降维
1.1 目标1:数据压缩 Data Compression
现在来介绍第二个无监督学习:降维,降维的第一个作用就是压缩数据,允许我们使用较少的内存或磁盘空间,也加快算法速度
当我们发现特征中有一些特征是冗余的(比如:特征1是厘米,特征2是英尺),那么我们就需要通过降维来压缩数据
将二维降到一维:

将三维降为二维:

1.2 目标2:可视化 Data visualization
降维的第二个作用就是可视化,可以将高维的数据进行可视化
比如以下这个例子,特征为各国的一些信息,假设有50个特征,那么我们就很难将50维的图像构建出来
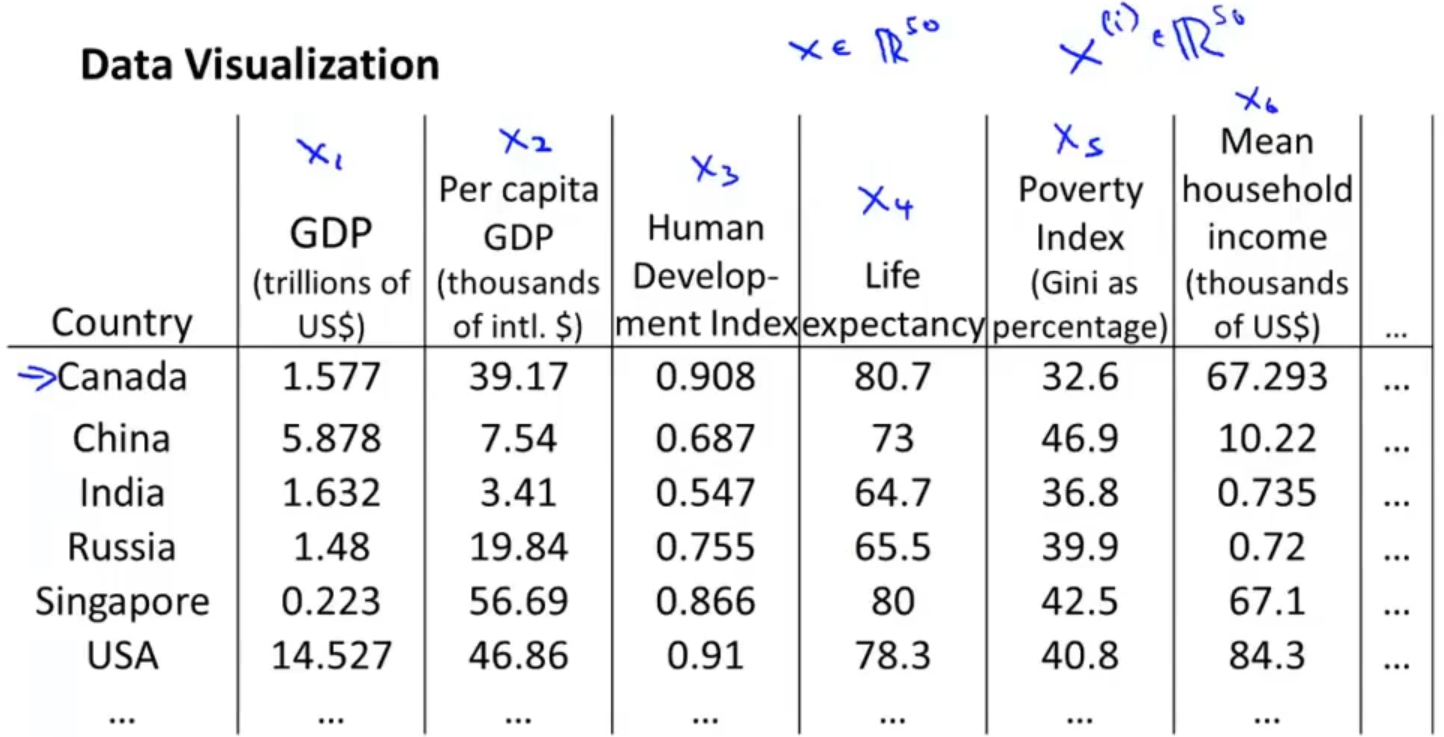
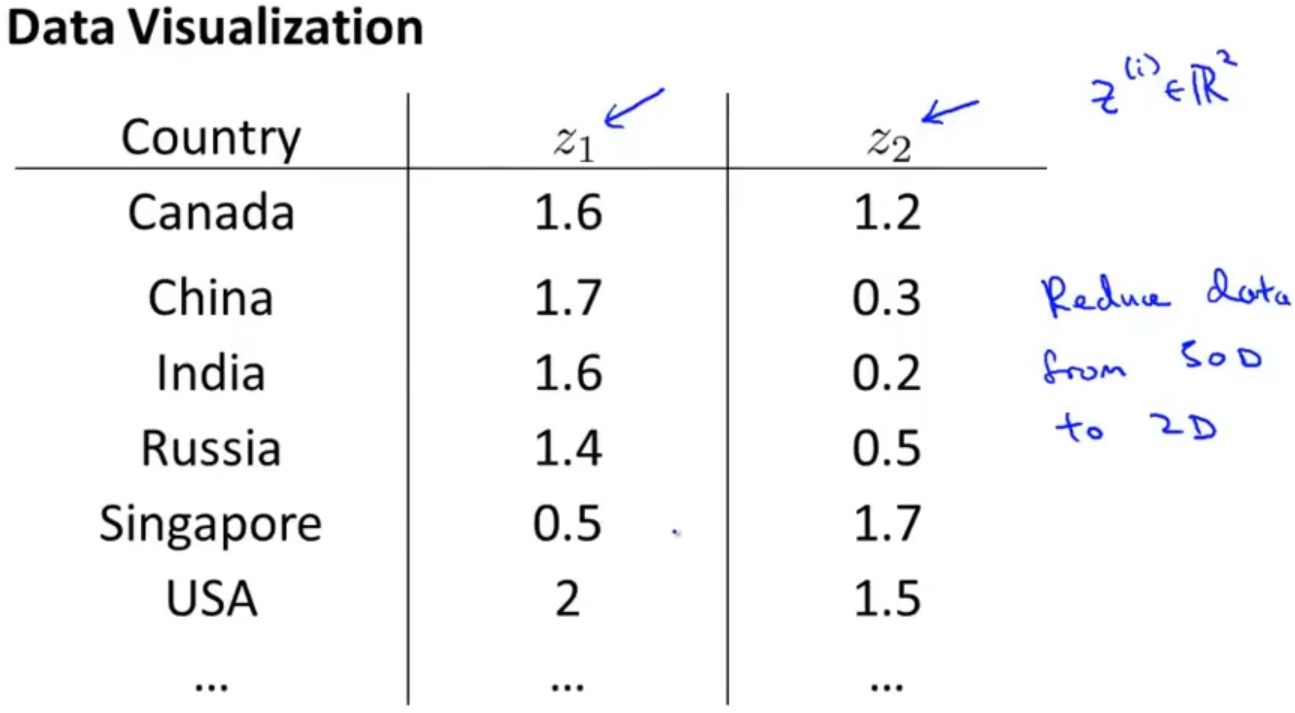
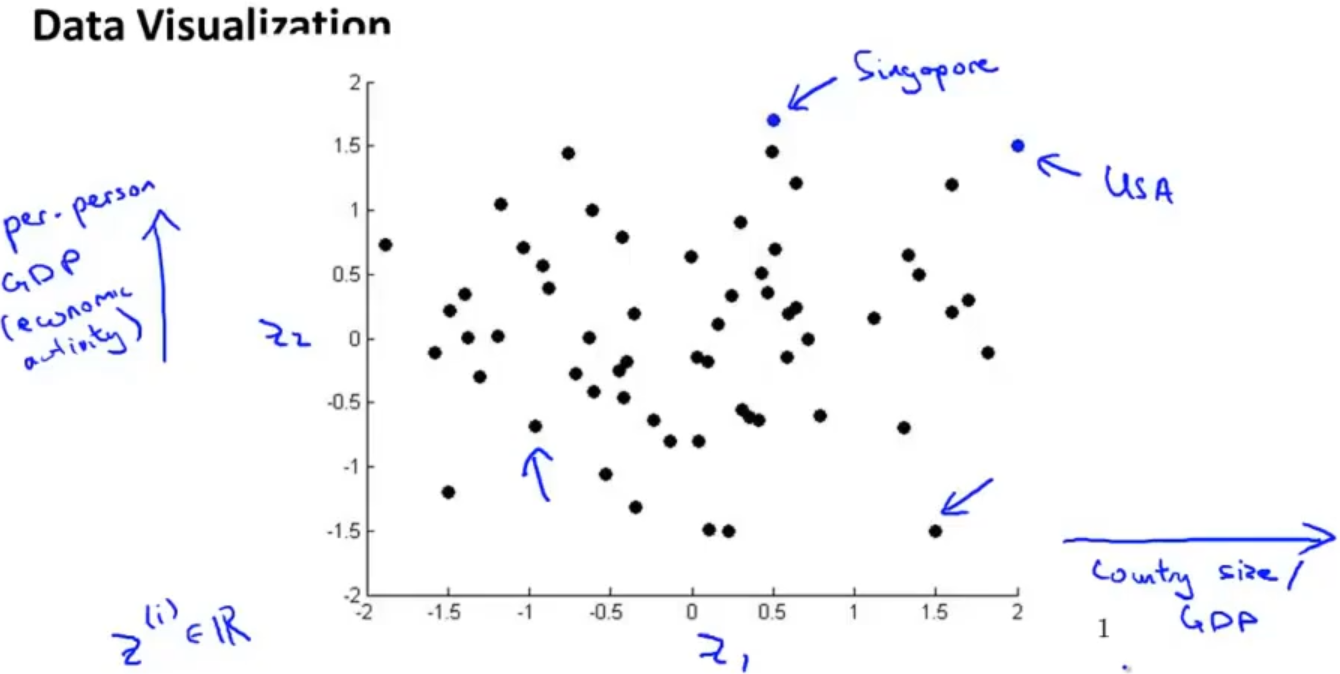
所以我们可以通过降维对数据进行可视化
1.3 主成分分析问题描述 Principal Component Analysis problem formulation
最常见的降维算法是主成分分析(PCA)。PCA 要做的是找到一个方向向量(Vector direction),把所有的数据都投射到该向量上并且投射平均均方误差要尽可能小。方向向量是一个经过原点的向量,投射误差是从特征向量向该方向向量所作垂线的长度
如下图,我们就认为红色直线就是PCA要找的向量,因为投射平均均方误差都比较小,而不是选择洋红色直线作为向量

更一般化的就是要将n维数据降至k维,目标是找到向量u(1) ,u(2) ,...,u(k) 使得总的投射误差最小,比如3维降到2维就是找到向量u(1) ,u(2),将所有数据投射到由向量u(1) ,u(2)构成的平面上去
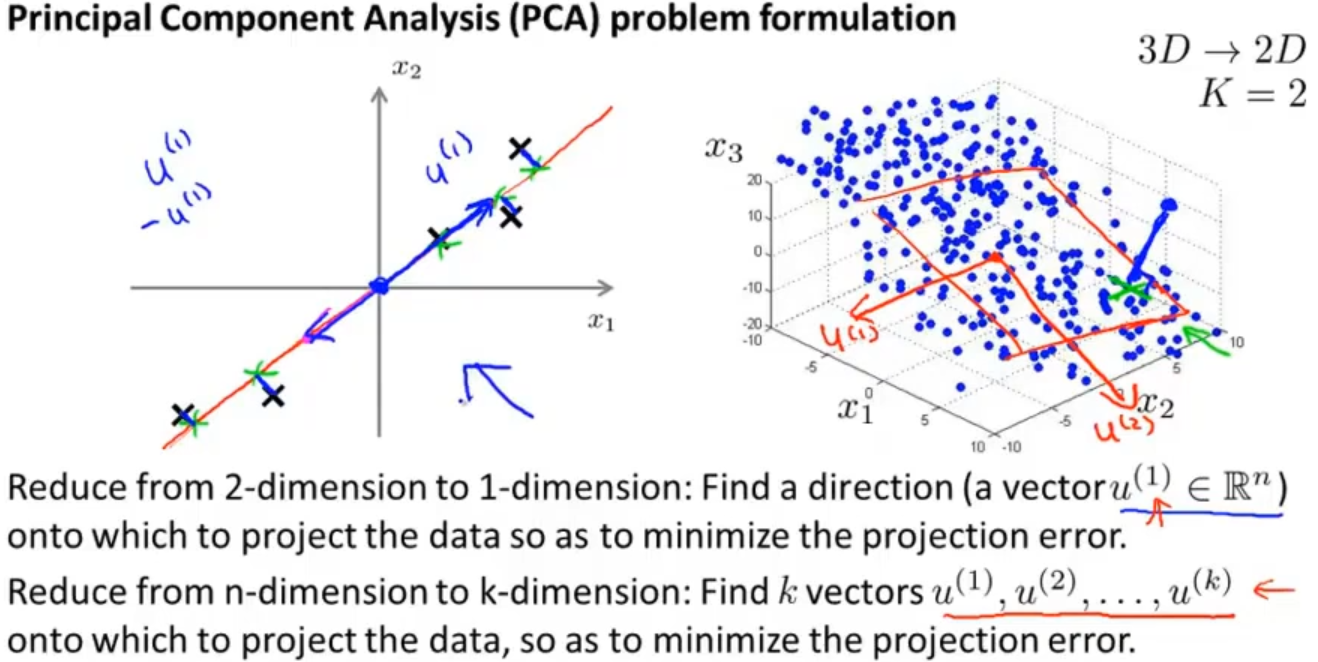
可能从下图来看,会觉得PCA和线性回归有点相似,其实并不是的
PCA最小化的是投射误差,不作任何预测。线性回归最小化的是预测误差,目的是预测结果
左图的是线性回归的误差(垂直于横轴投影),右图则是主要成分分析的误差(垂直于斜线投影)

现在就详细的介绍一下PCA的算法
第一步需要对特征做均值归一化,计算出所有特征的均值,然后令 xj = xj − μj 。如果特征是在不同的数量级上,还需要将其除以 最大值减去最小值 或者除以标准差 σ2

第二步需要计算协方差矩阵(covariance matrix) Σ,(读音:sigma),公式为:
第三步需要计算协方差矩阵 Σ 的特征向量(eigenvectors),在 Matlab 中调用 [U,S,V] = svd(sigma) 可以直接求得特征向量 U(对于一个 n × n 维度的矩阵,U 是一个由 “与数据之间最小投射误差的方向向量” 构成的矩阵)

如果希望将数据从 n 维降至 k 维,只需要从 U 中选取前 k 个向量,获得一个 n × k 维度的矩阵,用Ureduce 表示
降维后新特征向量 z(i)的计算公式为:

最后总结一下PCA的优点:
<1> 对数据进行降维处理,可以通过降维从而简化模型
<2> 它是完全无参数限制的,最后的结果只与数据相关
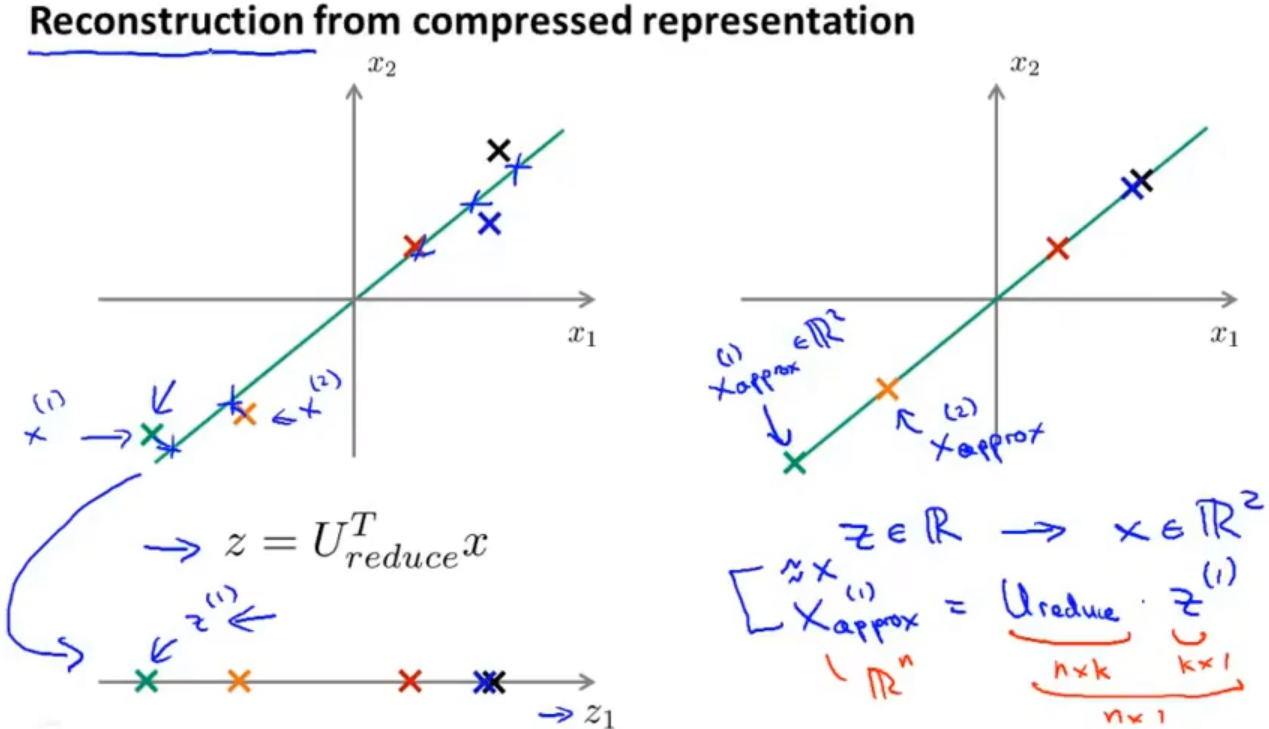
1.4 重建原始特征 Reconstruction from compressed representation
在之前介绍了将数据从高维降维到低维,其实在给定降维后的数据时,我们还可以重建降维前的数据
我们是通过 z = UreduceT * x 来获得降维后的数据,可想而知我们就可以通过 xappox = Ureduce ⋅ z 来重建降维前的数据,这时就有 xappox ≈ x
1.5 主成分数量选择 Choosing the number of principal components
主成分分析是最小化投射的平均均方误差,那怎么选择适当降维目标 k 值(即主成分的数量)呢?
我们的目标是:在『平均均方误差与训练集方差的比例尽可能小』的情况下,选择尽可能小的 k 值
如果平均均方误差与训练集方差的比例小于 1%,就意味着有 99% 的原本数据都保留下来了。同理,比例为 5%,对应95%的原数据,比例10%,对应90%的原数据
通常原数据比例在 95%到99% 是最常用的取值范围(对于许多数据集,通常可以在保留大比例原数据的同时大幅降低数据的维度。这是因为大部分原数据中的许多特征变量都是高度相关的)

算法的具体流程:
先令 k = 1,然后进行主成分分析,获得Ureduce 、z和xappox,最后通过左图公式计算比例是否小于 1% ,如果比例大于 1% 的话,再令k = 2,如此类推,直到找到可以使得比例小于 1%的最小k 值

除了以上这个方法,还有另一个方法:
通过在 Matlab 中调用 [U, S, V] = svd(sigma) 来获得对角矩阵S(对角矩阵S的大小与Σ一致),再利用下面的公式直接计算平均均方误差与训练集方差的比例
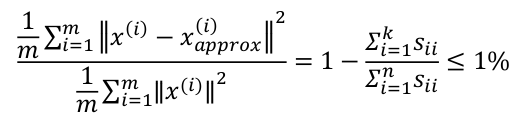

1.6 PCA的应用建议 Advice for applying PCA
对于PCA的应用,假设对训练集(x,y) (100×100 的图像,特征 x 的维度为100×100=10000)采用监督学习的方式去预测,在预测前对特征进行PCA处理,将数据压缩至 1000 个特征,x 转变为 z,重新组建成训练集(z,y),再进行预测

在PCA的应用上,建议运用在压缩和可视化上

不建议将其运用在防止过拟合上,虽然可能会有用,但是特征减少了就有可能失去一些有用的信息了。对于防止过拟合,可以采用加入的正则化的方式去解决

在一些项目上的运用,不建议一开始上来就使用PCA,最好还是从使用原始特征开始,在有必要的时候(比如:算法运行太慢或者占用太多内存)才考虑采用 PCA
