作业来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3159
爬取豆瓣高评分电影影评
1.首先分析网页
在豆瓣网站中,需要浏览影评,是需要用户登录的;因此,要爬取影评网页,就需要注册用户、登录,捉取cookie,模拟用户登录。

mport requests from lxml import etree session = requests.Session() for id in range(0,251,25): URL = 'http://movie.douban.com/top250/?start=' + str(id) req = session.get(URL) req.encoding = 'utf8' # 设置网页编码格式 root=etree.HTML(req.content) #将request.content 转化为 Element items = root.xpath('//ol/li/div[@class="item"]') for item in items: rank,name,alias,rating_num,quote,url = "","","","","","" try: url = item.xpath('./div[@class="pic"]/a/@href')[0] rank = item.xpath('./div[@class="pic"]/em/text()')[0] title = item.xpath('./div[@class="info"]//a/span[@class="title"]/text()') name = title[0].encode('gb2312','ignore').decode('gb2312') alias = title[1].encode('gb2312','ignore').decode('gb2312') if len(title)==2 else "" rating_num = item.xpath('.//div[@class="bd"]//span[@class="rating_num"]/text()')[0] quote_tag = item.xpath('.//div[@class="bd"]//span[@class="inq"]') if len(quote_tag) is not 0: quote = quote_tag[0].text.encode('gb2312','ignore').decode('gb2312').replace('xa0','') print(rank,rating_num,quote) print(name.encode('gb2312','ignore').decode('gb2312') ,alias.encode('gb2312','ignore').decode('gb2312') .replace('/',',')) except: print('faild!') pass
2.获取每一部电影的信息
def get_html(web_url): # 爬虫获取网页没啥好说的 header = { "User-Agent":"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16"} html = requests.get(url=web_url, headers=header).text#不加text返回的是response,加了返回的是字符串 Soup = BeautifulSoup(html, "lxml") data = Soup.find("ol").find_all("li") # 还是有一点要说,就是返回的信息最好只有你需要的那部分,所以这里进行了筛选 return data
requests.get()函数,会根据参数中url的链接,返回response对象
.text会将response对象转换成str类型
find_all()函数,会将html文本中的ol标签下的每一个li标签中的内容筛选出来
3.pipelinemysql输入到数据库中:
先在mysql中创建数据库与表,表的属性应与要插入的数据保持一致
连接数据库db = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd=PWD, db='douban',charset='utf8')
创建游标cur = db.cursor()
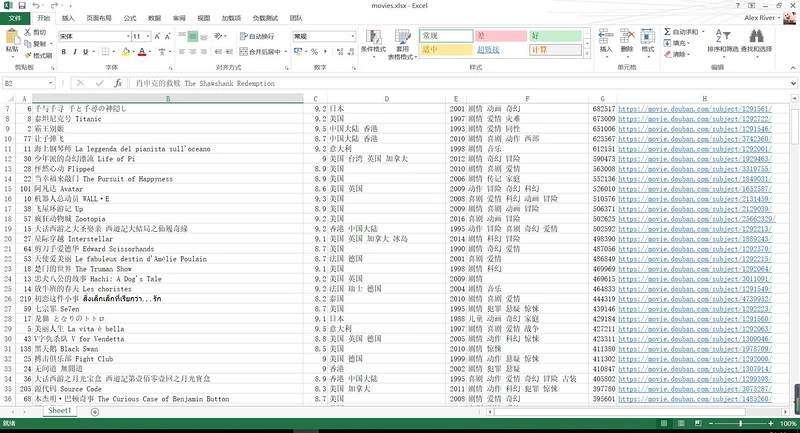
将获取的电影信息导入数据库
sql = "INSERT INTO test(rank, NAME, score, country, year, " "category, votes, douban_url) values(%s,%s,%s,%s,%s,%s,%s,%s)" try: cur.executemany(sql, movies_info) db.commit() except Exception as e: print("Error:", e) db.rollback()
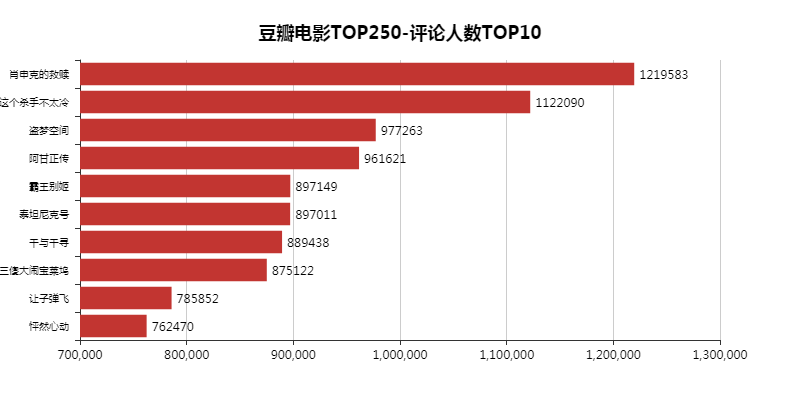
4.分析评论人数top10的数据生成图表
5.主要代码
importscrapy fromscrapy importSpider fromdoubanTop250.items importDoubantop250Item classDoubanSpider(scrapy.Spider): name = 'douban' allowed_domains = ['douban.com'] start_urls = ['https://movie.douban.com/top250/'] defparse(self, response): lis = response.css('.info') forli inlis: item = Doubantop250Item() # 利用CSS选择器获取信息 name = li.css('.hd span::text').extract() title = ''.join(name) info = li.css('p::text').extract()[1].replace('n', '').strip() score = li.css('.rating_num::text').extract_first() people = li.css('.star span::text').extract()[1] words = li.css('.inq::text').extract_first() # 生成字典 item['title'] = title item['info'] = info item['score'] = score item['people'] = people item['words'] = words yielditem # 获取下一页链接,并进入下一页 next = response.css('.next a::attr(href)').extract_first() ifnext: url = response.urljoin(next) yieldscrapy.Request(url=url, callback=self.parse) pass 生成的items.py文件,是保存爬取数据的容器,代码修改如下。 importscrapy classDoubantop250Item(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field() info = scrapy.Field() score = scrapy.Field() people = scrapy.Field() words = scrapy.Field()