取查询计划和参数:
除了上面提到的内容之外,还可以从Trace文件中获取应用程序或SSMS中的查询计划。在Trace中,可以有几个Showplan事件可供选择。其中最通用的是Showplan XML Statistics Profile,可以提供在SSMS中获取实际执行计划的结果。
但是由于某些原因,使用跟踪几乎不是好的方式。因为这种跟踪会触发服务器的负载增加。因为trace的原理决定了,即使你指定了单独的spid,也需要触发所有进程产生所需的事件,然后再过滤,所以负载还是很高。
从SQL Server 2008 开始,引入了Extended Events,可以用于获取查询计划,这部分本人(译者)会在后续添加。原文中作者并未做介绍。
获取表和索引的定义:
这里假设读者已经知道如何获取表的定义,可以使用脚本或者sp_help获取,所以这里只介绍索引定义。可以使用脚本或者sp_helpindex获取,但是脚本很笨重,而sp_helpindex有不支持SQL 2005及后续版本加入的 新功能,那么下面这个语句可以很大程度帮到忙:
DECLARE @tbl NVARCHAR(265)
SELECT @tbl = 'Orders'
SELECT o.NAME,
i.index_id,
i.NAME,
i.type_desc,
substring(ikey.cols, 3, len(ikey.cols)) AS key_cols,
substring(inc.cols, 3, len(inc.cols)) AS included_cols,
stats_date(o.object_id, i.index_id) AS stats_date,
i.filter_definition
FROM sys.objects o
JOIN sys.indexes i
ON i.object_id = o.object_id
CROSS APPLY (
SELECT ', ' + c.NAME + CASE ic.is_descending_key
WHEN 1
THEN ' DESC'
ELSE ''
END
FROM sys.index_columns ic
JOIN sys.columns c
ON ic.object_id = c.object_id
AND ic.column_id = c.column_id
WHERE ic.object_id = i.object_id
AND ic.index_id = i.index_id
AND ic.is_included_column = 0
ORDER BY ic.key_ordinal
FOR XML PATH('')
) AS ikey(cols)
OUTER APPLY (
SELECT ', ' + c.NAME
FROM sys.index_columns ic
JOIN sys.columns c
ON ic.object_id = c.object_id
AND ic.column_id = c.column_id
WHERE ic.object_id = i.object_id
AND ic.index_id = i.index_id
AND ic.is_included_column = 1
ORDER BY ic.index_column_id
FOR XML PATH('')
) AS inc(cols)
WHERE o.NAME = @tbl
AND i.type IN (
1,
2
)
ORDER BY o.NAME,
i.index_id
这个语句仅用于常规关系型索引,不适合XML索引和空间索引。
获取统计信息相关信息:
可以使用下面语句获取表上所有统计信息的情况:
DECLARE @tbl NVARCHAR(265)
SELECT @tbl = 'Orders'
SELECT o.NAME,
s.stats_id,
s.NAME,
s.auto_created,
s.user_created,
substring(scols.cols, 3, len(scols.cols)) AS stat_cols,
stats_date(o.object_id, s.stats_id) AS stats_date,
s.filter_definition
FROM sys.objects o
JOIN sys.stats s
ON s.object_id = o.object_id
CROSS APPLY (
SELECT ', ' + c.NAME
FROM sys.stats_columns sc
JOIN sys.columns c
ON sc.object_id = c.object_id
AND sc.column_id = c.column_id
WHERE sc.object_id = s.object_id
AND sc.stats_id = s.stats_id
ORDER BY sc.stats_column_id
FOR XML PATH('')
) AS scols(cols)
WHERE o.NAME = @tbl
ORDER BY o.NAME,
s.stats_id
其中列stats_date返回统计信息最近更新时间。如果这个时间已经过去很久,那么统计信息可能已经过时。参数嗅探问题的根源通常不是统计信息过时,但是也应该检查一下。需要记住的是,统计信息的列如果是单调递增——如ID、date列,那么会很快过时,因为语句通常获取最近插入的数据,在统计信息的直方图中,记录的却通常是旧的数据。关于直方图会在后续介绍。
如果你认为统计信息过时,可以执行下面语句:
UPDATE STATISTICS 表名 WITH FULLSCAN, INDEX
这个语句通过完整扫描,更新表上所有的索引的统计信息。FULLSCAN并非必须,但是简单取样(默认值)的统计信息更新却经常会出现问题。限制统计信息在索引上的更新可以大幅度降低执行时间,因为SQL Server会对每个非聚集索引都扫描一次。
除了更新表上的全部索引,也可以用下面语句更新某个索引:
UPDATE STATISTICS tbl indexname WITH FULLSCAN
注意:在表名和索引名之间没有句号,只有空格。
如果是统计信息过时导致的性能问题,通常在更新统计信息之后,就可以发现应用程序的性能马上就得到提升。因为统计信息的更新会触发重编译,使得存储过程会对参数重新嗅探并产生更好的执行计划。
为了检查索引的统计信息情况,可以使用DBCC SHOW_STATITICS命令。这个命令需要两个参数,第一个是表名,第二个参数是索引或统计信息的名称,但是第二个参数也可以是列名,比如:
DBCC SHOW_STATISTICS (Orders, OrderDate)
下面是结果中第三个结果集的截图,这个是统计信息直方图的内容,直方图反映了表上数据的数据分布情况。

图中说明,表里面有一行数据,OrderDate等于1996-07-04。并且有一行数据属于1996-07-05到1996-07-07,有两行数据的OrderDate为1996-07-08。(因为RANGE_ROWS是1 而EQ_ROWS是2。)然后在Northwind库中的这个表的对应列的统计信息中,有188步长。直方图的步长永远不会超过200步。关于统计信息,可以查阅本人(译者)的文章:全废话SQL Server统计信息(2)——统计信息基础
小结:
本节主要演示了如何获取侦测性能问题的必要信息,下一节会介绍一些修复参数嗅探问题的例子。