一、链表
1.链表有关的知识
(1)链表问题算法难度不高,主要考察代码实现能力
(2)链表和数组都是一种线性结构
数组是一段连续分配的存储空间,
链表空间不一定保证连续,是临时分配的。
(3)链表的分类
按链接方向分类:单链表、双链表
按有环无环分类:普通链表、循环链表
循环链表是首尾相接的链表,它的最后一个元素的next指针指向它的第一个元素,
另外还有一种循环双链表,它的头节点还有一个指针指向它的最后一个元素。
(4)链表问题代码实现的关键
a.链表函数的返回值类型,要求往往是节点类型
b.处理链表过程中,先采用画图的方式理清逻辑,对解答很有帮助
c.链表问题对于边界条件讨论要求严格
(5)链表插入和删除的注意事项
a.特殊处理链表为空,或者链表长度为1的情况
b.注意插入操作的调整过程
头尾节点和空节点的注意。
(6)单链表的翻转操作
a.当链表为空,或者长度为1时,特殊处理。
b.对于一般情况的操作如下:
首先用一个变量记录now结点的指向的下一个结点,
然后将now节点的next指针指向当前链表的head结点,
将now节点设置为翻转部分的新的头结点,
最后根据之前的变量记录,重复进行这个操作。
(7)关于额外空间的注意事项
大量链表问题可以使用额外数据结构来简化调整过程,
但链表问题最优解往往不是使用额外数据结构的方法。
很多问题都有空间复杂度为O(1)的解法。
2.环形链表插值问题
给定一个整数num,如何在节点值有序的环形链表中插入一个节点为num的节点,并且保证这个环形单链表依然有序。
首先生成节点值为num的节点node,
(1)如果链表为空
将node的next指针指向自己,返回node即可。
(2)如果链表不为空
令变量previous等于头结点,变量ncurrent等于头结点的下一个节点,两个指针同步移动下去,如果遇到p.value<=num,c.value>=num,
就把node插入其中,将node的prev指针指向当前的p,next指针指向当前的c即可。
(3)如果p和c转一圈都没有发现应该插入的位置,其实此时node的值应该是比链表中所有的值都大,或者都小,应该插入头节点的前面。但是注意,因为需要保证有序,所以两种情况下,链表的头部是不一样的。
3.访问单个节点的链表删除题目
给定一个链表中的节点node,但不给定整个链表的头节点,如何在链表中删除node?要求时间复杂度为O(1),实现这个函数。
(1)如果是双链表比较简单,当前节点可以通过prev和next指针找到前后的节点,删除这个节点只需要将node的前后节点重新连接即可。
(2)单链表无法通过当前节点找到之前的节点,此时可以使用下面的思路。
比如原始链表为1——>2——>3——>null,要删除节点2,但不知道头结点,
只要把节点2的值换成节点3的值,再链表中删掉节点3即可。
这种删除方式并不是删除了该删除的节点,而是进行了值的拷贝。
但是需要注意特殊情况:
如果要删除最后一个节点,因为节点3后面为空,只能将它删除,但找不到节点来替换,于是节点2的next指针不能指向null,删除失败。并且如果将节点3的值置为null,同样也是不可以的,此时节点2的指针仍然不是指向null。
也就是说这道题目经常出现,但是题目本身是不完备的。
二、字符串
1.字符串题目的特点
(1)广泛性
字符串可以看做字符类型的数组,
很多题目与数组的排序、查找、调整都是有关的,解答时可以参考
另外很多其他类型的题目可以看做字符串类型的面试题
注意Java中String是不可变的,可以使用String Buffer,String Builder,以及toCharArray方法。
(2)需掌握的概念
回文
子串(连续)
子序列(不连续)
前缀树(Trie树)
后缀树和后缀数组
匹配
字典序
(3)需掌握的操作
与数组有关的操作:增删改查
字符的替换
字符串的旋转等
2.字符串题目的常见类型
(1)规则判断类型
判断字符串是否符合整数规则
判断字符串是否符合浮点数规则
判断字符串是否符合回文规则等
等等
(2)数字运算
int和long类型表达整数范围有限,
经常用字符串实现大整数运算
使用字符串模拟大整数相关的加减乘除操作
(3)与数组操作有关的类型
数组有关的调整、排序等操作需要掌握
特别是快排的划分过程经常被考察,需要掌握和了解其改写
(4)字符计数
比如需要遍历一遍字符串,统计每种字符出现的次数。
可以使用哈希表处理;
也可以使用固定长度的数组解决;
在C/C++中字符的取值范围是0~255,在Java中是0~65535,
都可以使用固定长度的数组来代替哈希表进行字符统计,
常见的题目:
滑动窗口问题
寻找最长无重复子串问题
计算变位词问题
(5)动态规划类型
最长公共子串问题
最长公共子序列问题
最长回文子串问题
最长公共回文子串问题等
(6)搜索类型
比如给定两个字符串,String1每次只能变换一个位置的字符,如何通过一系列的变换,得到String2,打印变换轨迹。
这个实际上是搜索问题,
通常的解法有宽度优先搜索,和深度优先搜索。
(7)需要使用高级算法与数据结构解决的问题,很少出现
Manacher算法解决最长回文子串问题
KMP算法解决字符串匹配问题
前缀树结构
后缀树和后缀树组等
这些题目因为算法较为复杂,很少在面试中出现
3.拓扑结构相同的子树练习题
给定彼此独立的两棵树,头结点分别为t1和t2,判断t1中是否有与t2树拓扑结构完全相同的子树。
普通解法为二叉树遍历+匹配问题,最坏情况下时间复杂度为O(m*n)。
最优解法为二叉树序列化+KMP算法,
KMP算法的时间复杂度为O(m+n),因此这道题目可以做到O(m+n)。
4.变形词问题
给定连个字符串str1和str2,如果str1和str2中字符的种类都一样,并且每种字符出现的次数都一样,称为互为变形词。实现函数判断两个字符串是否为变形词。
使用哈希表算法解决。两个哈希表分别做字符计数,然后对比哈希表1和哈希表的记录是否一致。
同时可以用固定长度的数组代替哈希表结构,这道题的时间复杂度为O(N),额外空间复杂度也是O(N)。
5.旋转词问题
一个字符串str,把前面任意长度的部分字符串挪到后面而形成的字符串叫做str的旋转词,给定两个字符串,判定是否互为旋转词。
最优解的时间复杂度为O(N),即KMP算法。
策略如下:
首先判断str1和str2的长度是否相等,不相等直接返回false;
如果长度相等,生成str1+str1的大字符串;
用KMP算法判断大字符串中是否包含str2即可。
这里的大字符串,实际上穷举了所有的str1的旋转词。
6.给定一个字符串,请在单词间做逆序调整。
实现一个逆序函数。
7.字符串反转和手摇操作
给定一个字符串str,及一个整数i,i代表str中的位置,将str[0,i]移到右侧,str[i+1,n-1]移到左侧。
这里面包含了一个字符串问题中常用的方法,即通过几次字符数组的部分逆序调整,实现我们的调整需求。
8.字符串拼接字典序问题
给定一个字符串类型的数组strs,请找到一种拼接顺序,
使得所有字符串拼接起来的大字符串是所有拼接可能性的拼接方式中,字典序最小的,返回这个字符串。
9.空格替换问题
给定一个字符串str,将其中所有的空格换成“%20”,假设字符串后面有足够的空间。
先遍历一遍字符串,找到所有的空格数量,得到替换之后的字符串长度。
10.合法括号序列匹配问题
给定一个字符串str,判定是不是整体有效的括号字符串。
11.最长无重复子串问题
给定一个字符串str,返回str的最长无重复字符子串的长度。
三、二分搜索
1.二分搜索常见的应用场景
(1)在有序序列中查找一个数,经典的应用场景
给定有序数组array,判断m是否在数组中,时间复杂度为O(logN)。
(2)并不一定非要在有序序列中才能得到应用
只要在二分之后可以淘汰掉一半数据,都可以应用二分搜索。
2.二分搜索常见的考察点
二分思想并不困难,难点在于如何快速的写出代码,
特别是边界条件,仔细设计对中间划分点的逻辑判断,以及设计循环的终止条件,
防止出现死循环的情况。
3.二分搜索常见题目的变化
(1)给定处理或查找的对象不同
给定有重复值和无重复值的数组,二分的细节是不一样的
(2)判断条件不同
在有序数组中查找等于x出现的位置,同样也可以查找大于等于x出现的位置
(3)要求返回的内容不同
返回任意一个等于x的值的位置,也可以返回最左或者最右出现的位置,或者要求返回等于x元素的个数等
上面这些结合起来会题目会出现很多变化,要注意二分查找的应用。
4.在有序循环数组中进行二分搜索
比如 1,2,3,4,5,循环后可以是
2,3,4,5,1或者是3,4,5,1,2,等
5.二分搜索的重要提醒
mid=(left+right)/2
——>可能溢出
更安全的写法:
mid=left+(right-left)/2
6.局部最小位置问题
局部最小值是指,元素值同时小于左右两侧(array[0]或者array[n-1]是一侧)。
给定一个无序数组array,已知任意相邻的两个元素,值都不重复。
请返回任意一个局部最小的位置。
(1)arr为空或者长度为0,返回-1,表示局部最小不存在。
(2)如果arr长度为1,返回0,此时arr[0]是局部最小位置。
(3)如果arr长度>1,首先考察两头的位置,如果不符合要求,
说明arr[1]>arr[0],arr[n-1]>arr[n-2],
继续往下操作,arr[0],arr[1],...arr[mid]...,arr[n-2],arr[n-1],
继续判断mid位置是否是局部最小,如果arr[mid]符合直接返回mid,
如果不符合,考察arr[mid-1]<arr[mid]<arr[mid+1],
那么可知在mid右侧部分的趋势是凹的,那么这部分更可能出现局部最小值,于是舍弃左侧部分,继续对右侧部分进行二分查找。
通过这道题目,应该理解二分查找并不仅限于有序数组,只要在查找中发现可以留下一半,淘汰另一半,就可以应用二分搜索。
7.给定一个有序数组arr,再给定一个整数num,请在arr中找到num这个数出现的最左边的位置。
这里注意有序,并不是无重复。可以应用二分搜索。
8.循环有序数组最小值问题
9.最左原位问题
给定一个有序数组arr,其中不含有重复元素,请找到满足arr[i]==i条件的最左的位置。
如果所有位置上的数都不满足条件,返回-1。
生成全局变量,result,记录最后一次发生arr[i]==i的位置,
初始为result=-1。
10.完全二叉树计数题
给定一棵完全二叉树的头结点head,返回这棵树的节点个数,如果完全二叉树的节点个数为N,
请实现时间复杂度低于O(N)的解法。
四、队列和栈
1.队列和栈的基本性质
(1)栈是先进后出的,队列是先进先出的
(2)栈和队列在实现结构上可以有数组和链表两种形式
数组结构实现比较容易;
链接结构比较复杂,因为牵扯很多指针操作;
(3)栈结构的操作
pop操作,从栈顶弹出一个元素;
也可以只访问栈顶元素而不弹出,也就是top或者peek操作;
push操作,从栈顶压入一个元素;
size操作,返回栈中的元素个数;
(4)队列的操作
与栈操作不同,push操作时在队头加入元素,
pop操作,是从队列尾部弹出一个元素。
队列和栈的基本操作,都是时间复杂度为O(1)。
栈可以理解为一条射线,底部是固定的,元素的进出栈只能从栈顶进行;
队列可以理解为一条直线,操作从两端进行,但是一端负责进队,一端负责出队;
还有一种结构是双端队列,两端都可以进出元素,比如Java中的Deque;
另外还有优先级队列,根据元素的优先级值,决定元素的弹出顺序,
优先级队列是堆结构,不是线性结构。
(5)深度优先遍历(DFS)和宽度优先遍历(BFS)
深度优先遍历可以用栈实现;
宽度优先遍历可以用队列实现,也就是经常说的树的层次遍历;
(6)平时使用的递归函数实际上用到了系统提供的函数栈,递归的过程可以看做递归函数
依次进入函数栈的处理过程,所有用递归函数可以做的过程都一定可以用非递归的方式实现。
2.实现支持getMin操作的栈结构
要求pop、push、getMin操作的时间复杂度都是O(1),
设计的栈类型可以使用现成的栈结构。
使用两个栈结构,一个stackData栈用来保存栈中元素,用法和普通栈一样,
另一个stackMin栈用来保存每一步操作的最小值,根据入栈方式的不同,有两种设计方案:
(1)弹出时需要判断
push操作元素依次保存到stackData栈,只有当前数小于等于(注意等于也要入栈)stackMin的栈顶时,才压入StackMin。

pop弹出时,StackData首先弹出,假设弹出value,去比较value和StackMin的栈顶元素,如果value大于StackMin栈顶,不作操作,
如果等于StackMin栈顶,StackMin弹出当前栈顶(肯定不会小于)。这样操作,StackMin栈顶始终记录StackData的最小值。
(2)弹出时同步弹出
push操作元素依次保存到stackData栈,当前数小于stackMin的栈顶时,将当前数压入StackMin,否则大于等于栈顶时,重复压入当前stackMin的栈顶。

(3)相比较,方案一压入时稍省空间,略费时间(需要比较);方案二稍费空间,略省时间。
3.使用两个栈实现队列
编写一个类,只能用两个栈结构实现队列,支持队列的基本操作(add/poll/peek)操作。
(1)使用两个栈结构,一个StackPush用来做压入栈,一个StackPop用作弹出栈。
初始化压入完成时,只要将StackPush的全部数据依次倒入到StackPop,数据的顺序就完全颠倒了,接下来弹出时就符合队列的性质了。

(2)需要注意的,考虑几个实例即可
StackPush向StackPop中倒数据时必须一次倒完;
如果StackPop中有数据,必须等待StackPop完全弹出清空后再倒入数据;
4.栈的就地逆序问题
实现一个栈的逆序,但是只能用递归函数和这个栈本身的操作来实现,不能使用额外的数据结构。
5.栈的排序问题
一个栈中元素类型为整型,现在对该栈从栈顶到栈底从大到小排序,可以申请一个栈,不能申请额外的数据结构。
6.双端队列解决滑动窗口问题
(1)普通解法
(2)时间复杂度O(N)的解法
五、大数据和位运算
1.哈希函数
(1)哈希函数即散列函数
哈希函数的输入域可以是非常大的范围,
但是输出域是固定范围。
(2)哈希函数的性质:
a.典型的哈希函数都有无线的输入值域
b.输入值相同时,返回值相同,返回值即哈希值
c.输入值不同时,返回值可能一样,也可能不一样
d.不同输入值得到的哈希值,整体均匀的分布在输出域s上。(重要)
前三点性质是哈希函数的基础,最后一点是评价一个哈希函数优劣的关键。
(3)无论哈希函数设计有多么精细,都会产生冲突现象,也就是2个关键字处理函数的结果映射在了同一位置上,因此,有一些方法可以避免冲突。
一个优秀的哈希函数可以使不同输入值得到的哈希值均匀分布,哈希值越均匀的分布在s上,该哈希函数越优秀。
这种均匀分布与输入值无关,比如"aaa1","aaa2","aaa3",虽然相似,但一个优秀的哈希函数计算出的哈希值应该差异巨大。
这样s(输出域)对%m后的结果,也会均匀的分布在0~m-1这个值域上。这一点在哈希函数的应用中是非常重要的。
2.介绍Map-Reduce
把大任务分成两个阶段的过程。
(1)Map阶段
通过哈希函数把任务分成若干的子任务,哈希函数会是系统自带的,或者用户指定的。
相同哈希值的任务会被分配到一个节点上进行处理。在分布式系统中,一个节点可以是一个计算节点,也可以是一台计算机。
(2)Reduce阶段
分开处理,然后合并结果的阶段。
(3)Map-Reduce的原理简单,但工程上的实现会遇到很多问题
a.备份的考虑,分布式存储的设计细节,以及容灾策略
b.任务分配策略与任务进度跟踪的细节设计,以及节点状态的呈现
c.分布式系统多用户权限的控制
3.用Map-Reduce方法统计一篇文章中每个单词出现的个数
(1)首先把文章进行预处理,最终目标是得到一个连续的单词字符串输入
比如去掉文章中的标点符号;对连字符"-"的处理,如pencil-box,和换行处的连字符;对于缩写的处理,如I’m、don’t等等;大小写的转换等
(2)现在输入是只包含单词的文本,进入map阶段
对每个单词都生成词频为1的记录。比如(dog,1)、(pig,1)等。
此时一个单词可能有多个词频为1的记录,比如说可能有多个(dog,1)的记录。
(3)然后通过哈希函数,得到每个单词的哈希值,并根据该值分成若干组任务
根据哈希函数的性质我们知道,单词相同的记录会被分配到一起。
(4)进入Reduce阶段。
在子任务中,同一种单词的词频进行合并,最后得到所有记录并统一合并。因为每个子任务都是并行处理的,所以效率会比较高。
4.常见海量数据处理题目解题关键
(1)分而治之。通过哈希函数将大任务分流到机器,
或分流成小文件,在每一个小部分上进行处理,然后再把结果合并起来
(2)常用hashmap、bitmap等数据结构
(3)难点其实是通讯、时间和空间的估算
5.bitmap解决大数据量文件排序
请对10亿个IPV4的ip地址进行排序,每个ip只会出现一次。每个ip只会出现一次。
IPv4中规定IP地址长度为32(按TCP/IP参考模型划分) ,即有2^32-1个地址。
IPv6协议的地址长度是128位,全部可分配地址数为2的128次方(2^128)个
(1)普通方法
IPV4的ip数量大概42亿,诸如172.18.24.40,每个ip地址可以转换为对应的无符号整数,
可以直接把这10亿个ip地址全部转换成数字,然后把这10亿个数字排序后再转换会ip地址即可。
1个ip地址占据32bit,也就是4Byte,也就是说存储着10亿个整数需要40亿字节空间,大概是
4(Gb),000(Mb),000(Kb),000(Byte),也就是需要4Gb内存,
在目前的机器上这个方法是可以执行的,但是通过bitmap可以有更优化的方法。
(2)bitmap方法
申请一个长度为2^32的bit类型的数组,每个位置上是一个bit,只可表示0或者1两种状态,空间大概为2^29字节,大约512Mb。
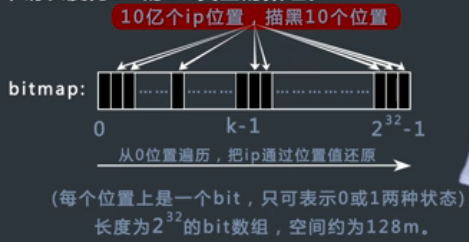
如果整数1出现,就把bitmap对应的位置从0变到1,这个数组可以表示任意一个(注意是一个)32位无符号整数是否出现过,
然后把10亿个ip地址全部转换成整数,相应的在bitmap中相应的位置描黑即可,
最后只要从bitmap的零位一直遍历到最后,然后提取出对应不为0位的整数,再转换成ip地址,就完成了从大到小的排序。
6.桶排序处理大数据
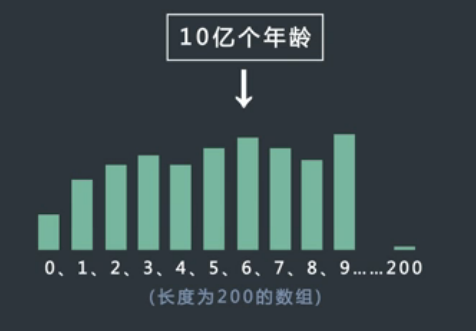
请对10亿的年龄进行排序。
年龄在0~200之间,然后用一个足够大的数组,对10亿个数据进行计数排序就可以了。
7.哈希函数分流加哈希表解决Top K问题
有一个包含20亿个全是32位整数的大文件,在其中找到出现次数最多的数。内存限制为2G。
(1)通常的方法
使用哈希表做词频统计,key记录具体某一个整数,value记录这个整数出现的次数,最后统计即可。
首先看一下哈希表结构如何设计,key就是32位整数,4字节
4字节,32位<——整型<——key——>具体某一个整数
假设极端情况一个整数出现了20亿次,那么value可能的最大值是20亿,
即2^31,也需要用4字节保存
4字节,31位<<——value——>这个整数出现的次数
所以哈希表每条记录占据8字节,20亿数据需要占据16G空间,一次性可能会超出内存限制,现在对这个方法进行改进。
(2)分而治之的方法
把包含20亿个数的大文件中的每一个数使用哈希函数分流,把大文件分成若干个小文件,假设有16个小文件。
同一种数不会被分流到不同文件,这是哈希函数的性质决定的,对不不同的数,每个文件中含有整数的种数几乎一样,这也是哈希函数的性质决定的。
然后用哈希表统计每个小文件中每种数出现的次数,此时肯定不会出现溢出,现在就得到了每个小文件中出现次数最多的数,然后把这每个小文件的出现最多的数进行比较,就可以得到结果。
大数据题目的一个特点是,通过哈希函数不断分流,来解决内存限制的问题。
8.分治+桶思想+bitmap解决大数据中元素是否出现问题
32 位无符号整数的范围是0~4294967295 。现在有一个正好包含40亿个无符号整数的文件,所以在整个范围中必然有没有出现过的数,可以使用最多10M的内存,只用找到一个没出现过的数即可,该如何找?
(1)使用哈希表
key——>具体某一个整数(32bit),value——>这个整数是否出现(1bit),
每条记录至少需要4字节,假设40亿条数据全部不相同,40亿条记录占据160亿字节,即需要16G内存,肯定不可以。
(2)使用bitmap
申请一个长度为2^32的bit类型的数组,这个数组需要2^29Byte,即512Mb空间,依然不符合要求
(3)桶排序思想,数字范围分成若干个桶
0~2^32-1范围分成64个区间,每个区间应该装下2^32/64的数,总共的范围为42亿,一共有40亿个数字,肯定有区间计数不足2^32/64,只要找到一个区间,在这个区间肯定有没出现过的数。假设这个区间为A,接下来在再对这个区间的范围构造bitmap,需要占用空间为512/64Mb,然后再遍历这40亿个数字,最后考察bitmap上哪个没出现即可。
首先根据内存限制,确定分成多少个空间,然后利用区间计数的方式,找到哪个区间计数不足,
对这个区间上的数利用bitmap即可。
9.哈希分流+哈希表词频统计+小根堆和外排序解决Top K问题
某搜索公司一天的用户搜索词汇是海量的,假设有百亿的数据量,请设计一种求出每天最热100词的可行办法。
10.一致性哈希,解决节点数量改变导致哈希函数分流手段失效的问题
11.算术运算的操作符
+ - * / %(模)
位运算的操作符
& 按位与
| 按位或
^ 按位异或
~ 取反
<< 左移右侧补0
>> 右移左侧补符号位
>>> 右移左侧补0
12.布隆过滤器
100亿个不安全的网页黑名单,每个网页的URL最多占用64字节,
现在想要实现一种网页过滤系统,可以根据网页的URL判断该网页是否在黑名单上,
要求该系统允许有万分之一以下的判断失误率,并且使用的额外空间不要超过30G。
如果把黑名单——>哈希表或者数据库
(1)如果遇到网页黑名单系统,垃圾邮件过滤系统,爬虫的网址判断重复系统,
又看到系统容忍一定的失误率,但是对空间有严格要求,
很可能是需要使用布隆过滤器的知识求解。
(2)布隆过滤器可以精确的代表一个集合,
可以精确判断某一元素是否在此集合中,精确程度由用户的具体设计决定,做到100%的精确即正确是不可能的。
13.考虑如何不用额外变量,交换两个整数的值?
使用位运算。
补充:2的幂表
| 2的幂 | 准确值 | 近似值 | 对应的字节(Byte)转换成MB/GB等 | 常见的场景 |
| 7 | 128 | |||
| 8 | 256 | |||
| 9 | 512 | |||
| 10 | 1024 | 一千 | 1K | |
| 16 | 6 5536 | 64K | ||
| 20 | 104 8576 | 一百万 | 1MB | |
| 30 | 10 7374 1824 | 1GB | ||
| 32 | 42 9496 7296 | 42亿多 | 4GB | IPV4地址长度 |
| 40 | 1 0995 1162 7776 | 一万亿 | 1TB |