1. 什么是阻塞队列?
阻塞队列(BlockingQueue)是一个支持两个附加操作的队列。这两个附加的操作是:在队列为空时,获取元素的线程会等待队列变为非空。当队列满时,存储元素的线程会等待队列可用。阻塞队列常用于生产者和消费者的场景,生产者是往队列里添加元素的线程,消费者是从队列里拿元素的线程。阻塞队列就是生产者存放元素的容器,而消费者也只从容器里拿元素。
阻塞队列提供了四种处理方法:
| 方法处理方式 | 抛出异常 | 返回特殊值 | 一直阻塞 | 超时退出 |
|---|---|---|---|---|
| 插入方法 | add(e) | offer(e) | put(e) | offer(e,time,unit) |
| 移除方法 | remove() | poll() | take() | poll(time,unit) |
| 检查方法 | element() | peek() | 不可用 | 不可用 |
异常:是指当阻塞队列满时候,再往队列里插入元素,会抛出IllegalStateException("Queue full")异常。当队列为空时,从队列里获取元素时会抛出NoSuchElementException异常 。
返回特殊值:插入方法会返回是否成功,成功则返回true。移除方法,则是从队列里拿出一个元素,如果没有则返回null- 一直阻塞:当阻塞队列满时,如果生产者线程往队列里put元素,队列会一直阻塞生产者线程,直到拿到数据,或者响应中断退出。当队列空时,消费者线程试图从队列里take元素,队列也会阻塞消费者线程,直到队列可用。
- 超时退出:当阻塞队列满时,队列会阻塞生产者线程一段时间,如果超过一定的时间,生产者线程就会退出。
详细介绍BlockingQueue,以下是涉及的主要内容:
- BlockingQueue的核心方法
- 阻塞队列的成员的概要介绍
- 详细介绍DelayQueue、ArrayBlockingQueue、LinkedBlockingQueue的原理
- 线程池与BlockingQueue
| 1、初识阻塞队列 |
在新增的Concurrent包中,BlockingQueue很好的解决了多线程中,如何高效安全“传输”数据的问题。通过这些高效并且线程安全的队列类,为我们快速搭建高质量的多线程程序带来极大的便利。本文详细介绍了BlockingQueue家庭中的所有成员,包括他们各自的功能以及常见使用场景。
BlockingQueue的核心方法:
public interface BlockingQueue<E> extends Queue<E> {
//将给定元素设置到队列中,如果设置成功返回true, 否则抛出异常。如果是往限定了长度的队列中设置值,推荐使用offer()方法。
boolean add(E e);
//将给定的元素设置到队列中,如果设置成功返回true, 否则返回false. e的值不能为空,否则抛出空指针异常。
boolean offer(E e);
//将元素设置到队列中,如果队列中没有多余的空间,该方法会一直阻塞,直到队列中有多余的空间。
void put(E e) throws InterruptedException;
//将给定元素在给定的时间内设置到队列中,如果设置成功返回true, 否则返回false.
boolean offer(E e, long timeout, TimeUnit unit)
throws InterruptedException;
//从队列中获取值,如果队列中没有值,线程会一直阻塞,直到队列中有值,并且该方法取得了该值。
E take() throws InterruptedException;
//在给定的时间里,从队列中获取值,如果没有取到会抛出异常。
E poll(long timeout, TimeUnit unit)
throws InterruptedException;
//获取队列中剩余的空间。
int remainingCapacity();
//从队列中移除指定的值。
boolean remove(Object o);
//判断队列中是否拥有该值。
public boolean contains(Object o);
//将队列中值,全部移除,并发设置到给定的集合中。
int drainTo(Collection<? super E> c);
//指定最多数量限制将队列中值,全部移除,并发设置到给定的集合中。
int drainTo(Collection<? super E> c, int maxElements);
}
在深入之前先了解下下ReentrantLock 和 Condition:
重入锁ReentrantLock:
ReentrantLock锁在同一个时间点只能被一个线程锁持有;而可重入的意思是,ReentrantLock锁,可以被单个线程多次获取。
ReentrantLock分为“公平锁”和“非公平锁”。它们的区别体现在获取锁的机制上是否公平。“锁”是为了保护竞争资源,防止多个线程同时操作线程而出错,ReentrantLock在同一个时间点只能被一个线程获取(当某线程获取到“锁”时,其它线程就必须等待);ReentraantLock是通过一个FIFO的等待队列来管理获取该锁所有线程的。在“公平锁”的机制下,线程依次排队获取锁;而“非公平锁”在锁是可获取状态时,不管自己是不是在队列的开头都会获取锁。
主要方法:
- lock()获得锁
- lockInterruptibly()获得锁,但优先响应中断
- tryLock()尝试获得锁,成功返回true,否则false,该方法不等待,立即返回
- tryLock(long time,TimeUnit unit)在给定时间内尝试获得锁
- unlock()释放锁
Condition:await()、signal()方法分别对应之前的Object的wait()和notify()
- 和重入锁一起使用
- await()是当前线程等待同时释放锁
- awaitUninterruptibly()不会在等待过程中响应中断
- signal()用于唤醒一个在等待的线程,还有对应的singalAll()方法
| 2、阻塞队列的成员 |
| 队列 | 有界性 | 锁 | 数据结构 |
|---|---|---|---|
| ArrayBlockingQueue | bounded(有界) | 加锁 | arrayList |
| LinkedBlockingQueue | optionally-bounded | 加锁 | linkedList |
| PriorityBlockingQueue | unbounded | 加锁 | heap |
| DelayQueue | unbounded | 加锁 | heap |
| SynchronousQueue | bounded | 加锁 | 无 |
| LinkedTransferQueue | unbounded | 加锁 | heap |
| LinkedBlockingDeque | unbounded | 无锁 | heap |
下面分别简单介绍一下:
-
ArrayBlockingQueue:是一个用数组实现的有界阻塞队列,此队列按照先进先出(FIFO)的原则对元素进行排序。支持公平锁和非公平锁。【注:每一个线程在获取锁的时候可能都会排队等待,如果在等待时间上,先获取锁的线程的请求一定先被满足,那么这个锁就是公平的。反之,这个锁就是不公平的。公平的获取锁,也就是当前等待时间最长的线程先获取锁】
- LinkedBlockingQueue:一个由链表结构组成的有界队列,此队列的长度为Integer.MAX_VALUE。此队列按照先进先出的顺序进行排序。
- PriorityBlockingQueue: 一个支持线程优先级排序的无界队列,默认自然序进行排序,也可以自定义实现compareTo()方法来指定元素排序规则,不能保证同优先级元素的顺序。
- DelayQueue: 一个实现PriorityBlockingQueue实现延迟获取的无界队列,在创建元素时,可以指定多久才能从队列中获取当前元素。只有延时期满后才能从队列中获取元素。(DelayQueue可以运用在以下应用场景:1.缓存系统的设计:可以用DelayQueue保存缓存元素的有效期,使用一个线程循环查询DelayQueue,一旦能从DelayQueue中获取元素时,表示缓存有效期到了。2.定时任务调度。使用DelayQueue保存当天将会执行的任务和执行时间,一旦从DelayQueue中获取到任务就开始执行,从比如TimerQueue就是使用DelayQueue实现的。)
- SynchronousQueue: 一个不存储元素的阻塞队列,每一个put操作必须等待take操作,否则不能添加元素。支持公平锁和非公平锁。SynchronousQueue的一个使用场景是在线程池里。Executors.newCachedThreadPool()就使用了SynchronousQueue,这个线程池根据需要(新任务到来时)创建新的线程,如果有空闲线程则会重复使用,线程空闲了60秒后会被回收。
- LinkedTransferQueue: 一个由链表结构组成的无界阻塞队列,相当于其它队列,LinkedTransferQueue队列多了transfer和tryTransfer方法。
-
LinkedBlockingDeque: 一个由链表结构组成的双向阻塞队列。队列头部和尾部都可以添加和移除元素,多线程并发时,可以将锁的竞争最多降到一半。
接下来重点介绍下:ArrayBlockingQueue、LinkedBlockingQueue以及DelayQueue
| 3、阻塞队列原理以及使用 |
(1)DelayQueue
DelayQueue的泛型参数需要实现Delayed接口,Delayed接口继承了Comparable接口,DelayQueue内部使用非线程安全的优先队列(PriorityQueue),并使用Leader/Followers模式,最小化不必要的等待时间。DelayQueue不允许包含null元素。
Leader/Followers模式:
- 有若干个线程(一般组成线程池)用来处理大量的事件
- 有一个线程作为领导者,等待事件的发生;其他的线程作为追随者,仅仅是睡眠。
- 假如有事件需要处理,领导者会从追随者中指定一个新的领导者,自己去处理事件。
- 唤醒的追随者作为新的领导者等待事件的发生。
- 处理事件的线程处理完毕以后,就会成为追随者的一员,直到被唤醒成为领导者。
- 假如需要处理的事件太多,而线程数量不够(能够动态创建线程处理另当别论),则有的事件可能会得不到处理。
所有线程会有三种身份中的一种:leader和follower,以及一个干活中的状态:proccesser。它的基本原则就是,永远最多只有一个leader。而所有follower都在等待成为leader。线程池启动时会自动产生一个Leader负责等待网络IO事件,当有一个事件产生时,Leader线程首先通知一个Follower线程将其提拔为新的Leader,然后自己就去干活了,去处理这个网络事件,处理完毕后加入Follower线程等待队列,等待下次成为Leader。这种方法可以增强CPU高速缓存相似性,及消除动态内存分配和线程间的数据交换。
参数以及构造函数:
// 可重入锁
private final transient ReentrantLock lock = new ReentrantLock();
// 存储队列元素的队列——优先队列
private final PriorityQueue<E> q = new PriorityQueue<E>();
//用于优化阻塞通知的线程元素leader,Leader/Followers模式
private Thread leader = null;
//用于实现阻塞和通知的Condition对象
private final Condition available = lock.newCondition();
public DelayQueue() {}
public DelayQueue(Collection<? extends E> c) {
this.addAll(c);
}
先看offer()方法:
public boolean offer(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
q.offer(e);
// 如果原来队列为空,重置leader线程,通知available条件
if (q.peek() == e) {
leader = null;
available.signal();
}
return true;
} finally {
lock.unlock();
}
}
//因为DelayQueue不限制长度,因此添加元素的时候不会因为队列已满产生阻塞,因此带有超时的offer方法的超时设置是不起作用的
public boolean offer(E e, long timeout, TimeUnit unit) {
// 和不带timeout的offer方法一样
return offer(e);
}普通的poll()方法:如果延迟时间没有耗尽的话,直接返回null
public E poll() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
E first = q.peek();
if (first == null || first.getDelay(TimeUnit.NANOSECONDS) > 0)
return null;
else
return q.poll();
} finally {
lock.unlock();
}
}再看看take()方法:
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) {
// 如果队列为空,需要等待available条件被通知
E first = q.peek();
if (first == null)
available.await();
else {
long delay = first.getDelay(TimeUnit.NANOSECONDS);
// 如果延迟时间已到,直接返回第一个元素
if (delay <= 0)
return q.poll();
// leader线程存在表示有其他线程在等待,那么当前线程肯定需要等待
else if (leader != null)
available.await();
else {
Thread thisThread = Thread.currentThread();
leader = thisThread;
// 如果没有leader线程,设置当前线程为leader线程
// 尝试等待直到延迟时间耗尽(可能提前返回,那么下次
// 循环会继续处理)
try {
available.awaitNanos(delay);
} finally {
// 如果leader线程还是当前线程,重置它用于下一次循环。
// 等待available条件时,锁可能被其他线程占用从而导致
// leader线程被改变,所以要检查
if (leader == thisThread)
leader = null;
}
}
}
}
} finally {
// 如果没有其他线程在等待,并且队列不为空,通知available条件
if (leader == null && q.peek() != null)
available.signal();
lock.unlock();
}
}最后看看带有timeout的poll方法:
public E poll(long timeout, TimeUnit unit) throws InterruptedException {
long nanos = unit.toNanos(timeout);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) {
E first = q.peek();
if (first == null) {
if (nanos <= 0)
return null;
else
// 尝试等待available条件,记录剩余的时间
nanos = available.awaitNanos(nanos);
} else {
long delay = first.getDelay(TimeUnit.NANOSECONDS);
if (delay <= 0)
return q.poll();
if (nanos <= 0)
return null;
// 当leader线程不为空时(此时delay>=nanos),等待的时间
// 似乎delay更合理,但是nanos也可以,因为排在当前线程前面的
// 其他线程返回时会唤醒available条件从而返回,
if (nanos < delay || leader != null)
nanos = available.awaitNanos(nanos);
else {
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
long timeLeft = available.awaitNanos(delay);
// nanos需要更新
nanos -= delay - timeLeft;
} finally {
if (leader == thisThread)
leader = null;
}
}
}
}
} finally {
if (leader == null && q.peek() != null)
available.signal();
lock.unlock();
}
}(2)ArrayBlockingQueue
参数以及构造函数:
// 存储队列元素的数组
final Object[] items;
// 拿数据的索引,用于take,poll,peek,remove方法
int takeIndex;
// 放数据的索引,用于put,offer,add方法
int putIndex;
// 元素个数
int count;
// 可重入锁
final ReentrantLock lock;
// notEmpty条件对象,由lock创建
private final Condition notEmpty;
// notFull条件对象,由lock创建
private final Condition notFull;
public ArrayBlockingQueue(int capacity) {
this(capacity, false);//默认构造非公平锁的阻塞队列
}
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.items = new Object[capacity];
//初始化ReentrantLock重入锁,出队入队拥有这同一个锁
lock = new ReentrantLock(fair);
//初始化非空等待队列
notEmpty = lock.newCondition();
//初始化非满等待队列
notFull = lock.newCondition();
}
public ArrayBlockingQueue(int capacity, boolean fair,
Collection<? extends E> c) {
this(capacity, fair);
final ReentrantLock lock = this.lock;
lock.lock(); // Lock only for visibility, not mutual exclusion
try {
int i = 0;
//将集合添加进数组构成的队列中
try {
for (E e : c) {
checkNotNull(e);
items[i++] = e;
}
} catch (ArrayIndexOutOfBoundsException ex) {
throw new IllegalArgumentException();
}
count = i;
putIndex = (i == capacity) ? 0 : i;
} finally {
lock.unlock();
}
}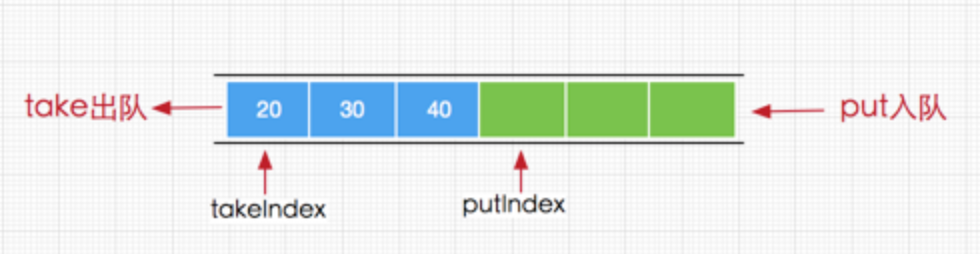
添加的实现原理:
这里的add方法和offer方法最终调用的是enqueue(E x)方法,其方法内部通过putIndex索引直接将元素添加到数组items中,这里可能会疑惑的是当putIndex索引大小等于数组长度时,需要将putIndex重新设置为0,这是因为当前队列执行元素获取时总是从队列头部获取,而添加元素从中从队列尾部获取所以当队列索引(从0开始)与数组长度相等时,下次我们就需要从数组头部开始添加了,如下图演示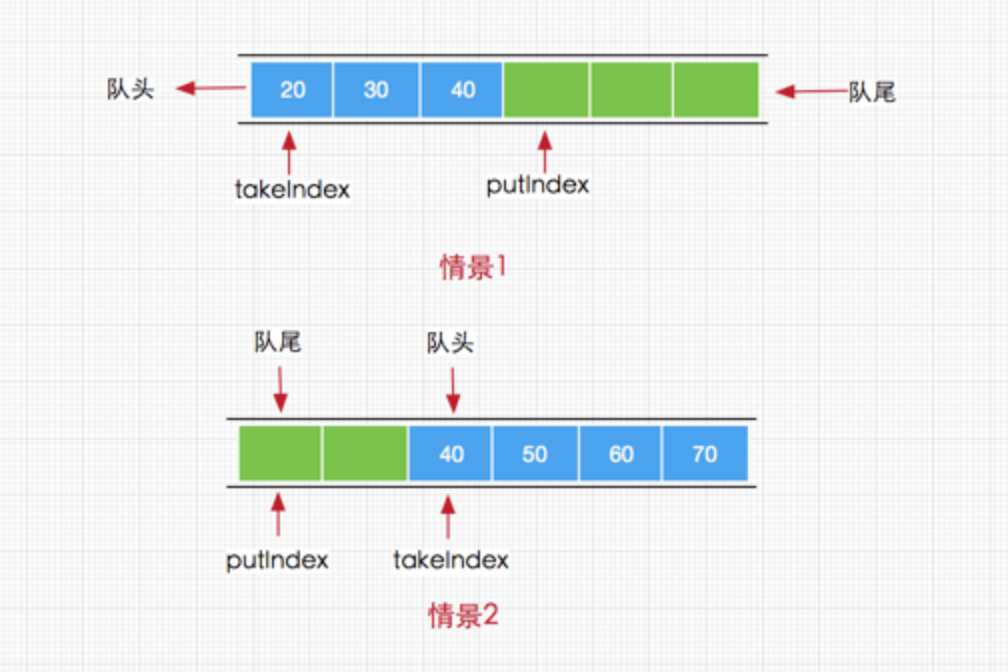
//入队操作
private void enqueue(E x) {
final Object[] items = this.items;
//通过putIndex索引对数组进行赋值
items[putIndex] = x;
//索引自增,如果已是最后一个位置,重新设置 putIndex = 0;
if (++putIndex == items.length)
putIndex = 0;
count++;
notEmpty.signal();
}接着看put方法:
put方法是一个阻塞的方法,如果队列元素已满,那么当前线程将会被notFull条件对象挂起加到等待队列中,直到队列有空档才会唤醒执行添加操作。但如果队列没有满,那么就直接调用enqueue(e)方法将元素加入到数组队列中。到此我们对三个添加方法即put,offer,add都分析完毕,其中offer,add在正常情况下都是无阻塞的添加,而put方法是阻塞添加。这就是阻塞队列的添加过程。说白了就是当队列满时通过条件对象Condtion来阻塞当前调用put方法的线程,直到线程又再次被唤醒执行。总得来说添加线程的执行存在以下两种情况,一是,队列已满,那么新到来的put线程将添加到notFull的条件队列中等待,二是,有移除线程执行移除操作,移除成功同时唤醒put线程,如下图所示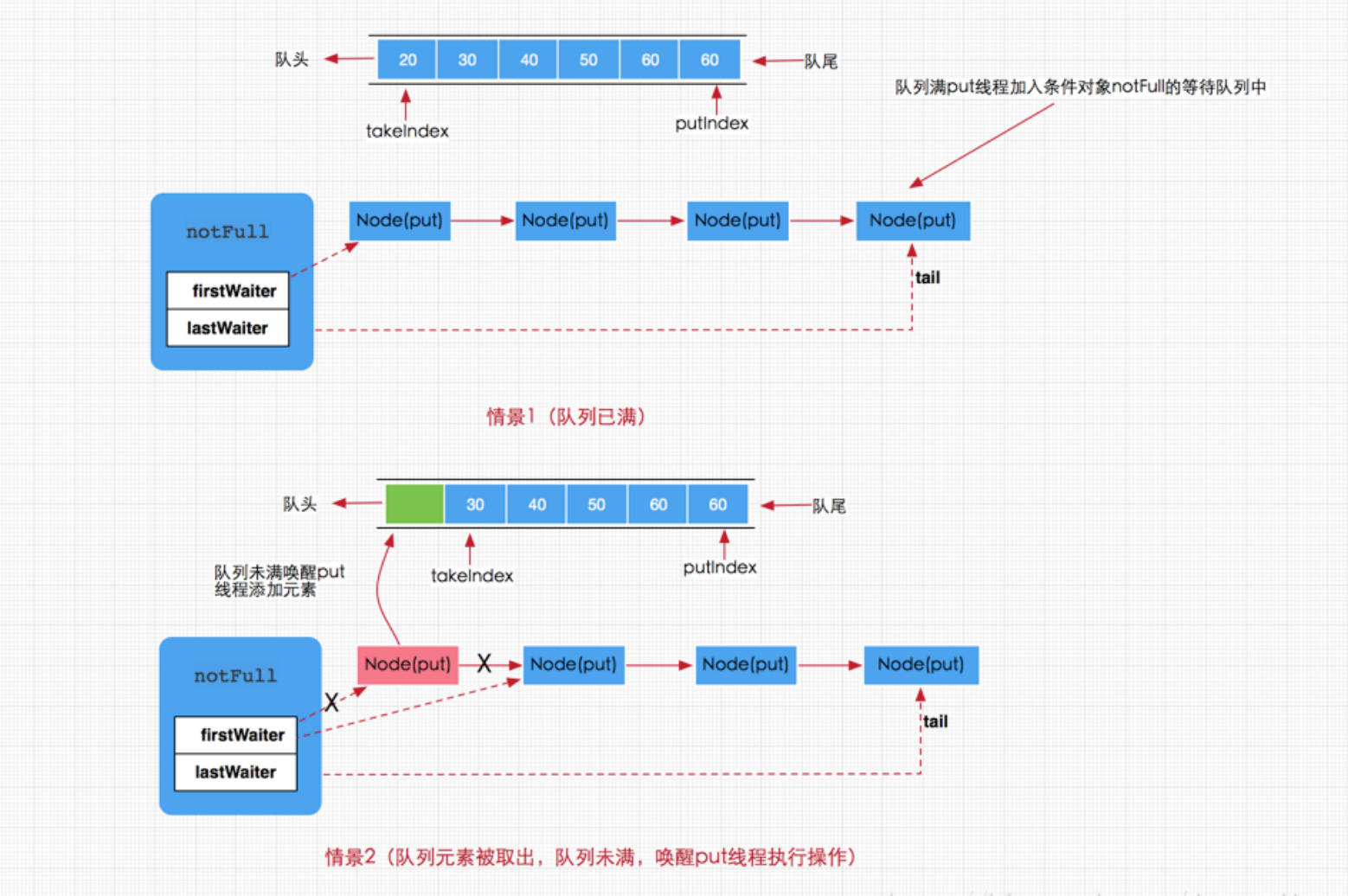
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
//当队列元素个数与数组长度相等时,无法添加元素
while (count == items.length)
//将当前调用线程挂起,添加到notFull条件队列中等待唤醒
notFull.await();
enqueue(e);
} finally {
lock.unlock();
}
}移除实现原理:
poll方法,该方法获取并移除此队列的头元素,若队列为空,则返回 null
public E poll() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
//判断队列是否为null,不为null执行dequeue()方法,否则返回null
return (count == 0) ? null : dequeue();
} finally {
lock.unlock();
}
}
//删除队列头元素并返回
private E dequeue() {
//拿到当前数组的数据
final Object[] items = this.items;
@SuppressWarnings("unchecked")
//获取要删除的对象
E x = (E) items[takeIndex];
将数组中takeIndex索引位置设置为null
items[takeIndex] = null;
//takeIndex索引加1并判断是否与数组长度相等,
//如果相等说明已到尽头,恢复为0
if (++takeIndex == items.length)
takeIndex = 0;
count--;//队列个数减1
if (itrs != null)
itrs.elementDequeued();//同时更新迭代器中的元素数据
//删除了元素说明队列有空位,唤醒notFull条件对象添加线程,执行添加操作
notFull.signal();
return x;
}接着看remove(Object o)方法
public boolean remove(Object o) {
if (o == null) return false;
//获取数组数据
final Object[] items = this.items;
final ReentrantLock lock = this.lock;
lock.lock();//加锁
try {
//如果此时队列不为null,这里是为了防止并发情况
if (count > 0) {
//获取下一个要添加元素时的索引
final int putIndex = this.putIndex;
//获取当前要被删除元素的索引
int i = takeIndex;
//执行循环查找要删除的元素
do {
//找到要删除的元素
if (o.equals(items[i])) {
removeAt(i);//执行删除
return true;//删除成功返回true
}
//当前删除索引执行加1后判断是否与数组长度相等
//若为true,说明索引已到数组尽头,将i设置为0
if (++i == items.length)
i = 0;
} while (i != putIndex);//继承查找
}
return false;
} finally {
lock.unlock();
}
}
//根据索引删除元素,实际上是把删除索引之后的元素往前移动一个位置
void removeAt(final int removeIndex) {
final Object[] items = this.items;
//先判断要删除的元素是否为当前队列头元素
if (removeIndex == takeIndex) {
//如果是直接删除
items[takeIndex] = null;
//当前队列头元素加1并判断是否与数组长度相等,若为true设置为0
if (++takeIndex == items.length)
takeIndex = 0;
count--;//队列元素减1
if (itrs != null)
itrs.elementDequeued();//更新迭代器中的数据
} else {
//如果要删除的元素不在队列头部,
//那么只需循环迭代把删除元素后面的所有元素往前移动一个位置
//获取下一个要被添加的元素的索引,作为循环判断结束条件
final int putIndex = this.putIndex;
//执行循环
for (int i = removeIndex;;) {
//获取要删除节点索引的下一个索引
int next = i + 1;
//判断是否已为数组长度,如果是从数组头部(索引为0)开始找
if (next == items.length)
next = 0;
//如果查找的索引不等于要添加元素的索引,说明元素可以再移动
if (next != putIndex) {
items[i] = items[next];//把后一个元素前移覆盖要删除的元
i = next;
} else {
//在removeIndex索引之后的元素都往前移动完毕后清空最后一个元素
items[i] = null;
this.putIndex = i;
break;//结束循环
}
}
count--;//队列元素减1
if (itrs != null)
itrs.removedAt(removeIndex);//更新迭代器数据
}
notFull.signal();//唤醒添加线程
}remove(Object o)方法的删除过程相对复杂些,因为该方法并不是直接从队列头部删除元素。首先线程先获取锁,再一步判断队列count>0,这点是保证并发情况下删除操作安全执行。接着获取下一个要添加源的索引putIndex以及takeIndex索引 ,作为后续循环的结束判断,因为只要putIndex与takeIndex不相等就说明队列没有结束。然后通过while循环找到要删除的元素索引,执行removeAt(i)方法删除,在removeAt(i)方法中实际上做了两件事,一是首先判断队列头部元素是否为删除元素,如果是直接删除,并唤醒添加线程,二是如果要删除的元素并不是队列头元素,那么执行循环操作,从要删除元素的索引removeIndex之后的元素都往前移动一个位置,那么要删除的元素就被removeIndex之后的元素替换,从而也就完成了删除操作。
接着看take()方法
take方法其实很简单,有就删除没有就阻塞,注意这个阻塞是可以中断的,如果队列没有数据那么就加入notEmpty条件队列等待(有数据就直接取走,方法结束),如果有新的put线程添加了数据,那么put操作将会唤醒take线程,执行take操作。图示如下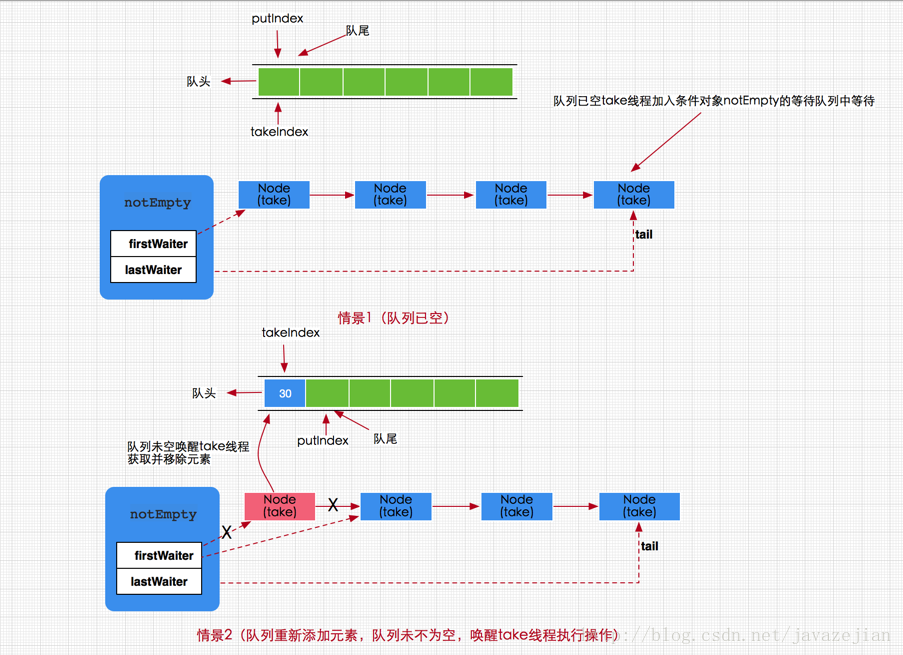
//从队列头部删除,队列没有元素就阻塞,可中断
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();//中断
try {
//如果队列没有元素
while (count == 0)
//执行阻塞操作
notEmpty.await();
return dequeue();//如果队列有元素执行删除操作
} finally {
lock.unlock();
}
}最后看看peek()方法,比较简单,直接返回当前队列的头元素但不删除任何元素。
public E peek() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
//直接返回当前队列的头元素,但不删除
return itemAt(takeIndex); // null when queue is empty
} finally {
lock.unlock();
}
}
final E itemAt(int i) {
return (E) items[i];
}(3)LinkedBlockingQueue
参数以及构造函数:
//节点类,用于存储数据
static class Node<E> {
E item;
Node<E> next;
Node(E x) { item = x; }
}
// 容量大小
private final int capacity;
// 元素个数,因为有2个锁,存在竞态条件,使用AtomicInteger
private final AtomicInteger count = new AtomicInteger(0);
// 头结点
private transient Node<E> head;
// 尾节点
private transient Node<E> last;
// 获取并移除元素时使用的锁,如take, poll, etc
private final ReentrantLock takeLock = new ReentrantLock();
// notEmpty条件对象,当队列没有数据时用于挂起执行删除的线程
private final Condition notEmpty = takeLock.newCondition();
// 添加元素时使用的锁如 put, offer, etc
private final ReentrantLock putLock = new ReentrantLock();
// notFull条件对象,当队列数据已满时用于挂起执行添加的线程
private final Condition notFull = putLock.newCondition();
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
public LinkedBlockingQueue(int capacity) {
if (capacity <= 0) throw new IllegalArgumentException();
this.capacity = capacity;
last = head = new Node<E>(null);
}
public LinkedBlockingQueue(Collection<? extends E> c) {
this(Integer.MAX_VALUE);
final ReentrantLock putLock = this.putLock;
putLock.lock(); // Never contended, but necessary for visibility
try {
int n = 0;
for (E e : c) {
if (e == null)
throw new NullPointerException();
if (n == capacity)
throw new IllegalStateException("Queue full");
enqueue(new Node<E>(e));
++n;
}
count.set(n);
} finally {
putLock.unlock();
}
}
| 4、线程池中的BlockingQueue |
首先看下构造函数
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler){...}TimeUnit:时间单位;BlockingQueue:等待的线程存放队列;keepAliveTime:非核心线程的闲置超时时间,超过这个时间就会被回收;RejectedExecutionHandler:线程池对拒绝任务的处理策略。
自定义线程池:这个构造方法对于队列是什么类型比较关键。
- 在使用有界队列时,若有新的任务需要执行,如果线程池实际线程数小于corePoolSize,则优先创建线程,
- 若大于corePoolSize,则会将任务加入队列,
- 若队列已满,则在总线程数不大于maximumPoolSize的前提下,创建新的线程,
- 若队列已经满了且线程数大于maximumPoolSize,则执行拒绝策略。或其他自定义方式。
接下来看下源码:
public void execute(Runnable command) {
if (command == null) //不能是空任务
throw new NullPointerException();
//如果还没有达到corePoolSize,则添加新线程来执行任务
if (poolSize >= corePoolSize || !addIfUnderCorePoolSize(command)) {
//如果已经达到corePoolSize,则不断的向工作队列中添加任务
if (runState == RUNNING && workQueue.offer(command)) {
//线程池已经没有任务
if (runState != RUNNING || poolSize == 0)
ensureQueuedTaskHandled(command);
}
//如果线程池不处于运行中或者工作队列已经满了,但是当前的线程数量还小于允许最大的maximumPoolSize线程数量,则继续创建线程来执行任务
else if (!addIfUnderMaximumPoolSize(command))
//已达到最大线程数量,任务队列也已经满了,则调用饱和策略执行处理器
reject(command); // is shutdown or saturated
}
}
private boolean addIfUnderCorePoolSize(Runnable firstTask) {
Thread t = null;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
//更改几个重要的控制字段需要加锁
try {
//池里线程数量小于核心线程数量,并且还需要是运行时
if (poolSize < corePoolSize && runState == RUNNING)
t = addThread(firstTask);
} finally {
mainLock.unlock();
}
if (t == null)
return false;
t.start(); //创建后,立即执行该任务
return true;
}
private Thread addThread(Runnable firstTask) {
Worker w = new Worker(firstTask);
Thread t = threadFactory.newThread(w); //委托线程工厂来创建,具有相同的组、优先级、都是非后台线程
if (t != null) {
w.thread = t;
workers.add(w); //加入到工作者线程集合里
int nt = ++poolSize;
if (nt > largestPoolSize)
largestPoolSize = nt;
}
return t;
}