主要技术:
1. 使用requests.session模拟登录,带着session并以post形式请求要爬取的url(幸好还没有验证码)
2. 站点id及经纬度以json存在文件中,并读取
3. 爬取的数据写入Excel文件,csv格式
4. 将站点加入queue,进行队列分配
5. 开启多个线程来处理队列,一个线程完成任务后从队列取新的站点进行处理
6. 使用calendar库来取当月最后一天是多少号,每次取一个月的数据(最终结果有1G多)
7. 对年月日时间格式进行urlencode处理
8. 遍历10种类型的交通数据进行url构造
9. 将取的url中的数据进行分行,第一行为标题,标题中为A字典的键;其他行均为数据,数据再分割成列表,列表中的数据再做为A字典的值,即A字典键为标题,值为数据,由于type在循环,故每个类型的标题不断的增加进A字典,键在不断增加,最终大约80个键
10. 将上述A字典做为键为日期的值,形成B字典,即B字典键为日期,值为A字典
11. 将新字典的值遍历写入excel,对于数据中可能不存在的键,填充默认值为0
# -*- coding: utf-8 -*- import time, datetime, calendar import urllib, requests import queue, threading import json import os def worker(P): print("%s %s %s " % (datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'), P, "is working now...")) global pace while not Q.empty(): id, coord = Q.get() pace+=1 #3.1 构建Url time_start = '%02d/%02d/%04d %02d:%02d'%(month, 1, year, 0, 0) time_end = '%02d/%02d/%04d %02d:%02d'%(month, calendar.monthrange(year,month)[1], year, 23, 59) #获取当月最天一天日期 time_start_encode = urllib.parse.quote(time_start.encode('utf-8')) time_end_encode = urllib.parse.quote(time_end.encode('utf-8')) ts_start = int(time.mktime(time.strptime(time_start, "%m/%d/%Y %H:%M"))) + 8*3600 ts_end = int(time.mktime(time.strptime(time_end, "%m/%d/%Y %H:%M"))) + 8*3600 #一个站点一个大数据 big_data = {} types = ['flow','occ','speed','truck_flow','truck_prop','vmt','vht','q','tti','del_35'] for type in types: linestr = "" report_url = "http://btc.fangbei.org/?report_form=1&dnode=VDS&content=loops&export=text&station_id=%s&s_time_id=%s&s_time_id_f=%s&e_time_id=%s&e_time_id_f=%s&tod=all&tod_from=0&tod_to=0&dow_0=on&dow_1=on&dow_2=on&dow_3=on&dow_4=on&dow_5=on&dow_6=on&holidays=on&q=%s&q2=&gn=hour&agg=on&lane1=on&lane2=on&lane3=on&lane4=on" %(id, ts_start, time_start_encode, ts_end, time_end_encode, type) # print(report_url) #3.2 抓取数据 report = S.get(report_url) # print(report.text) list = report.text.split(" ") print('线程:%s 进度:%s/%s 年月:%4d%02d 站点:%s 类型:%s 长度:%s 链接:%s '%(P, pace, length, year, month, id, type, len(list), report_url)) #list[0] 为标题行 list[i]均为内容 title = list[0].split(" ") for i in range(1, len(list)): item = list[i].split(" ") if (len(item[0]) < 1): continue #获取行中的日期,转为时间戳 ts = int(time.mktime(time.strptime(item[0], "%m/%d/%Y %H:%M"))) #每一行数据 的处理 ''' 以title中的字符为键,item中的字符为值,不断的写入字典中''' dict_x = {} for i in range(len(title)): dict_x.setdefault((type+"_"+title[i]).replace(' ', ''), item[i].replace(',', '')) #加上type,区分不同类型下的同一字符 '''上三行组成的字典,做为一个新的值,键则为日期,键不存在则新建,存在则更新值进来''' if ts not in big_data: big_data[ts] = dict_x else: big_data[ts].update(dict_x) print('线程:%s 进度:%s/%s 年月:%4d%02d 站点:%s 开始写入数据 '%(P, pace, length, year, month, id) #遍历字典,写数据进来 for ts, data in big_data.items(): # print(data) dt = time.strptime(data["flow_Hour"],'%m/%d/%Y %H:%M') F.write('%s,%s,%s,%s,%s,%s,%s,%s, %s,%s,%s,%s,%s,%s, %s,%s,%s,%s,%s,%s, %s,%s,%s,%s,%s,%s, %s,%s,%s,%s,%s,%s, %s,%s,%s,%s,%s,%s, %s,%s,%s,%s,%s,%s, %s,%s,%s,%s,%s,%s, %s,%s,%s,%s,%s,%s, %s,%s,%s,%s,%s,%s, %s,%s,%s,%s,%s,%s '%( coord["lng"], coord["lat"], id, dt.tm_year, dt.tm_mon, dt.tm_mday, dt.tm_hour, data.get("flow_#LanePoints",0), data.get("flow_Flow(Veh/Hour)",0), data.get("flow_Lane1Flow(Veh/Hour)",0), data.get("flow_Lane2Flow(Veh/Hour)",0), data.get("flow_Lane3Flow(Veh/Hour)",0), data.get("flow_Lane4Flow(Veh/Hour)",0), data.get("flow_Lane5Flow(Veh/Hour)",0), data.get("occ_Occupancy(%)",0), data.get("occ_Lane1Occ(%)",0), data.get("occ_Lane2Occ(%)",0), data.get("occ_Lane3Occ(%)",0), data.get("occ_Lane4Occ(%)",0), data.get("occ_Lane5Occ(%)",0), data.get("speed_Speed(mph)",0), data.get("speed_Lane1Speed(mph)",0), data.get("speed_Lane2Speed(mph)",0), data.get("speed_Lane3Speed(mph)",0), data.get("speed_Lane4Speed(mph)",0), data.get("speed_Lane5Speed(mph)",0), data.get("truck_flow_TruckFlow(Veh/Hour)",0), data.get("truck_flow_Lane1TruckFlow(Veh/Hour)",0), data.get("truck_flow_Lane2TruckFlow(Veh/Hour)",0), data.get("truck_flow_Lane3TruckFlow(Veh/Hour)",0), data.get("truck_flow_Lane4TruckFlow(Veh/Hour)",0), data.get("truck_flow_Lane5TruckFlow(Veh/Hour)",0), data.get("truck_prop_TruckProp(%)",0), data.get("truck_prop_Lane1TruckProp(%)",0), data.get("truck_prop_Lane2TruckProp(%)",0), data.get("truck_prop_Lane3TruckProp(%)",0), data.get("truck_prop_Lane4TruckProp(%)",0), data.get("truck_prop_Lane5TruckProp(%)",0), data.get("vmt_VMT(Veh-Miles)",0), data.get("vmt_Lane1VMT(Veh-Miles)",0), data.get("vmt_Lane2VMT(Veh-Miles)",0), data.get("vmt_Lane3VMT(Veh-Miles)",0), data.get("vmt_Lane4VMT(Veh-Miles)",0), data.get("vmt_Lane5VMT(Veh-Miles)",0), data.get("vht_VHT(Veh-Hours)",0), data.get("vht_Lane1VHT(Veh-Hours)",0), data.get("vht_Lane2VHT(Veh-Hours)",0), data.get("vht_Lane3VHT(Veh-Hours)",0), data.get("vht_Lane4VHT(Veh-Hours)",0), data.get("vht_Lane5VHT(Veh-Hours)",0), data.get("q_Q(VMT/VHT)(mph)",0), data.get("q_Lane1Q(mph)",0), data.get("q_Lane2Q(mph)",0), data.get("q_Lane3Q(mph)",0), data.get("q_Lane4Q(mph)",0), data.get("q_Lane5Q(mph)",0), data.get("tti_TTI",0), data.get("tti_Lane1TTI",0), data.get("tti_Lane2TTI",0), data.get("tti_Lane3TTI",0), data.get("tti_Lane4TTI",0), data.get("tti_Lane5TTI",0), data.get("del_35_Delay(V_t=35)(Veh-Hours)",0), data.get("del_35_Lane1Delay(35)(Veh-Hours)",0), data.get("del_35_Lane2Delay(35)(Veh-Hours)",0), data.get("del_35_Lane3Delay(35)(Veh-Hours)",0), data.get("del_35_Lane4Delay(35)(Veh-Hours)",0), data.get("del_35_Lane5Delay(35)(Veh-Hours)",0) )) if __name__ == '__main__': #0. 配置 os.system("cls") year = 2019 month = 8 filename = 'data/%s/%4d%02d_V2_%s.csv'%(year, year, month, datetime.datetime.now().strftime('%Y%m%d%H%M%S')) #1. 登录 print("%s %4d%02d %s " % (datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'), year, month, "Ready to Login...")) url = 'http://btc.fangbei.org/' headers={ # 'Host': 'btc.fangbei.org', # 'Proxy-Connection': 'keep-alive', # 'Content-Length': '71', # 'Cache-Control': 'max-age=0', # 'Origin': 'http://btc.fangbei.org', # 'Upgrade-Insecure-Requests': '1', 'Content-Type': 'application/x-www-form-urlencoded', 'User-Agent': '来源 比特量化', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3', 'Referer': 'http://btc.fangbei.org/', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8' } S = requests.Session() S.headers = headers login = S.post(url, json="redirect=&username=yjn%40fangbei.org&password=123456%29&login=Login") print("%s %s " % (datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'), "Ready Go...")) #2. 获取站点ID,分配进队列 ides = json.load(open("id.json",'r')) #写文件 F = open(filename, 'a+') F.write('"Longtitude","Latitude","ID","Year","Month","Day","Hours","LanePoints", "Flow","Lane1Flow","Lane2Flow","Lane3Flow","Lane4Flow","Lane5Flow", "Occupancy","Lane1Occ","Lane2Occ","Lane3Occ","Lane4Occ","Lane5Occ", "Speed","Lane1Speed","Lane2Speed","Lane3Speed","Lane4Speed","Lane5Speed", "TruckFlow","Lane1TruckFlow","Lane2TruckFlow","Lane3TruckFlow","Lane4TruckFlow","Lane5TruckFlow", "TruckProp","Lane1TruckProp","Lane2TruckProp","Lane3TruckProp","Lane4TruckProp","Lane5TruckProp", "VMT","Lane1VMT","Lane2VMT","Lane3VMT","Lane4VMT","Lane5VMT", "VHT","Lane1VHT","Lane2VHT","Lane3VHT","Lane4VHT","Lane5VHT", "Q","Lane1Q","Lane2Q","Lane3Q","Lane4Q","Lane5Q", "TTI","Lane1TTI","Lane2TTI","Lane3TTI","Lane4TTI","Lane5TTI", "35_Delay","35_Lane1Delay","35_Lane2Delay","35_Lane3Delay","35_Lane4Delay","35_Lane5Delay" ') pace = 0 length = len(ides) #分配队列 Q = queue.Queue() for id, coord in ides.items(): Q.put((id, coord)) #开启多个线程 for i in range(4): t = threading.Thread(target=worker,args=('T%s'%(i),)) # t.setDaemon(True) t.start() # t.join()
id.json
{ "716391":{ "lat":34.151032, "lng":-118.680765 }, "716392":{ "lat":34.148836, "lng":-118.697394 }, "716402":{ "lat":33.931618, "lng":-118.394435 }, "716404":{ "lat":33.931388, "lng":-118.389223 } }
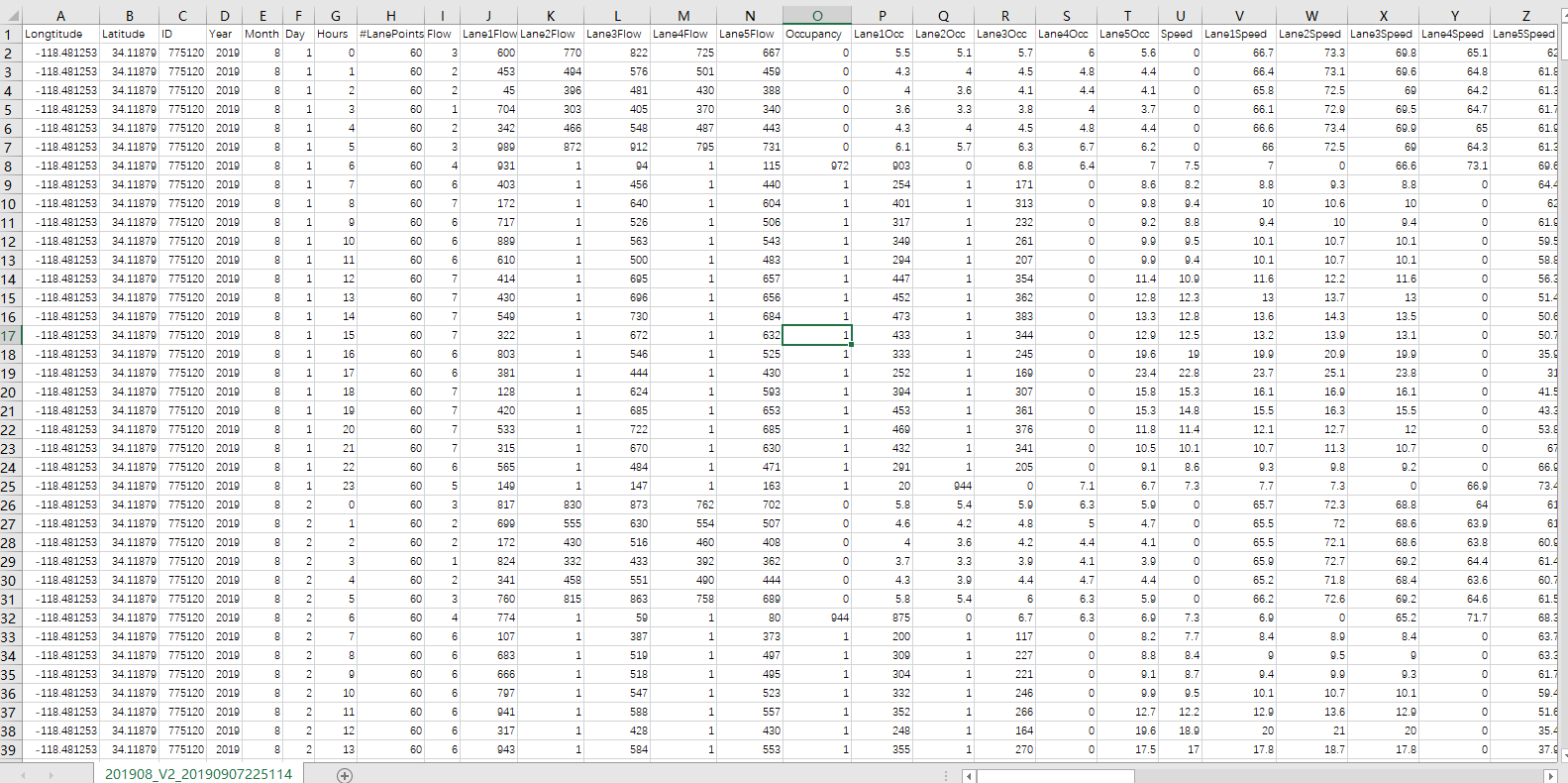
数据截图