Limiting Sets 限制集合 Working with Auto-Exists 自动存在如何干活的
读完和实践完这一小章节例子后,我对这样的Limiting Sets 和 Working with Auto-Exists 有自己的理解。Limiting Sets 可以理解为SSAS 限制了Sets 集合的大小,如何限制的呢?我理解就是这里的 “Auto-Exists”自动存在,通俗理解就是两个Sets 集合之间成员与成员存在某种关联关系的时候才匹配在一起,没有关系的忽略,这就是自动(匹配是否)存在的意思。
为什么要限制,我们可以通过以下这些例子来加深和理解。
示例一
SELECT
{
([Date].[Calendar].[CY 2002]),
([Date].[Calendar].[CY 2003]),
([Date].[Calendar].[CY 2004])
} *
{
([Measures].[Reseller Sales Amount]),
([Measures].[Internet Sales Amount])
} ON COLUMNS,
{[Product].[Category].[Category].Members} ON ROWS
FROM [Step-by-Step]
WHERE ([Geography].[Country].[United States]);

Messages 里面的内容
Executing the query ...
Obtained object of type: Microsoft.AnalysisServices.AdomdClient.CellSet
Formatting.
Cell set consists of 6 rows and 7 columns.
Done formatting.
Execution complete
在 SELECT 语句的 COLUMNS 中,第一个集合有3个元组,第二个集合有2个度量值元组,通过CrossJoin 或者 * 运算可以算出总共应该有 3*2=6 个列。在 SELECT 语句的 ROWS 中,只有4个成员。所以最终 SSAS 查询返回的结果应该是一个 4行6列这样的一个结果,再加上行表头和列表头,所以最终一起返回 6行7列,这个过程和结果是正确的。
示例二
在开始示例二之前,先看这样的一个例子。
WITH MEMBER [Measures].[Subcategory Count]
AS
COUNT([Product].[Subcategory].[Subcategory].Members)
SELECT [Measures].[Subcategory Count] ON COLUMNS
FROM [Step-by-Step];
这个例子就是计算一下Subcategory Level 下总共有多少个成员,通过查询总共有37个。
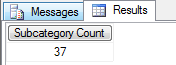
先记住这个数字,然后再开始我们的例子。
SELECT
{
([Date].[Calendar].[CY 2002]),
([Date].[Calendar].[CY 2003]),
([Date].[Calendar].[CY 2004])
} *{
([Measures].[Reseller Sales Amount]),
([Measures].[Internet Sales Amount])
} ON COLUMNS,
{[Product].[Category].[Category].Members} *
{[Product].[Subcategory].[Subcategory].Members} ON ROWS
FROM [Step-by-Step]
WHERE ([Geography].[Country].[United States])
按照我们在示例一中的理解,在 SELECT 语句中的 COLUMNS 结构里,总共有6个列。
在 SELECT 语句中的 ROWS 结构里,总共应该是有 4*37 = 148 行。再加上 Calendar 和 Measures 组成的2行的列标题以及 Category 和 Subcategory 组合起来占用了2列的行标题,那么总共 SSAS 返回到我们的查询客户端应该总共是 150行8列的内容。
我们先查询,然后查看Messages 信息。
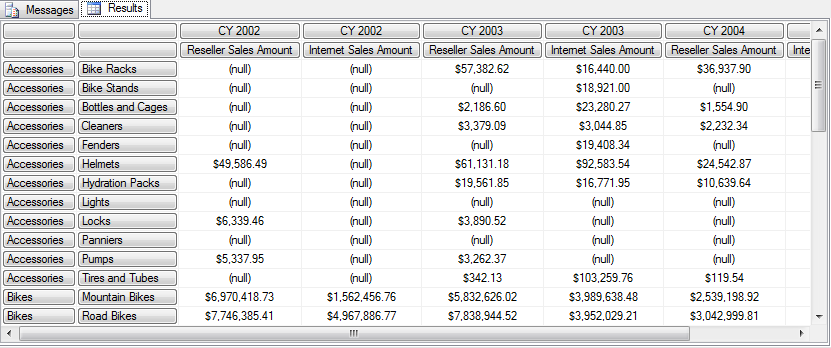
Messages 里的信息
Executing the query ...
Obtained object of type: Microsoft.AnalysisServices.AdomdClient.CellSet
Formatting.
Cell set consists of 39 rows and 8 columns.
Done formatting.
Execution complete
和我们预计不一样的地方是-总共只返回了 39行和8列,列的数目是我们所期望的, 但是39行与我们所期望的150行相差太远。
原因就在于在 SSAS 中, 虽然我们使用的是 Cross Join 或者 * 使两个集合中的元素交叉相乘,但是SSAS 在处理的时候并不会把两个没有任何关联关系的成员放在一起形成一行数据。例如, Subcategory 中的 Mountain Bikes 只会属于 Category 下的 Bikes 而不会属于 Category 中的 Accessories。所以即使让 Category Cross Join Subcategory,Subcategory 也只会找自己相关联的父属性。因此可以想象的到,总共有37个Subcategory,那么最终返回的也应该是37 行数据再加上2行的列标题,Subcategory 会自动地被分类到各自的Category 下。一个Category 有一个或者多个Subcategory,而每一个Subcategory 只会属于一个 Category。
另外还有一点就是 Category 和 Subcategory 是有直接的关联关系的,它们存在于Product里的层次结构中,这一点可以在 Product 纬度结构中看得到。
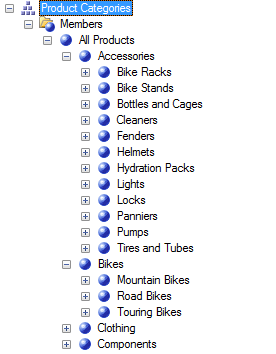
另外,即使在层次结构中查不到这种直接的关联样式,但是也不能否定它们在纬度表中也一定存在这种直接关联的关系。
这大概就应该是 Limiting Sets 限制集合大小 和 Auto-Exists 自动存在的解释,可能Auto-Exists 应该叫做 Auto-Matching 比较好。
下面示例三要解释的是一个没有直接关联关系的Cross Join,来看看 Auto-Exists 是否还发生了作用。
WITH MEMBER [Measures].[Color Type]
AS
COUNT([Product].[Color].[Color].Members )
SELECT [Measures].[Color Type] ON COLUMNS
FROM [Step-by-Step];
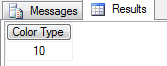
查看一下 Color 的种类,通过查询发现有10个颜色分类。
示例三
SELECT
{
([Date].[Calendar].[CY 2002]),
([Date].[Calendar].[CY 2003]),
([Date].[Calendar].[CY 2004])
} *
{
([Measures].[Reseller Sales Amount]),
([Measures].[Internet Sales Amount])
} ON COLUMNS,
{[Product].[Category].[Category].Members} *
{[Product].[Color].[Color].Members} ON ROWS
FROM [Step-by-Step]
WHERE ([Geography].[Country].[United States])
按照最原始的分析,行的数目应该是 4*10 = 40 行,再加上两行的列表头总共是42行。
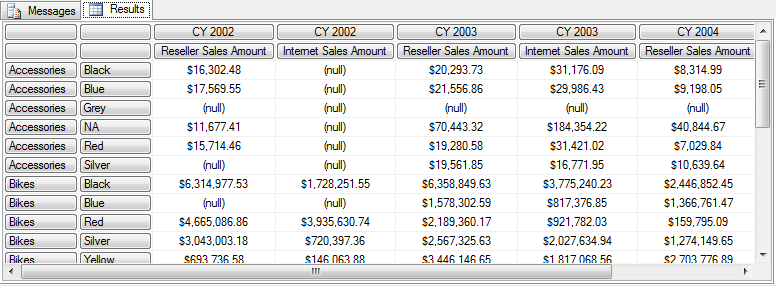
但是看看 Messages 的内容总共只返回了25行-2行= 23行数据。
Executing the query ...
Obtained object of type: Microsoft.AnalysisServices.AdomdClient.CellSet
Formatting.
Cell set consists of 25 rows and 8 columns.
Done formatting.
Execution complete
说明 Auto-Exists 起了作用,就不在这里一一验证它们匹配是否正确不正确了。
最后一个示例来说明在切片轴的处理过程中,Auto-Exists 也起到了作用。
示例四
SELECT
{
([Date].[Calendar].[CY 2002]),
([Date].[Calendar].[CY 2003]),
([Date].[Calendar].[CY 2004])
} *
{
([Measures].[Reseller Sales Amount]),
([Measures].[Internet Sales Amount])
} ON COLUMNS,
{[Product].[Category].[Category].Members} *
{[Product].[Color].[Color].Members} ON ROWS
FROM [Step-by-Step]
WHERE ([Geography].[Country].[United States],
[Product].[Subcategory].[Mountain Bikes])
在WHERE 条件中加上了一个[Product].[Subcategory].[Mountain Bikes].这里最主要要表达的是在限制完 [Product].[Subcategory].[Mountain Bikes] 这个空间后,Product Category 使用了一个 Cross Join 和Product Color进行了一个交叉连接,那么它们也超不过 Mountain Bikes 这个范围,这也是 Auto-Exists 起到的作用。

返回的数据一定是属于 Mountain Bikes 这个Subcategory的,当然也属于 United States 的范畴。
更多 BI 文章请参看 BI 系列随笔列表 (SSIS, SSRS, SSAS, MDX, SQL Server) 如果觉得这篇文章看了对您有帮助,请帮助推荐,以方便他人在 BIWORK 博客推荐栏中快速看到这些文章。