爬虫基础 2.1 http基础原理
写爬虫为啥要了解http的原理?
为了简要的理解http的请求响应过程,便于爬虫的流程的掌握。
2.11 URL和URL
URI:统一资源标志符号
URN: 统一资源名称 命名资源
URL:统一资源定位符号 指定资源访问位置 例如网页链接
资源:指的是网络上所有可以获得的内容的统称
2.12 超文本
网页的源代码HTML文件可以看作超文本,
超文本"页面内可以包含图片、链接,甚至音乐、程序等非文字元素
超文本是收集,存储和浏览离散信息以及建立和表现信息之间关联的一门网络技术
2.13 HTML 超文本标记语言
为什么要了解HTML?
HTML = 网页 爬虫爬取的大部分信息都是来自网页中的内容,因此对HTML要有掌握。
HTML 指的是超文本标记语言 (Hyper Text Markup Language)
HTML 是用来描述网页的一种语言。
HTML 不是一种编程语言,而是一种标记语言 (markup language)
标记语言是一套标记标签 (markup tag)
HTML 使用标记标签来描述网页
它通过标记符号来标记要显示的网页中的各个部分。网页文件本身是一种文本文件,通过在文本文件中添加标记符,可以告诉浏览器如何显示其中的内容(如:文字如何处理,画面如何安排,图片如何显示等)。
浏览器按顺序阅读网页文件,然后根据标记符解释和显示其标记的内容,对书写出错的标记将不指出其错误,且不停止其解释执行过程。
在这里,需要掌握HTML的结构以及各种标签的特点:
该章节内容在网页基础中包含
2.14 HTTP和HTTPS
HTTP超文本传输协议,网络上服务器通过该协议传输网页,但是网页内容为加密,不安全
HTTPS HTTP的加强版,加密了传输过程,无法看到网页传输的明文
2.15 HTTP请求过程
用户想要知道网页上的内容,需要向服务器发起请求,而这些请求是包含很多参数和设置以及规定的语法的(超文本传输协议),手工实现请求很麻烦,于是就出现了浏览器。
浏览器处于远程服务器和我们之间,帮助我们向服务器发起请求,解析服务器返回的数据。
浏览器发起请求以及接受响应的过程:
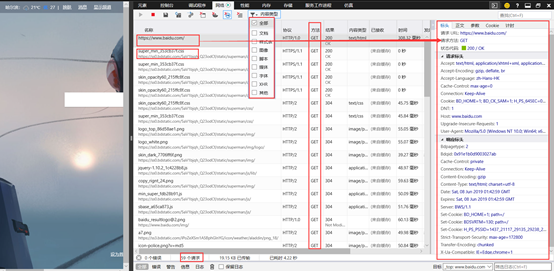
每一条包括一次请求和响应的过程,请求依次进行并解析响应内容,放入缓存。
每次发起的请求都包括标头,正文,参数,cokie,等内容。但并不是这些内容(请求和响应)每次都包含。
配置爬虫请求的时候多会关注标头,即请求头以及响应头。
请求过程:




请求方法:
浏览器或者客户端构造的请求内容包括请求头和请求体
请求头:包含请求的重要参数,爬虫的需要构造
请求体:一般是post的表单数据,使用get方法的请求体为空。
常用方法:
Get:请求参数直接包含在URL中 请求页面,服务器并返回请求响应
Post:请求参数包含在post的表单中,多来提交表单或者上传文件
其他方法:
Head:类似get请求,返回响应中只有报头
Put: 从客户端双重数据取代指定的文档中的内容
Delete:请求服务器删除指定的页面、
Connect: 将服务器当作跳板,让服务器代替客户端访问其他网页
Options: 允许客户端查看服务器的性能
Trace 回显服务器收到的请求,用测试或者诊断链接状态
请求的网址:
即网站的链接URL
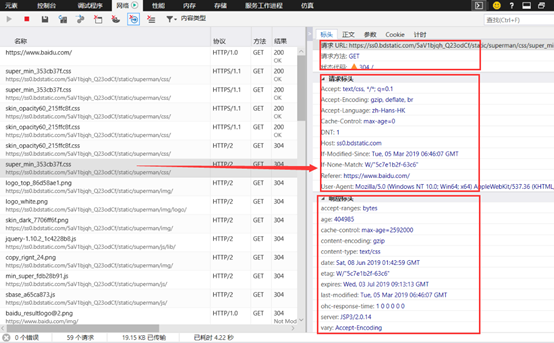
请求头:
请求头为浏览器向 服务器发起请求构造的参数内容,主要参数 信息包括:cookie,refer,user-agent等,写爬虫的时候是需要配置这些重要的请求参数的,通过对参数的配置,来保证爬虫的长期有效,不被服务器识别封掉,因为大量的频繁的请求会占用服务器资源。
常用的请求头包含的信息:
Accept :请求报头域,用于指定客户端可接受哪些类型的信息
Accept-Language :指定客户端可接受的语言类型
Accept-Encoding :指定客户端可接受的内容编码
Host :用于指定请求资源的主机 IP 和端口号,其内容为请求 URL 的原始服务器或网关的位
HTTP 1. 版本开始,请求必须包含此内容
Cookie :也常用复数形式 Cookies ,这是网站为了辨别用户进行会话跟踪而存储在用户本地的数据 它的主要功能是维持当前访问会话 例如,我们输入用户名和密码成功登录某个网站后,服务器会用会话保存登录状态信息,后面我们每次刷新或请求该站点的其他页面时,会发现都是登录状态,这就是 Cookies 的功 Cookies 里有信息标识了我们所对应的服务器的会话,每次浏览器在请求该站点的页面时,都会在请求头中加上 Cookies 并将其发送给服务器,服务器通过 Cookies 识别出是我们自己,并且查出当前状态是登录状态,所以返回结果就是登录之后才能看到的网页内容
Referer :此内容用来标识这个请求是从哪个页面发过来的,服务器可以拿到这 信息并做相应的处理,如做来源统计、防盗链处理等
User-Agent :简称 UA ,它是一个特殊的字符串头,可以使服务器识别客户使用的操作系统及版本 浏览器及版本等信息 在做爬虫时加上此信息,可以伪装为浏览器;如果不加,很可能会被识别州为爬虫
Content-Type :也叫互联网媒体类型( Internet Media Type )或者 MIME 类型,在 HTT 协议消息头中,它用来表示具体请求中的媒体类型信息 例如, text/html 代表 HTML 格式,
image/gif 代表 GIF 图片,
示例:

请求体:
请求体 般承载的内容是 POST 请求中的表单数据,而对于 GET 请求,请求体则为空,一般用于登录提交表单
登录网站之前,我们填写了用户名和密码信息,提交时这些内容就会以表单数据的形式提交给服务器,此时需要注意 Request Headers 指定 Cont nt-Type application, x-www-form-urlencoded 只有设置Content-Type application/x-www-form-urlencoded ,才会以表单数据的形式提 另外,我们也可以Content-Type 设置为 pplication/ison 来提交 JSON 数据,或者设置为 mu lti part/form-data 上传文件
注意:

响应:
响应内容,即服务器接收到请求以后向浏览器客户端发送的响应内容,响应内容包括响应头和响应体和响应状态码。
响应码:
响应码,表示服务器的响应状态。

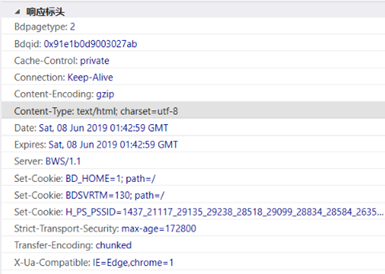
响应头:
包含了服务器的请求应答信息,我是谁,我是什么型号,我返回的信息的编码方式,我们之间保持连接方式,我返回信息的格式,我返回信息的时间,我对cookie的设置要求等,主要包括,connect-type,sever,set-cookie。。。
Date 标识响应产生的时间
Last-Modified 指定资源最后修改时间
Content-Encoding 指定内容的编码
Server 务器的信息 ,比如 、版本号等
Content-Type 文档类型 ,指定返回的数据类型是什么 ,
如 tex t/ htm 代表返回 HTML 文档,
application/x-javascript 返回 JavaScript 文件,
image jpeg 代表返回图片
Set Cookie 设置 Cookie 应头中的 Set Cook 告诉浏览器需要将此内容放在 Co kies次请求携带 Cookies 请求
Expires:响应过期时间 可以使代理务器或浏览器将加载的内容更新到缓存中,如果再次访时,就可直接从缓存中夹载,降低服务器负载缩短载时间
响应体:
爬虫中最重要的就是响应体的内容,大多数时候爬取的内容都是解析自响应体,响应的正文数据都来自响应体
请求网页:响应体是HTNL
请求图片:响应体是图片的二进制数据流
请求音乐视频:响应体是音乐视频的二进制流
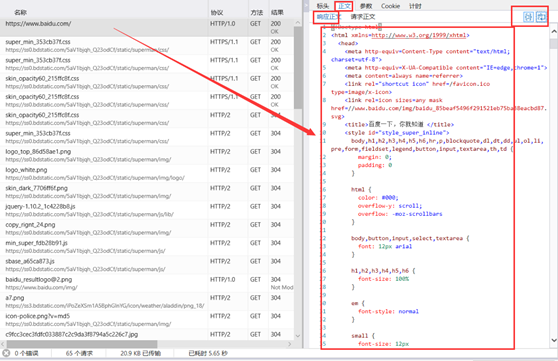
响应头示例:
响应体内容示例: