文章目录
04 Python科学计算:用NumPy快速处理数据
使用Numpy让你的Python科学计算更高效
-
避免采用隐式拷贝,而是采用就地操作的方式
可以提高计算速度 -
ndarray
NumPy数组中的维数称为秩(rank),一个线性的数组称为一个轴(axes),秩就是描述轴的数量。 -
创建数组
import numpy as np
a = np.arrary([1, 2, 3,])
b = np.array([1, 2, 3], [4, 5, 6], [7, 8, 9])
b[1, 1] = 10
print a.shape
print b.shape
print a.dtype
print b
运行结果
(3L,)
(3L, 3L)
int32
[[1 2 3]
[4 10 6]
[7 8 9]]
import numpy as np
persontype = np.dtpye({
'name':['name', 'age', 'chinese', 'math', 'english'],
'formats':['s32', 'i', 'i', 'i', 'f']} # 定义结构
peoples = np.array(["ZhangFei", 32, 75, 100, 90),("GuanYu", 24, 85 , 96, 88.5),
("ZhaoYun", 28, 85, 92, 96.5),("HuangZhong", 29, 65, 85, 100)],
dtype = persontype)
ages = peoples[:]['age']
chinese = peoples[:]['age']
maths = peoples[:]['chinese']
englishs = peoples[:]['english']
print np.mean(ages) # 求平均值
print np.mean(chinese)
print np.mean(maths)
print np.mean(englishs)
- ufunc运算
x1 = np.arange(1,11,2) # 创建等差数组:初始值,终值,步长
x2 = np.linspace(1,9,5) # 创建等差数组:初值、终值,元素个数
- 算法运算
x1 = np.arange(1,11,2)
x2 = np.linspace(1,9,5)
print np.add(x1, x2) # 加
print np.substact(x1, x2) # 减
print np.multiply(x1, x2) # 乘
print np.divide(x1, x2) # 除
print np.power(x1, x2) # 幂
print np.remainder(x1, x2) # 取余 np.remainder()与np.mod()一样
- 统计函数
'''
计算矩阵的最大最小值
'''
import numpy as np
a = np.array([[1,2,3], [4,5,6], [7,8,9]])
print np.amin(a)
print np.amin(a,0)
print np.amin(a,1)
print np.amax(a)
print np.amax(a,0)
print np.amax(a,1)
- 计算加权平均值
a = np.array([1,2,3,4])
wts = np.array([1,2,3,4])
print np.average(a)
print np.average(a, weights=wts) # 计算加权平均值
- 统计数组中的标准差std()、方差var()
a = np.array([1,2,3,4])
print np.std(a) # 计算标准差
print np.var(a) # 计算方差
- NumPy 排序
'''
默认为快速排序,可以指定kind为quicksort、
mergesort、heapsort,即快速排序、合并排序、堆排序。axis可以指定为-1,1,None.
'''
a = np.array([[4,3,2],[2,4,1]]
print np.sort(a)
print np.sort(a, axis=None)# 扁平化排序
print np.sort(a,axis=0)# 按列排序
prin np.sort(a, axis=1)# 按行排序
-
总结

-
联系
'''
将团队里的5名同学,按总成绩排序并得出名次进行参加输出
'''
import numpy as np
studentscoretype = np.dtype({'name':['姓名', '语文', '英语', '数学'],
'formats':['s32', 'f', 'f', 'f']})
studentscore = np.array([("张飞", 66, 65, 30), ("关羽", 95, 85, 98),
("赵云", 93, 92, 96), ("黄忠", 90, 88, 77),
("典韦", 80, 90, 90)], type = studentscoretype)
#print(peoples)
name = peoples[:]['name']
wuli = peoples[:]['chinese']
zhili = peoples[:]['english']
tili = peoples[:]['math']
def show(name, cj):
print(name),
print(' |'),
print(np.mean(cj)),
print(" | "),
print(np.min(cj)),
print(" | "),
print(np.var(cj)),
print(" | "),
print(np.std(cj))
print("科目 | 平均成绩 | 最小成绩 | 最大成绩 | 方差 | 标准差")
show("语文", wuli)
show("英语", zhili)
show("数学", tili)
print("排名")
peoples[:]['total'] = peoples[:]['chinese'] + peoples[:]['english'] + peoples[:]['math']
print(np.sort(peoples, order = 'total')
05| Python科学计算: Pandas
- 提高基础数据结构:DataFrame
- Pandas基于Numpy的更高级数据结构和分析能力工具包
- 核心数据结构:
series,DataFrame Series两个基本属性:index和values,默认为0, 1, 2,
import pandas as pd
from pandas import Series, DataFrame
x1 = Series([1, 2, 3, 4])
x2 = Series(data=[1,2,3,4], index=['a', 'b', 'c', 'd'])
print(x1)
print(x2)
- DataFrame 类型数据结构,类似数据库表
import pandas as pd
from pandas import Series, DataFrame
data = {'Chinese': [66, 95, 93, 90,80], 'English':[65, 85, 92, 88, 90], 'Math':[30, 98, 96, 77, 90]}
df1 = DataFrame(data)
df2 = DataFrame(data, index['Zhangfei', 'GuanYU', 'ZhaoYun', 'HuangZhong', 'DianWei'], colums = ['English', 'Math', 'Chinese'])
print(df1)
print(df2)
- 数据导入和导出
Pandas允许直接从xlsx,csv等文件中导入数据,也可以导出到xlsx, cvs等文件,非常方便。
import pandas as pd
from pandas import Series, DataFrame
core = DataFrame(pd.read_excel('data.xlsx'))
score.to_excel('data1.xlsx')
pirnt(score)
- 数据清洗
data = {'Chinese': [66, 95, 93, 90, 80], 'English': [65, 85, 92, 88, 90], 'Math':[30, 98, 96, 77, 90]}
df2 = DataFramez(data, index=['ZhangFei', 'GuanYu', 'ZhaoYun', 'HuangZhong', 'DianWei'], columns=['English', 'Math', 'Chinese'])
- 删除不必要的行或列
```py
df2 = df2.drop(columns=['Chinese'])
```
- 想把“张飞”这一行删掉
```py
df2 = df2.drop(index=['ZhangFei']
```
- 重命名
```df2.rename(columns={'Chinese': 'YuWen', 'English': 'Yingyu'},
inplace = True)
- 去掉重复的值
df = df.drop_duplications() # 去掉重复的值
-
更改数据的格式
df2['Chinese'].astype('str')
df2['Chinese'].astype(np.int64) -
数据间的空格
# 删除左右两边空格
df2['Chinese']=df2['Chinese'].map(str.strip)
# 删除左边空格
df2['Chinese']=df2['Chinese'].map(str.lstrip)
# 删除右边空格
df2['Chinese']=df2['Chinese'].map(str.rstrip)
- 删除某个特殊符号
df2['Chinese']=df2['Chinese'].str.strip('$')
- 大小写转换
# 全部大写
df2.columns = df2.columns.str.upper()
# 全部小写
df2.columms = df2.columns.str.lower()
# 首字母大写
df2.columns = df2.columns.str.title()
- 查找空置
df.isnull()
df.isnull().any()
- 使用apply函数对数据进行清洗
df['name'] = df['name'].apply(str.uppper)
def double_df(x):
return 2*x
df1[u'语文'] = df1 [u'语文'].apply(double_df)
- 数据统计

df1 = DataFrame({'name':['ZhangFei', 'GuanYu', 'a', 'b', 'c'], 'data1':range(5)})
print(df.describe())
- 数据表合并
# 创建两个数据表
df1 = DataFrame({'name':['ZhangFei', 'GuanYu', 'a', 'b', 'c'], 'data1':range(5)})
df2 = DaraFrame({'name':['ZhangFei', 'GuanYu', 'A', 'B', 'C'], 'data2':range(5)})
# 基于指定列进行连接
df3 = pd.merge(df1, df2, on='name')
# inner
# 内连接是merge合并的默认情况,inner内链接其实也就是键的交集,在这里df1,df2相同的键是name,所以是基于name字段做的连接:
df3 =pd.merge(df1, df2, how='inner')
# left左连接
# 左连接是以第一个DataFrame为主进行连接,第二个DataFrame作为补充
df3 = pd.merge(df, df2, how='left')
# right右连接
# 右连接是以第二个DataFrame为主进行的连接,第一个DataFrame作为补充
df3 = pd.merge(df1, df2, how='right')
# outer外连接
# 相当与两个DataFrame的并集
df3 = pd.merge(df1, df2, how='outer'
- 如何用SQL方式打开Pandas
使用工具pandasql
import pandas as pd
from pandas import DataFrame
from pandasql import sqldf, load_meat, load_births
df1 = DataFrame({'name':['ZhangFei', 'GuanYu', 'a', 'b', 'c'], 'data':range(5)})
pysqldf = lambda sql:sqldf(sql, globals())
sql = "select * from df1 where name = 'ZhangFei'"
print(pysqldf(sql))
- 作业
# 下表的数据,请使用Pandas中的DataFrame进行创建,并对数据进行清洗。同时新增一列“总和”计算每个人的三科成绩之和。
import pandas as pd
name = ['张飞', '关羽', '赵云', '黄忠', '典韦', '典韦']
data = {'Chinese':[66, 95, 95, 90, 80, 80], 'English':[65, 85, 92, 88, 90, 90], 'math': ['NaN', 98, 96, 77, 90, 90]}
score_df = pd.DataFrame(data, index = name)
# 去除重复行
score_df = score_df.drop_duplicates()
# 列名重新排序
cols = ['Chinese', 'English', 'Math']
score_df = score_df.filter(cols, axis=1)
# 列名改为中文
score_df,rename(columns={'Chinese':'语文', 'English':'英语', 'Math':'数学'}, inplace=True)
def total_score(df):
df['总分'] =df['语文'] + df['英语'] + df['数学']
return df
# 求成绩的和,用老师的apply方法
score_df = score_df.apply(total_score, axis=1)
# 或者用这个方法
# df['总分'] = df['语文'] + df['英语'] + df['数学']
# 按照总分排序,从高到低,此时有缺失值
score_df.sort_values(['总分'], ascending=[False', inplace=True)
# 打印显示成绩单信息,张飞有空值
print(score_df.isnull().sum())
print(score_df.decrible())
print(score_df)
# 使用数学成绩均值填充张飞同学的缺失值
score_df['数学'].fillna(df['数学'].mean(), inplace=True)
# 再次求成绩的和并打印显示成绩单情况
score_df = score_df.apply(total_score, axis=1)
print(score_df.isnull().sum())
print(score_df.describle())
print(score_df)
06 | 学数据分析要掌握哪些基本概念?
-
智能商业BI、数据仓库DW、数据挖掘DM三者之间的关系
积累顾客的消费行为习惯存储在数据仓库中,通过对个体进行消费行为分析总结出来的规律属于数据挖掘 -
元数据VS数据元
数据元组成的集合构成元数据 -
数据挖掘的流程
分类
聚类
预测
关联分析 -
数据预处理
数据清洗 -> 数据集成 -> 数据变换
数据清洗:去除重复,去噪声,填充缺失值
数据集成:将多个数据源中的数据放在一个统一的数据存储中。
数据变换:将数据转换成适合数据挖掘的形式。比如,通过归一化将属性数据按比例缩放,这样就可以将数值落入一个特定的区间内,比如0~1之间 -
KDD
knownledge discovery in database, 数据挖掘
07 | 用户画像:标签化就是数据堆抽象能力
精细化运营是长久的主题,讲“大数据”如何“赋能”企业。
- 用户画像的准则
用户画像建模:- 第一步统一化:统一用户的唯一标志
- 第二步标签化:给用户打标签,即用户画像
- 第三步业务化:将用户画像,指导业务关联
用户消费行为分析
1. 用户标签:性别、年龄、地域、收入、学历、职业
2. 消费标签:消费习惯、购买意向、是否对促销敏感。
3. 行为标签:时间段、频次、时长、访问路径。
4. 内容分析:对用户平时浏览的内容,尤其是停留时间长、浏览次数多的内容进行分析,分析出用户对哪些内容感兴趣,比如,金融、娱乐、教育、体育、时尚、科技

-
从用户生命周期的三个阶段划分业务价值,包括:获客、粘客和留客
- 获客:如何进行拉新,通过更精准的营销获取客户。
- 粘客:个性化推荐,搜索排序,场景运营等。
- 留客:流失率预测,分析关键节点降低流失率
-
用户画像建模的建模过程中的不同层
不同层都需要打不同的标签:- 数据层
- 算法层
- 业务层
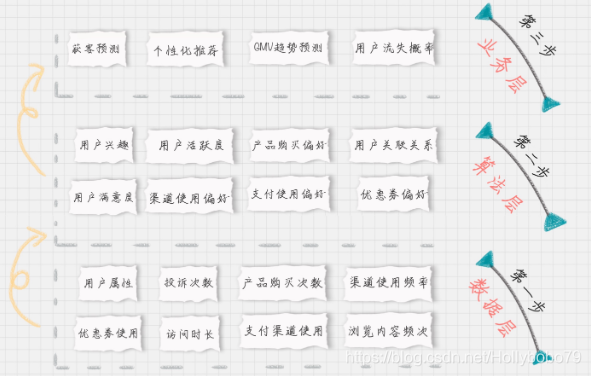
-
美团外卖的用户画像该如何设计
08 | 数据采集:如何自动化采集数据?
-
安数据源分类
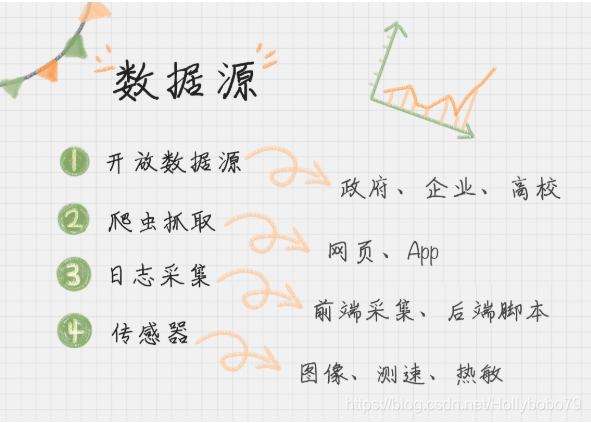
-
如何使用开放数据源
一个是单位维度:政府、企业、高校
一个是行业维度:交通、金融、能源 -
如何使用爬虫
Python爬虫的3个过程:- 使用Requests爬取内容;
- 使用XPath解析内容;
- 使用Pandas保存数据。
三款常用抓取工具:
火车采集器
八爪鱼
搜集客
-
如何使用日志采集工具
日志采集也是运维人员的重要工作之一,用以提高系统承载量。
日志中的信息包括:哪些人在什么时间,通过什么渠道(搜索引擎、网址输入)来过,都执行了哪些操作;系统是否产生了错误;甚至包括用户的IP、HTTP请求的时间,用户代理等。 -
日志采集可以分为两种形式
- 通过Web服务器采集,例如httpd、Nginx、Tomcat都有自带日志记录功能。其他如Hadoop的CHukwa、Cloudera的Flume、Facebook的Scribe。
- 自定义采集用户行为,例如用JavaScript代码监听用户行为、AJAX异步请求后台记录日志等。
-
埋点
埋点是日志采集的关键步骤
埋点就是在有需要的位置采集相应的信息,进行上报。 -
推荐埋点工具
“不重复造轮子”,一般核心业务自己写代码,埋点可以使用第三方统计工具。- 友盟
- Google Analysis
- Talkingdata
以上都是前端埋点
14 | 数据可视化
9种数据可视化视图
- 分布 (Distribution)
- 时间相关(Change Over Time)
- 局部/整体(Part To Whole)
- 偏差(Deviation)
- 相关性(Correlation)
- 排名(Ranking)
- 量级(Magnitude)
- 地图(Spatial)
- 流动(Flow)
数据可视化工具
商业智能分析
- Tableau(熟练掌握,找一份数据分析工作不难)
- PowerBI(微软出品,搭配Excel使用)
可视化大屏类
- DataV
- FineReport
前端可视化组件
可视化组件都是基于Web渲染技术的。Canvas和SVG是HTML5中主要的2D图形技术,WebGL是3D架构。
- Canvas
使用与位图 - SVG
可缩放矢量图 - WebGL
在网页中用于呈现3D画面技术。Three.js就是基于WebGL框架的。 - 常用可视化组件
Echarts、D3、Three.js、AntV。
编程语言
- Python
重点掌握Matplotlib、Seaborn