1. 客户端执行sql语句 (在此之前会先进行用户名密码的连接,会去进行mysql的校验,详情查看mysql运行流程)
2.sql语句会进入到命令分发器
2. sql语句在进行mysql服务器进行查询缓存,查询以sql语句作为记录,以语句作为key,结果作为value
假如当前的查询语句为“select count(*) from table_name” , 开启查询缓存后,回去查询当前这条语句是否存在,存在检查用户是否有权限访问内容(类似rbac操作),有权限返回结果(如果语句内有空格,匹配不上,会导致查询缓存失效)
3. 命令解析器,会对sql语句进行解析,生成一个解析树,判断你是什么类型的操作(查询优化器select ,表变更(增删改)dml,表维护ddl,复制模块rep,状态模块status)
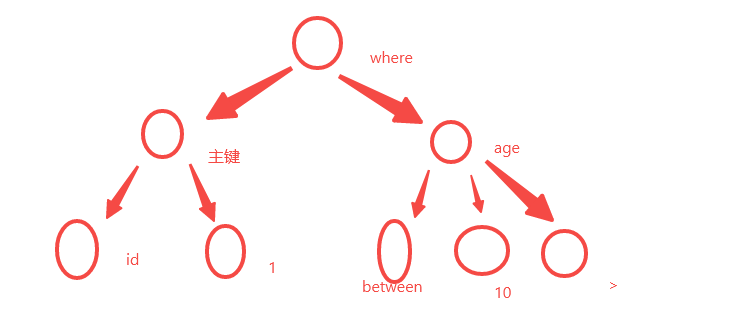
4. 假如你是一条“select count(*) from table_name where id=1 and age > 10” 这样的操作,查询优化器会将“where id=1 and age > 10”条件取出来,根据自己的规则算法匹配查询,存在一个扫描区,会一直对磁盘进行扫描,找到对应的磁盘页数据内容
5. 返回数据
sql优化,指的也就是对磁盘的i/o操作次数和优化器的执行时间,不是i/o的操作速度(充钱解决)
解析器:分为句法扫描器,与语法规则模块
句法扫描器 =》整个查询语句分为多个令牌(一些不可分隔的元素,列名)
“select count(*) from table_name where id=1 and age > 10”
如上面的sql, 句法解析器将每个字节流都会分解为一个令牌
select count ( * ) from table_name where id = 1 and age > 10
语法规则(sql.yacc.yy)然后根据这些令牌sql.lex.h -> 关键字->生成解析树
优化器:
1. 会选择合适的键,比如使用join的时候,会选择适合查找的键
2. 针对每个表进行全局扫描,如果数据量过大,速度会慢
3. 如果是join查询,选择表的连接顺序
4. 对于where进行重写 ,删除不必要的代码,减少不必要的计算量,尽可能的限制条件,方便查询有效率执行
(join)删除不需要连接的数据表
5. order group 确定是否可以使用到索引
(join)合并大的视图
6. 执行执行计划
个人理解