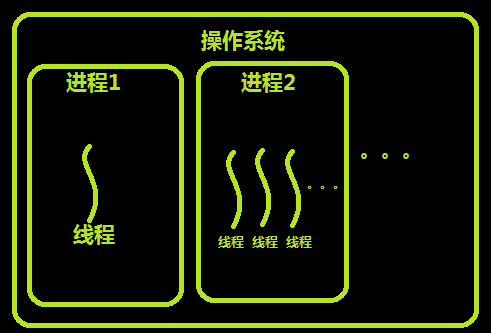
1、线程
能够独立运行的基本单位.
进程: 进程是资源分配的最小单位; 每一个进程中至少有一个线程.
线程: 线程是cpu调度的最小单位.
2、创建线程(类似于创建进程)


1 import time 2 from threading import Thread 3 4 def func1(m): 5 time.sleep(1) 6 print(">>>>>>") 7 print(m) 8 9 10 11 t = Thread(target=func1, args=(25,)) 12 t.start() 13 print("主线程结束")
1 import time 2 from threading import Thread 3 4 5 6 class MyThread(Thread): 7 def __init__(self,numb): 8 super(MyThread, self).__init__() 9 self.numb = numb 10 11 def run(self): 12 print("11111111111111111") 13 print(self.numb) 14 15 16 if __name__ == '__main__': 17 18 t = MyThread(500) 19 t.start() 20 print("主线程结束")
3、join()
1 import time 2 from threading import Thread 3 4 def func1(m): 5 print(m) 6 time.sleep(5) 7 print("子线程啦啦啦") 8 9 10 t = Thread(target=func1, args=(25,)) 11 t.start() 12 t.join() # 等子线程结束后再执行主线程 13 14 15 print("主线程啦啦啦啦啦啦")
4、线程提供的几个方法
current_thread().getName() # 获取当前线程的名字 current_thread().is_alive() # 判断该线程是否还存活 current_thread().isAlive() # 判断该线程是否还存活 threading.enumerate() # 当前存活的线程列表 threading.activeCount() # 当前存活的所有线程数量 threading.active_count() # 当前存活着的线程的所有数量
1 import time,threading 2 from threading import Thread,current_thread 3 4 5 6 def func1(): 7 time.sleep(1) 8 print(current_thread().is_alive()) # 判断该线程是否还存活 9 print(current_thread().isAlive()) 10 print(f"子线程名字:{current_thread().getName()}") 11 12 13 14 15 if __name__ == '__main__': 16 17 for i in range(10): 18 t = Thread(target=func1,name=f"子线程{i}号") 19 t.start() 20 print(threading.enumerate()) # 当前存活的线程列表 21 print(threading.activeCount()) # 当前存活的所有线程数量 22 print(f"主线程名字:{current_thread().getName()}" ) # 当前主线程的名字 23 time.sleep(3) 24 print(threading.active_count()) # 当前存活的线程的所有数量
5、进程和线程的效率对比
线程省去了系统给进程分配资源, 销毁进程等时间, 效率上明显提高.
1 import time 2 from multiprocessing import Process 3 from threading import Thread 4 5 6 def func(): 7 print("XXXXXXXXXX") 8 9 10 if __name__ == '__main__': 11 12 t_lst = [] 13 t_s_tm = time.time() 14 for i in range(100): 15 t = Thread(target=func,) 16 t_lst.append(t) 17 t.start() 18 [tt.join() for tt in t_lst] 19 t_e_tm = time.time() 20 t_dis_tm = t_e_tm - t_s_tm 21 print(f"多线程时间: {t_dis_tm}") # 多线程时间: 0.01200723648071289 22 23 p_lst = [] 24 p_s_tm = time.time() 25 for i in range(100): 26 p = Process(target=func, ) 27 p_lst.append(p) 28 p.start() 29 [pp.join() for pp in p_lst] 30 p_e_tm = time.time() 31 p_dis_tm = p_e_tm - p_s_tm 32 print(f"多进程时间: {p_dis_tm}") # 多进程时间: 1.9823119640350342
6、线程间数据安全
线程间的数据是共享的, 当大量线程去访问数据时也会造成数据混乱不安全的现象.
1 import time 2 from threading import Thread 3 4 numb = 100 5 def func(): 6 7 global numb 8 mid = numb 9 time.sleep(0.000001) 10 numb = mid - 1 11 12 13 14 15 if __name__ == '__main__': 16 17 t_lst = [] 18 for i in range(100): 19 t = Thread(target=func,) 20 t_lst.append(t) 21 t.start() 22 [tt.join() for tt in t_lst] 23 print(f"拿到的numb为: {numb}") # 93 或者其他
7、同步锁(类似进程)
1 import time 2 from threading import Thread,Lock 3 4 numb = 100 5 def func(lok): 6 7 global numb 8 lok.acquire() 9 mid = numb 10 time.sleep(0.000001) 11 numb = mid - 1 12 lok.release() 13 14 15 16 if __name__ == '__main__': 17 18 lok = Lock() 19 t_lst = [] 20 for i in range(100): 21 t = Thread(target=func,args=(lok,)) 22 t_lst.append(t) 23 t.start() 24 [tt.join() for tt in t_lst] 25 print(f"拿到的numb为: {numb}") # 0
8、死锁
1 import time 2 from threading import Thread,RLock,Lock 3 4 def func1(lock_a, lock_b): 5 lock_a.acquire() 6 time.sleep(0.5) 7 print("线程1拿到了A锁") 8 lock_b.acquire() 9 print("线程1拿到了B锁") 10 lock_b.release() 11 lock_a.release() 12 13 def func2(lock_a, lock_b): 14 lock_b.acquire() 15 print("线程2拿到了B锁") 16 lock_a.acquire() 17 print("线程2拿到了A锁") 18 lock_a.release() 19 lock_b.release() 20 21 22 23 if __name__ == '__main__': 24 25 lock_a = Lock() 26 lock_b = Lock() 27 t1 = Thread(target=func1,args=(lock_a, lock_b)) 28 t2 = Thread(target=func2,args=(lock_a, lock_b)) 29 t1.start() 30 t2.start() 31 32 33 # 结果 34 # func2拿到了B锁 35 # func1拿到了A锁 36 # 阻塞...... (因为线程2拿到B锁的同时, 线程1也拿到了A锁, 然后线程2要拿A锁, 但是线程1没有释放A锁, 37 # 同理线程2没有释放B锁, 两个线程就互相等, 一直阻塞着......)
9、递归锁
解决死锁的方法: ----> 递归锁
递归锁内部维持着一个计数器, 当计数器 == 0 时, 各线程开始抢夺递归锁, 当线程每抢着一个锁, 递归锁内部的计数器就 +1, 释放一个就 -1.
1 import time 2 from threading import Thread,RLock,Lock 3 4 def func1(lock_a, lock_b): 5 lock_a.acquire() 6 time.sleep(0.5) 7 print("线程1拿到了A锁") 8 lock_b.acquire() 9 print("线程1拿到了B锁") 10 lock_b.release() 11 lock_a.release() 12 13 def func2(lock_a, lock_b): 14 lock_b.acquire() 15 print("线程2拿到了B锁") 16 lock_a.acquire() 17 print("线程2拿到了A锁") 18 lock_a.release() 19 lock_b.release() 20 21 22 23 if __name__ == '__main__': 24 25 lock_a = lock_b = Lock() 26 t1 = Thread(target=func1,args=(lock_a, lock_b)) 27 t2 = Thread(target=func2,args=(lock_a, lock_b)) 28 t1.start() 29 t2.start() 30 31 """ 32 注意: 33 34 lock_a, lock_b = RLock() 表示lock_a, lock_b使用的是同一把递归锁 35 lock_a = RLock(), loca_b = Rlock() 表示lock_a使用一把递归锁,lock_b使用另一把递归锁,两个递归锁不一样, 相当于死锁 36 lock_a, lock_b = Lock() 表示lock_a, lock_b 使用同一把普通锁, 锁本身还没有释放, 肯定获取不到的 37 38 """
10、守护线程
守护线程随主线程的结束而结束. 主线程要等所有非守护线程代码统统运行完毕后, 主线程才运行完毕.
什么叫运行完毕? (结束和运行完毕是两码事)
进程: 对于进程来说, 运行完毕指的是主进程代码运行完毕;
线程: 对于线程来说, 运行完毕指得是主线程等待该进程内所有非守护线程代码统统运行完毕后, 主线程才运行完毕.
守护进程: 主进程在其代码结束后就已经算运行完毕了(守护进程在此时就被回收),然后主进程会一直等非守护的子进程都运行完毕后回收子进程的资源(否则会产生僵尸进程),才会结束.
守护线程: 主线程在其他非守护线程运行完毕后才算运行完毕(守护线程在此时就被回收)。因为主线程的结束意味着进程的结束,进程整体的资源都将被回收,而进程必须保证非守护线程都运行完毕后才能结束。
1 import time 2 from threading import Thread 3 4 5 def func1(): 6 time.sleep(3) 7 print("子线程1结束了") 8 9 def func2(): 10 time.sleep(2) 11 print("子线程2结束了") 12 13 14 if __name__ == '__main__': 15 t1 = Thread(target=func1,) 16 t2 = Thread(target=func2,) 17 18 t1.daemon = True 19 t2.daemon = True 20 21 t1.start() 22 t2.start() 23 24 25 26 print("主线程代码结束了")
1 import time 2 from multiprocessing import Process 3 4 5 def func1(): 6 time.sleep(3) 7 print("子进程1结束了") 8 9 def func2(): 10 time.sleep(2) 11 print("子进程2结束了") 12 13 14 if __name__ == '__main__': 15 p1 = Process(target=func1,) 16 p2 = Process(target=func2,) 17 18 p1.daemon = True 19 p2.daemon = True 20 21 p1.start() 22 p2.start() 23 24 25 26 print("主进程代码结束了")
11, 信号量, 事件
参考进程.
12、线程队列
和进程的方法一样, 不过种类有3种.
Queue: 先进先出;
LifoQueue: 先进后出, 后进先出;
PriorityQueue: 可以指定优先级的队列.
1 import queue 2 3 """""" 4 # 先进先出 5 q = queue.Queue(3) 6 q.put(111) 7 q.put(222) 8 q.put(333) 9 print("当前队列里的元素数量>>>>>>",q.qsize()) 10 try: 11 q.put_nowait(444) # queue.Full 12 except Exception: 13 print("队列满了") 14 15 print(q.get()) 16 print(q.get()) 17 print(q.get()) 18 try: 19 q.get_nowait() # _queue.Empty 20 except: 21 print("队列空了") 22 23 24 25 # 先进后出 26 q = queue.LifoQueue(3) 27 q.put(111) 28 q.put(222) 29 q.put_nowait(444) 30 print(q.get()) 31 print(q.get()) 32 print(q.get()) 33 # 方法和先进先出的队列一样 34 35 36 37 38 # 指定优先级顺序的队列 39 # put()里面放元组, 第一个参数是优先级顺序, 越小优先级越高(包括负数在内), get()越靠前. 40 41 q = queue.PriorityQueue(5) 42 q.put((-2, -222)) 43 q.put((0, 101)) 44 q.put((1, 111)) 45 q.put((2, 222)) 46 q.put((3, 333)) 47 48 print(q.get()) # (-2, -222) 49 print(q.get()) # (0, 101) 50 print(q.get()) # (1, 111) 51 print(q.get()) # (2, 222) 52 print(q.get()) # (3, 333)
13、线程池
虽然说线程的开支要比进程小得多, 但总归还是要消耗资源的, 所有就有了线程池.
线程池和进程池提供异步调用, 减少资源的开支.
(在 from current.futures import ThreadPoolExecutor, ProcessPoolExecutor的模块中, 线程池和进程池中的 map() 方法是没有 close() 和 join() 方法的, 而且map机制中不自带 shutdown() 方法, 得自己手写 shutdown() 方法, 而且在该模块下的进程池中是没有 apply() 和 apply_async()方法的)
1 import time 2 from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor 3 4 """submit() 和 shutdown() 是进程池和线程池所共有的方法""" 5 6 7 def func(i): 8 time.sleep(0.5) 9 return i ** 2 10 11 12 if __name__ == '__main__': 13 14 """ 15 # 线程池 16 t_p_lst = [] 17 t_p = ThreadPoolExecutor(4) 18 for i in range(10): 19 ret = t_p.submit(func,i) # 提交一个执行函数, 并返回一个结果对象, 参数i 可以是任意的 20 # print(ret.result()) # 和进程的 .get()方法一样,拿任务的执行结果, 取不到就一直阻塞着,一个一个取的话就是串行状态 21 t_p_lst.append(ret) 22 23 t_p.shutdown() # 作用效果和 .close()阻止新任务进来 + .join(), 等待所有的线程运行完毕. 24 for t_p in t_p_lst: 25 print(t_p.result()) 26 27 28 # map() 29 ret = t_p.map(func,range(10)) # 线程池的map是没有close()和join()方法的 30 # print(ret) # <generator object Executor.map.......是一个生成器对象 31 for i in ret: 32 print(i) 33 """ 34 35 """ 36 # 进程池 37 p_p_lst = [] 38 p_p = ProcessPoolExecutor(4) 39 for i in range(10): 40 ret = p_p.submit(func,i) 41 # print(ret.result()) 42 p_p_lst.append(ret) 43 p_p.shutdown() 44 for p_p in p_p_lst: 45 print(p_p.result()) 46 """
14、线程池的回调函数
1 import time 2 from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor 3 4 def func(i): 5 time.sleep(1) 6 return i ** 2 7 8 def call_back_func(ret): 9 print(ret.result()) 10 11 12 if __name__ == '__main__': 13 14 p_p = ProcessPoolExecutor(max_workers=4) 15 for i in range(10): 16 p_p.submit(func, i).add_done_callback(call_back_func) 17 18 19 # add_done_callback() 进程池的回调函数.
15、GIL全局解释器线程锁
在CPython中由于GIL全局解释器线程锁, 同一进程下开启的多线程, 同一时刻只能有一个线程运行.
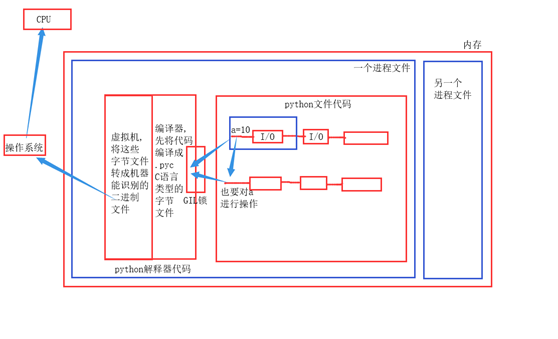
执行过程:
1, cPython解释器由两部分组成, 虚拟机和编译器;
2, cPython解释器代码先被加载到内存中, 然后.py文件这个进程中开启的多个线程, 同一时间只能有一个线程通过GIL锁,被编译器编译成.pyc文件(C语言能识别的字节码);
3, cpython中的虚拟机再将这些字节码转成机器能识别的二进制文件;
4, 操作系统将这些二进制文件调给CPU去计算.
有了GIL锁, 还要自定义的同步锁干嘛?
当第一个线程在运行时遇到 I/O 操作, 第二个线程就会通过GIL锁被执行, 如果两个线程操作的是同一个文件或数据, 就会造成数据混乱的现象, 用自定义的同步锁来保护数据安全.
有了GIL锁, 没有自定义的同步锁, 无法保证数据安全; 没有GIL锁, 只有同步锁也可以保证数据安全, 只不过后来cpython解释器的发展是建立在GIL锁的基础上的.