爬虫环境配置
爬虫环境配置,主要安装爬虫所需要的软件以及包含库
软件:
Anaconda 库环境支持软件
Python3
Jupyter / jupyter lab pythonIDE
Pycharm pythonIDE
相关库安装:
1 请求库 向浏览器发送请求
2 解析库 解析服务器返回数据,查找,匹配,提取数据
3 数据库 存储爬取的数据
4 存储库 使用python支持存数据库的库实现对数据库的读写
5 web库 构建简单的web网络夫区,搭建api接口,供代理池使用
6 爬虫框架 大型的爬虫需要爬虫框架支持
7 部署库 用来将爬虫部署到多机, 实现分布式爬虫
1请求库安装
requests请求库
pip install requests
第三方的请求库,用来向服务器发送数据,发起请求
1.2selenium 自动化测试工具
Pip install selenium
Selenium 用来驱动浏览器执行模拟浏览的动作,模拟点击,下拉等。
对于使用js渲染的页面可以有效的抓取
验证安装是否成功:
在python环境内 import selenium 无报错即可
1.3chrome driver 驱动安装
Selenium 自动化测试工具,可以模拟浏览器进行模拟人工的操作,因此需要可以模拟操作的浏览器,即google的chrome浏览器。
但是,selenium不能直接驱动chrome进行模拟操作,因此需要安装配置单独的浏览器驱动来通过chromedriver驱动 浏览器chrome
在chrome官网下载自己的chrome对应版本的chromedriver, 将单独的chromedriver.exe 文放置的爬虫环境的script文件夹中, 该文件夹要包含在本机的环境变量中,
淘宝镜像地址:http://npm.taobao.org/mirrors/chromedriver/
验证安装:cmd中输入 chromedriver 有下列输出即可

爬虫环境下:
From selenium import webdriver
Browser = webdriver.Chrome()
出现chrome的空白弹窗即可
1.4phantomjs安装
Selenium在驱动浏览器的是时候会打开浏览器, 加载慢不方便, 因此需要一个无弹窗的后台模拟浏览器,加载数据,实现命令行的友好操作。
官网下载phantomjs http://phantomjs.org/download.html
官网文档:http://phantomjs.org/api/
下载后的bin文件夹中有phantomjs.exe文件, 将该文件同样放置在爬虫环境中的script文件夹中(该路径要配置在环境变量中)
验证安装cmd中:phantomjs 无报错即可

1.5 aiohttp 异步请求库
Request http 请求库是单步的请求库,每次只能发起一个请求并等待服务器回应,使用该库在大型的爬虫中会非常浪费时间以及资源。故此需要一个支持同时发起多个请求的请求库,aiohttp就可以实现异步请求。
安装 pip install aiohttp
验证: python环境下 import aiohttp 无报错即可
字符编码检测库: cchardet DNS解析加速库: aiodns
2解析库安装
解析库:发起请求完毕后,服务器会返回数据,要从返回的网页数据中提取数据就需要解析库。
提取信息方式:
正则匹配
解析信息方式:
Xpath 解析
Css 选择器解析
常用的解析库:
Beautifulsoup、 ,lxml、puquery
2.1 lxml 解析库安装
Lxml解析库支持HTML解析,支持xpath解析,解析效率较高
安装:
Pip install lxml
2.2 beautifulsoup 解析库安装
Beautifulsoup 库支持html和xml解析, =可以快捷的从网页中提取数据,有强大的api以及多种解析方式是
·安装:
Pip install beautifulsoup4
2.3 pyquery 解析库安装
Pyquery支持Jquery和HTML解析, 支持CSS选择器,使用简单
安装:
Pip install pyquery
3 数据库软件安装
安装不同类型的数据库,用来高效的存储爬取的数据
主要的数据库包括:
关系型数据库:mysql
面向文档的非关系型数据库: mongodb
非关系型key-value 数据库 redis
3.1 mysql安装
官网下载mysql安装软件 https://dev.mysql.com/downloads/mysql/ 注意版本的对应
安装参照其他详细教程
注意:
安装的时候基本上一路next,注意安装workbench 用来对数据库可视化交互
安装的过程中本地的mysql服务会创建密码,要记住密码
验证安装:
在电脑的服务中会有mysql57服务,证明安装成功

保证该服务是自动启动运行的状态。
3.2 mongodb 安装
官网下载mongofb4.0
现在要求注册以才能下载安装文件,因此要先在官网注册账户,安装的时候一路next设置密码即可
验证安装;
在服务中会有mondb的服务正在运行表示安装成功

3.3 redis 安装
在redis的guithub下载安装源文件即可
https ://github.com.uglide/RedisDesktopManager/releases 一路next即可
验证安装:
在服务中同样有redis服务表示安装成功

安装redis desktop 可视化管理工具,用来管理redis数据库
在github 搜索redis desktop 选择第一个uglide/RedisDesktopManager 在他的release 发行版本中选择稳定的版本按章,一路next即可。
安装完成后配置本地连接;
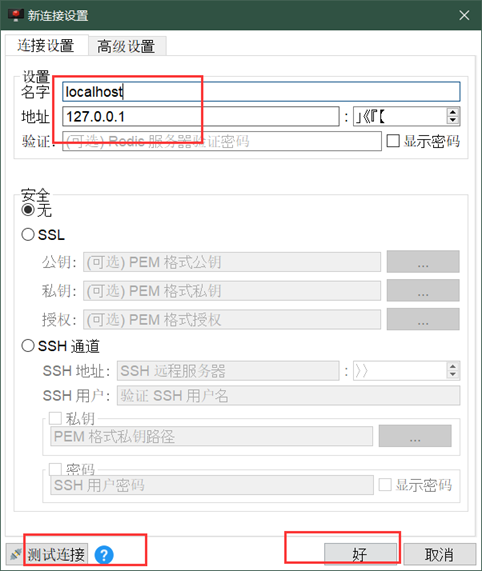
测试成功即可
4 python 交互存储库安装
安装完成数据库以后,python和数据库交互的时候需要相关的库支持
包括;
Pymysql 库
PyMongo 库
Redis-py 库
4.1 以上支持库的安装 pip install 库名 即可
4.2 安装redisdump
Redisdump 用于redis的数据导入导出工具基于ruby实现, 需要安装ruby
Rubyinstaller下载地址https://rubyinstaller.org/downloads/ 下载完成后根据提示配置基础运行环境
配置完成后在ruby控制台运行 gem install redis-dump
安装完成后运行redis-dump 以及redis-load 无报错即可
5 web库安装
在爬虫中使用web库搭建API接口,配合redis数据库搭建代理池, 通过API 接口拿到代理,简单快捷
主要的web库包括;
Flask: 轻量级web支持库 利用flask+redis搭建代理池
当然也可以快捷购买代理
安装;
pip install flask
Tornado 支持异步请求的web框架, 效率高
安装:
Pip install tornado
这两个web框架,二选一即可
6 app爬取库安装
为了抓取app的数据, 需要app支持库来加载app页面
6.1 抓包工具 Charles 安装
要加载app中的页面数据,需要获取数据,app的数据的请求一般是通过服务器的专用请求接口来实现的,需要抓包工具来抓取数据,为了实现规模化的自动采集,同样需要自动化测试版工具来实现对手机中app自动化操作,主要的app自动化控制操作工具有appium 和国产的airtest
Charles安装:
官网地址; https://www.charlesproxy.com/download/
Charles需要付费
Charles激活:
Registered Name:https://zhile.io
License Key: 48891cf209c6d32bf4
安装完成以后需要配置证书
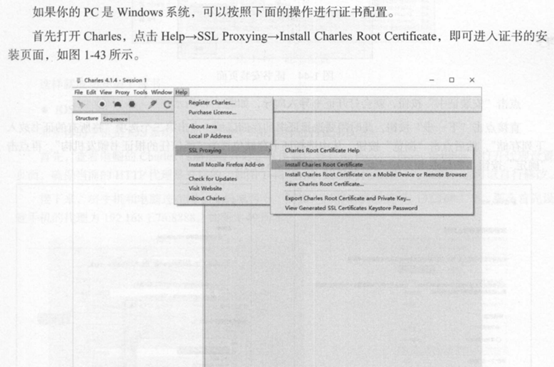
Charles教程; https://www.jianshu.com/p/fa351db39b5c
手机需要和电脑连接在同一个局域网下,并且配置手机为Charles代理

6.2 appium 自动化测试工具安装
使用appium软件可以通过python代码实现对你手机的自动化的点击,滑动等动作的操作,模拟人的对手机的操作。
Appium 官网下载:
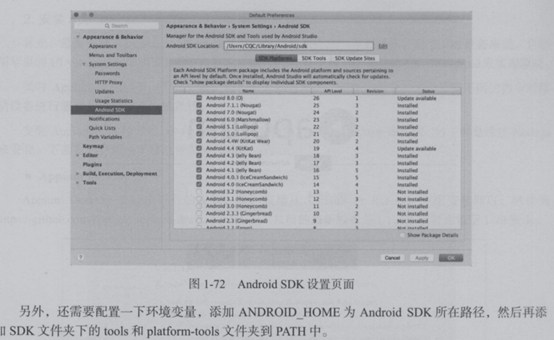
使用app抓取数据需要安卓环境的支持,配置android sdk环境
安装andriod studio 在Androidstudio中安装sdk
Sdk环境配置:
7 爬虫框架安装
在爬取工作量不大的时候可以使用request以及selenium库爬取就可以满足需求。
而大型的大量数据的爬取需要简化流程的爬虫框架的支持,只需要关心爬虫的逻辑不用关心爬虫的具体的模块功能的实现。简化代码。
主要的流行爬虫框架包括:
1 Pyspider 具有UI,脚本编辑器,任务控制器,项目管理器,结果处理器。支持多种数据库,多种消息队列,支持JS渲染页面爬取使用简单方便
2 scrapy 依赖库较多, 功能强大,安装麻烦,需要提前安装支持库
7.1 pyspider 框架安装
安装 pip install pyspider
或者 anacond安装, conda install pyspider
验证安装: cmd pyspider all
输出如下;
7.2 scrapy 框架安装
Scrip 是个强大的框架,但是依赖的python库比较多,因此安装之前需要提前安装很多的支持库。因此建议使用anaconda安装的方式。Anaconda会自动安装scrapy所需要的支持库。
Anaconda安装 conda install scrapy
7.3 scrapy-splash Javascript支持渲染工具安装
Scrapy-splash 是 javascript的渲染工具
Scrapy-splash的安装分为连个部分:splash服务,以及scrapy-splash的python库安装。
Splash服务通过docker安装,安装完成后会启动splash服务,通过它的接口,实现javascript页面加载。
Scrapy-splash python库安装通过pip安装,安装完成后在scrapy中使用splash服务。
8 Docker安装
Docker的容器技术用来部署爬虫,通过ddocker将爬虫的环境和应用打包,然后再在主机上使用docker部署即可运行新的爬虫
在docker官网下载,docker desktop 安装直接一路next。然后配置docker镜像源,由于访问国外的镜像速度很慢,因此需要配置国内的镜像来加速下载。
使用docker来打包和部署爬虫很方便。