什么是线程
在传统操作系统中,每个进程有一个地址空间,而且每个进程默认有一个控制线程
线程相当于一条流水线工作的过程,一条流水线一定属于一个车间,一个车间的工作过程就相当于一个进程
车间负责把资源整合到一起,是一个资源单位,而车间内至少有一个流水线,流水线的工作需要电源,CPU就相当于电源
进程只是把资源集中到一起,(进程只是一个资源单位,或者说资源集合),而线程才是CPU上的执行单位
多线程
多线程的概念是,在一个进程中存在多个控制线程,多个控制线程共享该进程的地址空间,相当于一个车间内有多条流水线,共用一个车间的资源
线程依赖于进程,一个进程可以包含多个线程,但一定有一个主进程,线程才是CPU执行的最小单元
例如:开启QQ
开启一个进程,在内存中开辟空间,加载数据,启动一个线程执行代码
线程和进程的区别
进程
划分空间,加载资源(静态)
开启进程开销大
开启多进程速度慢
进程之间数据不能直接共享(可以通过队列)
开启多个进程,每个进程都有不同的pid
线程
开启线程速度小
开启多线程速度快
同一进程下的线程数据可以共享
在主进程下开启的多个线程,每个线程的pid都和主进程一样
多线程的应用场景
并发:一个CPU来回切换(线程之间的切换)多进程并发 多线程并发
多进程并发:开启多个进程,每个进程里面的主线程执行任务
多线程并发:开启一个进程,此进程里面的多个线程执行任务
开启线程的两种方式


from threading import Thread def task(name): print(f'{name} is running') if __name__ == '__main__': t = Thread(target=task,args=('Leeson',)) t.start() print('主线程')
rom threading import Thread class MyThread(Thread): def run(self): print(f'{self.name} is running') if __name__ == '__main__': t = MyThread() t.start() print('主线程')
线程的一些方法
from threading import Thread import threading import time def task(name): time.sleep(1) print(f'{name} is running') print(threading.current_thread().name) if __name__ == '__main__': for i in range(5): t = Thread(target=task,args=('mcsaoQ',)) t.start() # 线程对象的方法: # time.sleep(1) # print(t.is_alive()) # 判断子线程是否存活 *** # print(t.getName()) # 获取线程名 # t.setName('线程111') # print(t.setName('alex')) # 获取线程名 # threading模块的方法: # print(threading.current_thread().name) # MainThread # print(threading.enumerate()) # 返回一个列表 放置的是所有的线程对象 print(threading.active_count()) # 获取活跃的线程的数量(包括主线程) print('主线程')
守护线程
无论是进程还是线程,都遵循守护XXX会等待主XX运行完毕后被销毁
强调:运行完毕并非终止运行
对于主进程来说
运行完毕指的是主进程代码运行完毕
主进程在其代码结束后就已经算运行完毕了(守护进程在此时就被回收),然后主进程会一直等非守护的子进程都运行完毕后回收子进程的资源(否则会产生僵尸进程),才会结束
对于主线程来说
运行完毕是指主线程所在的进程内所有非守护线程统统运行完毕,主线程才算运行完毕
主线程在其他非守护线程运行完毕后才算运行完毕(守护线程在此时就被回收)。因为主线程的结束意味着进程的结束,进程整体的资源都将被回收,而进程必须保证非守护线程都运行完毕后才能结束
from threading import Thread import time def sayhi(name): time.sleep(2) print('%s say hello' %name) if __name__ == '__main__': t=Thread(target=sayhi,args=('egon',)) t.setDaemon(True) #必须在t.start()之前设置 t.start() print('主线程') print(t.is_alive())
from threading import Thread import time def foo(): print(123) time.sleep(1) print("end123") def bar(): print(456) time.sleep(3) print("end456") t1=Thread(target=foo) t2=Thread(target=bar) t1.daemon=True t1.start() t2.start() print("main-------")
互斥锁
多线程的同步锁与多进程的同步锁是一个道理,就是多个线程抢占同一个数据(资源)时,我们要保证数据的安全,顺序的合理
要利用串行,多个线程抢占一个资源,如果不串行,就会发生问题
from threading import Thread from threading import Lock import time x = 100 lock = Lock() def task(): global x lock.acquire() temp = x time.sleep(0.1) temp -= 1 x = temp lock.release() if __name__ == '__main__': t_l1 = [] for i in range(100): t = Thread(target=task) t_l1.append(t) t.start() for i in t_l1: i.join() print(f'主{x}')
死锁现象,递归锁
进程也有死锁与递归锁问题,与线程的死锁与递归锁同理
死锁是指两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去
from threading import Thread from threading import Lock import time lock_A = Lock() lock_B = Lock() class MyThread(Thread): def run(self): self.f1() self.f2() def f1(self): lock_A.acquire() print(f'{self.name}拿到A锁') lock_B.acquire() print(f'{self.name}拿到B锁') lock_B.release() lock_A.release() def f2(self): lock_B.acquire() print(f'{self.name}拿到B锁') time.sleep(0.1) lock_A.acquire() print(f'{self.name}拿到A锁') lock_A.release() lock_B.release() if __name__ == '__main__': for i in range(3): t = MyThread() t.start() print('主....')
死锁现象的解决方法:递归锁。在Python中为了支持在同一线程中多次请求同一资源,python提供了可重入锁RLock。
递归锁就是一把锁,锁上有记录,只要acquire一次,锁上计数器就加一次,release一次,锁上计数就减一次
只要递归锁计数不为0,其它线程就不能争抢
from threading import Thread from threading import RLock import time lock_A = lock_B = RLock() class MyThread(Thread): def run(self): self.f1() self.f2() def f1(self): lock_A.acquire() print(f'{self.name}拿到A锁') lock_B.acquire() print(f'{self.name}拿到B锁') lock_B.release() lock_A.release() def f2(self): lock_B.acquire() print(f'{self.name}拿到B锁') time.sleep(0.1) lock_A.acquire() print(f'{self.name}拿到A锁') lock_A.release() lock_B.release() if __name__ == '__main__': for i in range(10): t = MyThread() t.start() print('主....')
信号量
之前的锁都只允许一个线程或进程进入,信号量允许多个线程或进程同时进入
信号量管理一个内置的计数器,
每当调用acquire()时内置计数器-1;
调用release() 时内置计数器+1;
计数器不能小于0;当计数器为0时,acquire()将阻塞线程直到其他线程调用release()。
实例:(同时只有5个线程可以获得semaphore,即可以限制最大连接数为5):
from threading import Thread from threading import Semaphore from threading import current_thread import time import random sem = Semaphore(5) def go_public_wc(): sem.acquire() print(f'{current_thread().getName()} 上厕所ing') time.sleep(random.randint(1,3)) sem.release() if __name__ == '__main__': for i in range(20): t = Thread(target=go_public_wc) t.start()
GIL锁
全局解释器锁
本身也是一把互斥锁(将并发变成串行,同一时刻只能有一个线程使用共享资源,牺牲效率,保证数据安全)
GIL锁详解
Python代码的执行由Python虚拟机(也叫解释器主循环)来控制。Python在设计之初就考虑到要在主循环中,同时只有一个线程在执行。虽然 Python 解释器中可以“运行”多个线程,但在任意时刻只有一个线程在解释器中运行。
对Python虚拟机的访问由全局解释器锁(GIL)来控制,正是这个锁能保证同一时刻只有一个线程在运行。
在多线程环境中,Python 虚拟机按以下方式执行:
a、设置 GIL;
b、切换到一个线程去运行;
c、运行指定数量的字节码指令或者线程主动让出控制(可以调用 time.sleep(0));
d、把线程设置为睡眠状态;
e、解锁 GIL;
d、再次重复以上所有步骤。
在调用外部代码(如 C/C++扩展函数)的时候,GIL将会被锁定,直到这个函数结束为止(由于在这期间没有Python的字节码被运行,所以不会做线程切换)编写扩展的程序员可以主动解锁GIL。
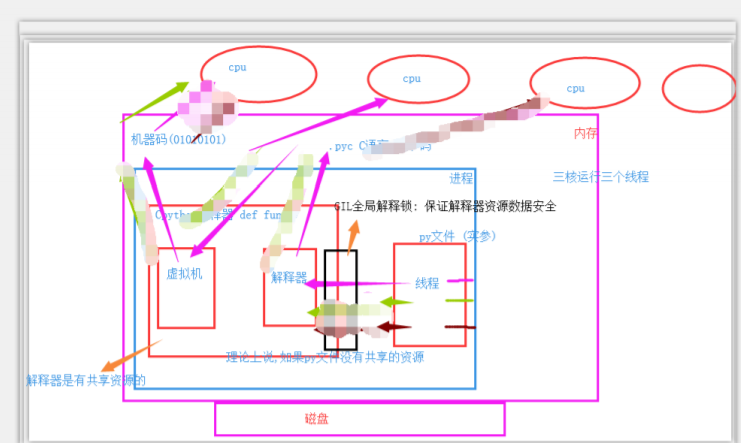
为什么有人说python处理并发不好
设置GIL锁保证了解释器里面的数据安全
在开发python语言时,计算机只有单核,没有考虑到多个CPU处理进程的问题
强行加GIL锁减轻了开发人员的负担,但也带来了几个问题:
单进程的多线程不能利用多核
多进程的多线程可以利用多核
多核前提下python处理任务的方式
开启四个进程,开启四个线程 from multiprocessing import Process from threading import Thread import time import os # print(os.cpu_count()) def task1(): res = 1 for i in range(1, 100000000): res += i def task2(): res = 1 for i in range(1, 100000000): res += i def task3(): res = 1 for i in range(1, 100000000): res += i def task4(): res = 1 for i in range(1, 100000000): res += i if __name__ == '__main__': # 四个进程 四个cpu 并行 效率 start_time = time.time() p1 = Process(target=task1) p2 = Process(target=task2) p3 = Process(target=task3) p4 = Process(target=task4) p1.start() p2.start() p3.start() p4.start() p1.join() p2.join() p3.join() p4.join() print(f'主: {time.time() - start_time}') # 7.53943133354187 # 一个进程 四个线程 1 cpu 并发 25.775474071502686 # start_time = time.time() # p1 = Thread(target=task1) # p2 = Thread(target=task2) # p3 = Thread(target=task3) # p4 = Thread(target=task4) # # p1.start() # p2.start() # p3.start() # p4.start() # # p1.join() # p2.join() # p3.join() # p4.join() # print(f'主: {time.time() - start_time}') # 25.775474071502686
多进程的并行比单进程多线程并发的效率高很多
讨论IO密集型: 通过大量的任务去验证. from multiprocessing import Process from threading import Thread import time import os # print(os.cpu_count()) def task1(): res = 1 time.sleep(3) if __name__ == '__main__': 开启150个进程(开销大,速度慢),执行IO任务, 耗时 9.293531656265259 start_time = time.time() l1 = [] for i in range(150): p = Process(target=task1) l1.append(p) p.start() for i in l1: i.join() print(f'主: {time.time() - start_time}') 开启150个线程(开销小,速度快),执行IO任务, 耗时 3.0261728763580322 start_time = time.time() l1 = [] for i in range(150): p = Thread(target=task1) l1.append(p) p.start() for i in l1: i.join() print(f'主: {time.time() - start_time}') # 3.0261728763580322
任务数量大,单进程下的多线程效率高
GIL锁与互斥锁的关系
GIL 自动上锁解锁,保护解释器的数据安全
互斥锁 手动上锁解锁,保护文件数据的安全
from threading import Thread from threading import Lock import time lock = Lock() x = 100 def task(): global x lock.acquire() temp = x # time.sleep(1) temp -= 1 x = temp lock.release() if __name__ == '__main__': t_l = [] for i in range(100): t = Thread(target=task) t_l.append(t) t.start() for i in t_l: i.join() print(f'主线程{x}')
线程全部是计算密集型:
当程序执行,开启多个线程,第一个线程要先拿到GIL锁,然后拿到LOCK锁,释放LOCK锁,最后释放GIL锁
from threading import Thread from threading import Lock import time lock = Lock() x = 100 def task(): global x lock.acquire() temp = x time.sleep(1) temp -= 1 x = temp lock.release() if __name__ == '__main__': t_l = [] for i in range(100): t = Thread(target=task) t_l.append(t) t.start() for i in t_l: i.join() print(f'主线程{x}')
线程全部是IO密集型:
当程序执行,开启多个线程,第一个线程要先拿到GIL锁,然后拿到LOCK锁,开始运行,遇到阻塞,CPU窃走,GIL释放,第一个线程挂起,第二个线程抢到GIL锁,接下来想抢LOCK锁,但LOCK锁还没被释放,阻塞,挂起,第三个线程进入......
进程池线程池
进程池:放置进程的一个容器
线程池:放置线程的一个容器
线程即使开销小,电脑也不可以无限的开进程,所以应该对线程(进程)做数量的限制,在计算机能满足的最大情况下,更多的创建线程(进程)
from concurrent.futures import ProcessPoolExecutor from concurrent.futures import ThreadPoolExecutor import time import os import random def task(name): print(name) print(f'{os.getpid()} 准备接客') time.sleep(random.randint(1,3)) if __name__ == '__main__': p = ProcessPoolExecutor() # 设置进程数量默认为cpu个数 for i in range(23): p.submit(task,1) # 给进程池放任务,传参
from concurrent.futures import ProcessPoolExecutor from concurrent.futures import ThreadPoolExecutor import time import os import random def task(name): print(name) print(f'{os.getpid()} 准备接客') time.sleep(random.randint(1,3)) if __name__ == '__main__': p = ThreadPoolExecutor() # ,默认cpu数量*5 for i in range(23): p.submit(task,1) # 给进程池放任务,传参
同步,异步 / 阻塞,非阻塞
阻塞时程序运行中表现的一种状态
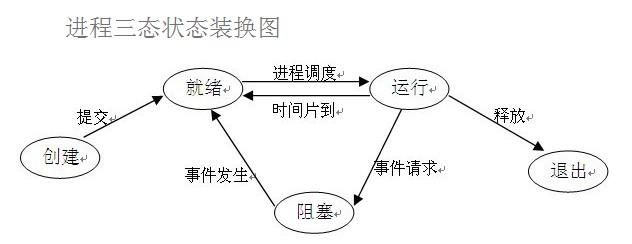
程序运行中表现的一种状态
阻塞:程序遇到IO会立即停止(挂起),CPU马上切换,等IO结束后再运行
非阻塞:程序没有IO或遇到IO通过某种手段让CPU去执行其它的任务,尽可能的占有CPU
站在任务发布的角度
同步:任务发出去后如果遇到IO,继续等待,直到这个任务最终结束,收到一个返回值,之后再发布下一个任务
同步发布任务:发布n个任务,先把第一个任务交给第一个进程,第一个进程完成之后再将第二个任务交给下一个进程
异步:所有任务同时发出,然后继续下一行代码
异步发布任务: 直接将n个任务交给m个进程,然后执行下一行代码,等结果
from concurrent.futures import ProcessPoolExecutor import os import time import random def task(): print(f'{os.getpid()} is running') time.sleep(random.randint(0,2)) return f'{os.getpid()} is finish' if __name__ == '__main__': p = ProcessPoolExecutor(4) obj_l1 = [] for i in range(10): obj = p.submit(task,) # 异步发出. obj_l1.append(obj) # time.sleep(3) p.shutdown(wait=True) # 1. 阻止在向进程池投放新任务, # 2. wait = True 十个任务是10,一个任务完成了-1,直至为零.进行下一行. # print(666) for i in obj_l1: print(i.result())
from concurrent.futures import ProcessPoolExecutor import os import time import random def task(): print(f'{os.getpid()} is running') time.sleep(1) return f'{os.getpid()} is finish' if __name__ == '__main__': p = ProcessPoolExecutor(4) for i in range(10): obj = p.submit(task,) print(obj.result())
异步 + 回调机制
通过模拟简单的爬虫举例
# 1 简单认识一下requests模块 # 第一步: 爬取服务端的文件(IO阻塞). # 第二步: 拿到文件,进行数据分析,(非IO,IO极少) import requests from concurrent.futures import ProcessPoolExecutor from multiprocessing import Process import time import random import os def get(url): response = requests.get(url) print(f'{os.getpid()} 正在爬取:{url}') time.sleep(random.randint(1,3)) if response.status_code == 200: return response.text def parse(text): ''' 对爬取回来的字符串的分析 简单用len模拟一下. :param text: :return: ''' print(f'{os.getpid()} 分析结果:{len(text)}') # get('http://www.taobao.com') # get('http://www.baidu.com') # get('http://www.JD.com') if __name__ == '__main__': url_list = [ 'http://www.taobao.com', 'http://www.JD.com', 'http://www.JD.com', 'http://www.JD.com', 'http://www.baidu.com', 'https://www.cnblogs.com/jin-xin/articles/11232151.html', 'https://www.cnblogs.com/jin-xin/articles/10078845.html', 'http://www.sina.com.cn', 'https://www.sohu.com', 'https://www.youku.com', ] pool = ProcessPoolExecutor(4) obj_list = [] for url in url_list: obj = pool.submit(get, url) obj_list.append(obj) pool.shutdown(wait=True) for obj in obj_list: parse(obj.result()) ''' 串行 obj_list[0].result() obj_list[1].result() obj_list[2].result() obj_list[3].result() obj_list[4].result() '''
问题出在哪里? 1. 分析结果的过程是串行,效率低. 2. 你将所有的结果全部都爬取成功之后,放在一个列表中,分析. 问题1解决: 在开进程池,再开进程,耗费资源. 爬取一个网页需要2s,并发爬取10个网页:2.多s. 分析任务: 1s. 10s. 总共12.多秒. 现在这个版本的过程: 异步发出10个爬取网页的任务,然后4个进程并发(并行)的先去完成4个爬取网页的任务,然后谁先结束,谁进行下一个 爬取任务,直至10个任务全部爬取成功. 将10个爬取结果放在一个列表中,串行的分析. 爬取一个网页需要2s,分析任务: 1s,总共3s,总共3.多秒(开启进程损耗). . 10s. 下一个版本的过程: 异步发出10个 爬取网页+分析 的任务,然后4个进程并发(并行)的先去完成4个爬取网页+分析 的任务, 然后谁先结束,谁进行下一个 爬取+分析 任务,直至10个爬取+分析 任务全部完成成功.
版本二: 异步处理: 获取结果的第二种方式: 完成一个任务返回一个结果,完成一个任务,返回一个结果 并发的返回. import requests from concurrent.futures import ProcessPoolExecutor from multiprocessing import Process import time import random import os def get(url): response = requests.get(url) print(f'{os.getpid()} 正在爬取:{url}') time.sleep(random.randint(1,3)) if response.status_code == 200: parse(response.text) def parse(text): ''' 对爬取回来的字符串的分析 简单用len模拟一下. :param text: :return: ''' print(f'{os.getpid()} 分析结果:{len(text)}') if __name__ == '__main__': url_list = [ 'http://www.taobao.com', 'http://www.JD.com', 'http://www.JD.com', 'http://www.JD.com', 'http://www.baidu.com', 'https://www.cnblogs.com/jin-xin/articles/11232151.html', 'https://www.cnblogs.com/jin-xin/articles/10078845.html', 'http://www.sina.com.cn', 'https://www.sohu.com', 'https://www.youku.com', ] pool = ProcessPoolExecutor(4) for url in url_list: obj = pool.submit(get, url) # pool.shutdown(wait=True) print('主')
版本二几乎完美,但是两个任务有耦合性. 再上一个基础上,对其进程解耦 — 回调函数
import requests from concurrent.futures import ProcessPoolExecutor from multiprocessing import Process import time import random import os def get(url): response = requests.get(url) print(f'{os.getpid()} 正在爬取:{url}') # time.sleep(random.randint(1,3)) if response.status_code == 200: return response.text def parse(obj): ''' 对爬取回来的字符串的分析 简单用len模拟一下. :param text: :return: ''' time.sleep(1) print(f'{os.getpid()} 分析结果:{len(obj.result())}') if __name__ == '__main__': url_list = [ 'http://www.taobao.com', 'http://www.JD.com', 'http://www.JD.com', 'http://www.JD.com', 'http://www.baidu.com', 'https://www.cnblogs.com/jin-xin/articles/11232151.html', 'https://www.cnblogs.com/jin-xin/articles/10078845.html', 'http://www.sina.com.cn', 'https://www.sohu.com', 'https://www.youku.com', ] start_time = time.time() pool = ProcessPoolExecutor(4) for url in url_list: obj = pool.submit(get, url) obj.add_done_callback(parse) # 增加一个回调函数 # 现在的进程完成的还是网络爬取的任务,拿到了返回值之后,结果丢给回调函数add_done_callback, # 回调函数帮助你分析结果 # 进程继续完成下一个任务. pool.shutdown(wait=True) print(f'主: {time.time() - start_time}')
回调函数是主进程帮助你实现的, 回调函数帮你进行分析任务. 明确了进程的任务: 只有一个网络爬取. 分析任务: 回调函数执行了.对函数之间解耦. 极值情况: 如果回调函数是IO任务,那么由于你的回调函数是主进程做的,所以有可能影响效率. 回调不是万能的,如果回调的任务是IO, 那么异步 + 回调机制 不好.此时如果你要效率只能牺牲开销,再开一个线程进程池. 异步就是回调! 这个是错的!! 异步,回调是两个概念. 如果多个任务,多进程多线程处理的IO任务. 1. 剩下的任务 非IO阻塞. 异步 + 回调机制 2. 剩下的任务 IO << 多个任务的IO 异步 + 回调机制 3. 剩下的任务 IO >= 多个任务的IO 第二种解决方式,或者两个进程线程池.
事件Event
并发的执行某个任务,多线程多进程,几乎同时执行
如果想要一个线程执行到中间时通知另一个线程开始执行
import time from threading import Thread from threading import current_thread flag = False def task(): print(f'{current_thread().name} 检测服务器是否正常开启....') time.sleep(3) global flag flag = True def task1(): while 1: time.sleep(1) print(f'{current_thread().name} 正在尝试连接服务器.....') if flag: print('连接成功') return if __name__ == '__main__': t1 = Thread(target=task1,) t2 = Thread(target=task1,) t3 = Thread(target=task1,) t = Thread(target=task) t.start() t1.start() t2.start() t3.start()
import time from threading import Thread from threading import current_thread from threading import Event event = Event() # 默认是False def task(): print(f'{current_thread().name} 检测服务器是否正常开启....') time.sleep(3) event.set() # 改成了True def task1(): print(f'{current_thread().name} 正在尝试连接服务器') # event.wait() # 轮询检测event是否为True,当其为True,继续下一行代码. 阻塞. event.wait(1) # 设置超时时间,如果1s中以内,event改成True,代码继续执行. # 设置超时时间,如果超过1s中,event没做改变,代码继续执行. print(f'{current_thread().name} 连接成功') if __name__ == '__main__': t1 = Thread(target=task1,) t2 = Thread(target=task1,) t3 = Thread(target=task1,) t = Thread(target=task) t.start() t1.start() t2.start() t3.start()