| 这个作业属于哪个课程 | 福大20春软工S班 |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(2/2) |
| 这个作业的目标 | 1.完成疫情统计项目 2.规范自己的代码风格 3.github学习与使用 4.PSP(个人软件开发流程)的学习使用 5.学习程序的测试和优化 |
| 作业正文 | 正文 |
| 其他参考文献 | 百度 CSDN博客 博客园上大佬们的教程 |
GitHub仓库及代码规范
构建之法中的PSP表格
- 阅读构建之法后,我结合作者邹欣老师的博客,思考着我们大学生和真正工程师在能力上的差距。CMU的专家们针对软件工程师也有一套模型:叫 Personal Software Process (PSP),从一个大学生和一个工作三年的工程师的PSP对比中,有几个明显的差异:
- 需求分析和测试方面,工程师用的时间远比大学生要多
- 具体编码上,工程师要比大学生少花三分之一的时间
- 经验老到的工程师,往往有着明确的计划,在开始前已经构建好了这个项目的基础,他们付诸实践的时候就更加高效快捷,结合自己的经历,在上学期间我写代码往往就是想到哪写到哪,并没有花太多时间在需求分析上,而之后的工作往往要有足够的分析才能更好地开展项目,所以这一方面我需要更加努力去提高自己。为此,我试着将这次项目的PSP表格制作出来。
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 40 |
| Estimate | 估计这个任务需要多少时间 | 20 | 10 |
| Development | 开发 | 910 | 790 |
| Analysis | 需求分析 (包括学习新技术) | 240 | 180 |
| Design Spec | 生成设计文档 | 30 | 20 |
| Design Review | 设计复审 | 20 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 40 |
| Design | 具体设计 | 60 | 80 |
| Coding | 具体编码 | 450 | 360 |
| Code Review | 代码复审 | 20 | 20 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 70 |
| Reporting | 报告 | 130 | 170 |
| Test Repor | 测试报告 | 20 | 30 |
| Size Measurement | 计算工作量 | 20 | 20 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 90 | 120 |
| 合计 | 1100 | 1000 |
解题思路
首先对题目进行分析,得知是通过用户的cmd命令来统计日志文件中相应的数据,然后输出到文件中。那么不难发现,这个题目的重点在于把日志文件读出来,并在程序内进行计算,从而得出最终结果并输出,本次项目运用JAVA开发:
对于日志文件,可以通过IO流的Scanner进行读取,将读取的内容存放在字符串动态数组数组里。
Scanner sc = new Scanner(fileArray[fileCount],"UTF-8");
while(sc.hasNext())
{
String str = sc.next();
If (str.equals("//"))
break;
else fileContent.add(str);
}
将文件内容读取完毕后,我们就要开始计算分析数据,将各省的各种数据统计完成以后,就可以放在Hash表中,key例如:福建感染患者、福建疑似患者,value则是对应的 人数,这样统计的数据就都储存起来了
| key | value |
|---|---|
| 福建感染患者 | 10 |
| 湖北死亡 | 21 |
| 北京疑似患者 | 47 |
储存完数据,就是要根据用户的命令要求进行输出。用户指定的时间、日志路径、输出路径、输出类型、输出省份都用字符串存储起来,然后在输出的时候依次检查,即可按照要求从Hash表中调出数据并输出
public static String fileDirect; //保存所有日志文件文件目录的路径
public static String outputFilepath; //保存输出文件的路径
public static String dateTime; //保存-date的参数
public static String typePeople[]; //保存要输出的类型
public static String province[]; //保存要输出的省份
public static ArrayList<String> fileContent; //保存从文件中读取的内容
public static Map<String , String> statistic; //保存统计的结果
public static Map<String, Object> sortMap; //用于保存经过排序的统计结果
public static Map<String , String> typeMap; //用于保存sp ip对应的类型关系
本次项目的核心问题是,如何统计好日志文件中的数据并整合到Hash表中?在前面我们会按顺序逐个打开日志文件,并把日志文件中的内容读取到字符串数组中,这样就会是个形如 String str[] = {"福建","新增","感染患者","1人","福建","治愈","3人","湖北","感染患者","流入","福建","4人","湖北","死亡","1人"}的字符串
假设这是一个日志文件的全部数据,那么不难发现,这些词都有着关键动词新增、流入、死亡、排除、确诊感染、治愈,那么只要在遍历的时候检查,例如目前的游标位于0,对应的是福建,检查游标0 + 1是否是新增?
如果是,那就知道这句要算的是新增方面的数据!并且游标0代表的是省份,游标0 + 2代表的是类型,游标0 + 3代表人数,这样数据都知道了,只要计算完放入哈希表即可。如果不是,那么久检查游标 + 1是否是死亡或者治愈,或者游标 + 2是不是流入,以此类推,如果都不是那就跳过,继续遍历,这样遍历到结尾就会将所有的语句对应的情况都算好放入Hash表
前面提到的遍历检索,能够判别这句话涉及到哪些省,如果在遍历的时候判别出这个省并没有数据存在Hash表,要初始化,把这个省的四种类型数据都初始化,并都置为 0,例如有一句北京 新增 患者 3人,如果哈希表没有北京的数据,这样就会产生哈希表,产生过后再对这句语句进行数据处理,给北京感染患者的value+3
最后是用户命令的处理,由于用户命令会储存在args[]函数里,我们把她读取进来,用以下代码即可进行相应的操作
public static void judgeType (String str[])
{
if(str[cmdCount].equalsIgnoreCase("-log"))
{
readLog(str);
}
else if(str[cmdCount].equalsIgnoreCase("-out"))
{
readOutputPath(str);
}
else if(str[cmdCount].equalsIgnoreCase("-date"))
{
readDateTime(str);
}
else if(str[cmdCount].equalsIgnoreCase("-type"))
{
readType(str);
}
else if(str[cmdCount].equalsIgnoreCase("-type"))
{
readType(str);
}
else if(str[cmdCount].equalsIgnoreCase("-province"))
{
readProvince(str);
}
}
设计实现过程
- 项目整体流程:
- 代码组织
- 主要函数流程

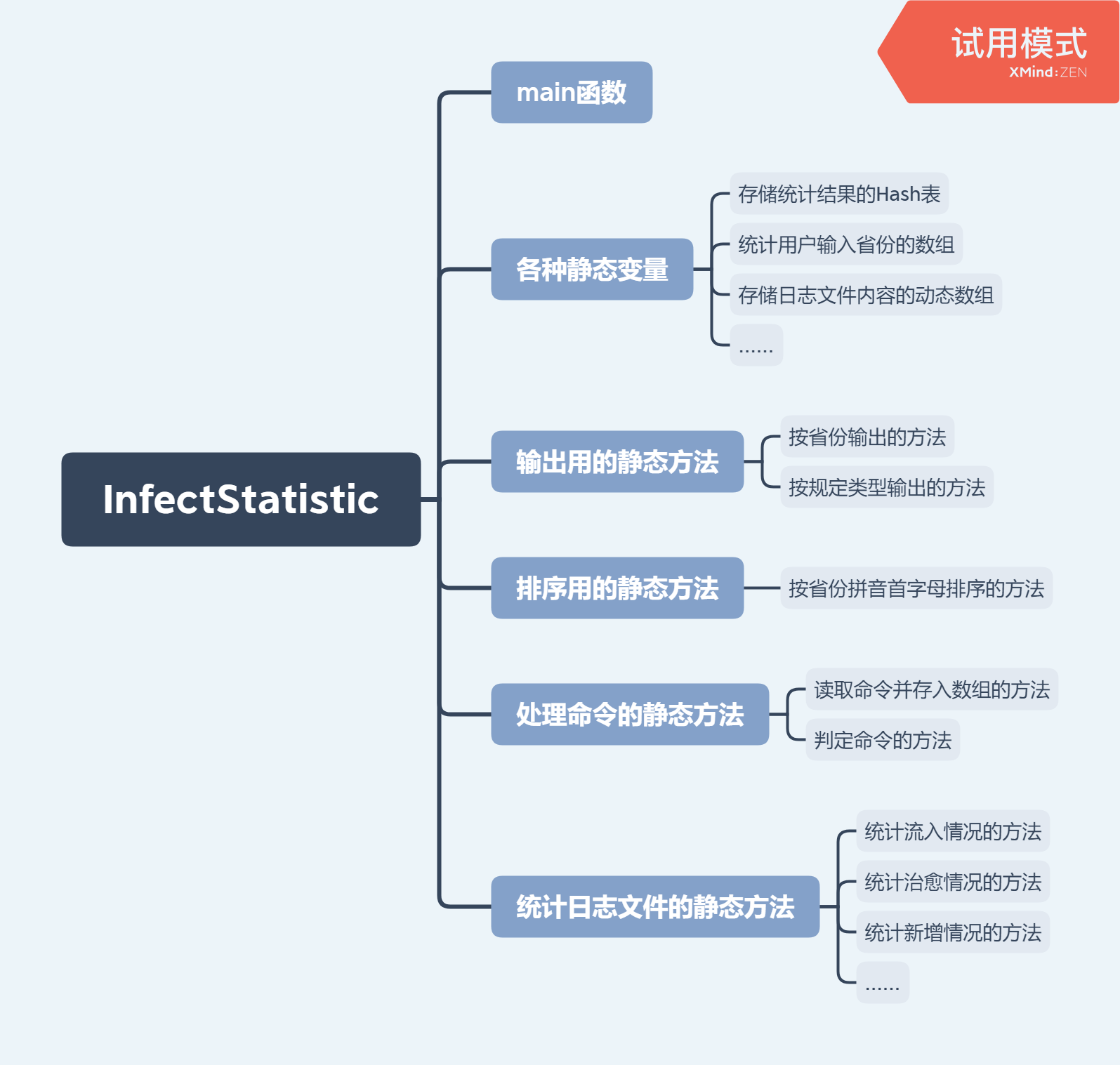
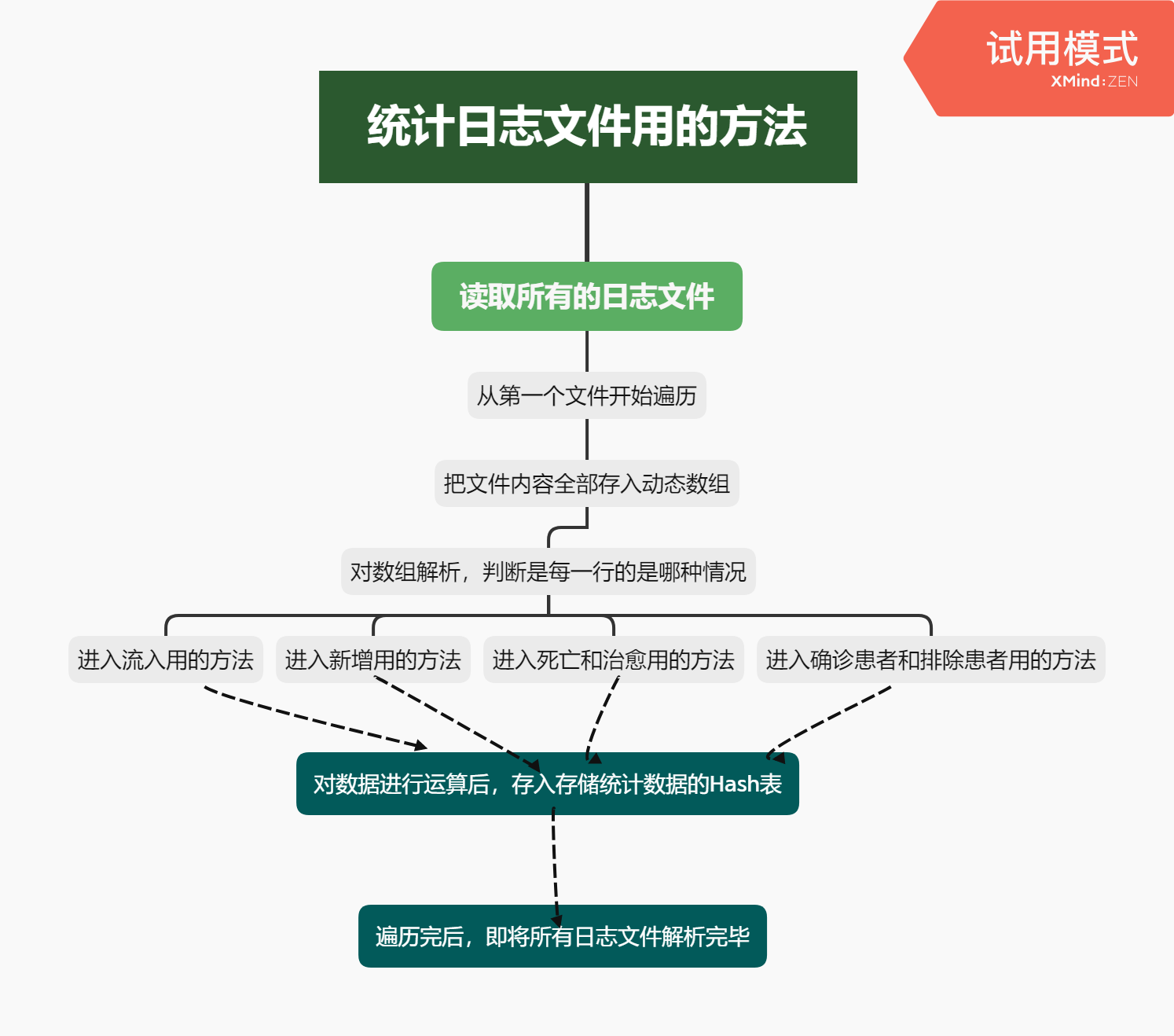
代码说明
最核心的代码:统计方法代码
public static void flowState(int count)
{
String provin2 = fileContent.get(count); //获取有患者流出的省份
String provin1 = fileContent.get(count + 3); //获取有患者流入的省份
String type = fileContent.get(count + 1); //感染患者或者疑似患者
String str = fileContent.get(count + 4);
str = str.substring(0 , str.length() - 1); //截取人数
if(!statistic.containsKey(provin1 + type)) //检查哈希表中是否已经存在该省份的数据了
{
initStatistic(provin1);
}
if(!statistic.containsKey(provin2 + type))
{
initStatistic(provin2);
}
int sum1 = Integer.parseInt(str) + Integer.parseInt(statistic.get(provin1 + type)); //统计有患者流入的省份
int sum2 = Integer.parseInt(statistic.get(provin2 + type)) - Integer.parseInt(str); //统计有患者流出的省份
statistic.put(provin1 + type , String.valueOf(sum1));
statistic.put(provin2 + type , String.valueOf(sum2));
}
上述代码是统计方法的其中之一,是情况为流入的方法,fileContent是一个动态数组,存储着文件的内容,而count则是用来遍历文件内容的游标,现在我们已经判定了这句话是流入情况,所以创建变量将流入省,流出省,人数,类型全部存储起来,然后开始检查统计总数据用的哈希表statisttc是否存在该省,不存在就要初始化,将这个省的四项数据全部置0,然后再进入算法。
接着就是把有患者流入的省份加上人数,把有患者流出的省份减去人生,再存储到哈希表对应的位置,即解析完这句话并存储成功
其他情况的统计方法与之类似
命令行代码
public static void readProvince (String str[])
{
if(cmdCount == str.length - 1 || str[cmdCount+1].substring(0,1).equals("-"))
{
return;
}
else
{
province = new String[31];
cmdCount++;
provinceCount = 0;
for( ; cmdCount < str.length ; cmdCount++)
{
province[provinceCount++] = str[cmdCount];
if(cmdCount == str.length - 1 || str[cmdCount+1].substring(0,1).equals("-")) break;
}
}
}
上述代码是解析-province指令的代码,第一if解析如果这是最后一个参数了,就说明没有参数值了,如果游标下移一位后的参数是-开头的,也说明没有参数值,那么直接返回即可,否则就初始化省份数组,游标下移,然后开始循环,直到判断出游标移到了边界或者下一个是开头为-的新命令时结束,每个循环都把用户输入的一个省加入到provin数组中
输出代码
public static void outputByType(String province) throws IOException
{
if(typePeople == null)
{
fileWritter.write(province + " " + "感染患者" + statistic.get(province + "感染患者") + "人" + " "
+ "疑似患者" + statistic.get(province + "疑似患者") + "人" + " "
+ "治愈" + statistic.get(province + "治愈") + "人" + " "
+ "死亡" + statistic.get(province + "死亡") + "人");
fileWritter.flush();
}
else
{
fileWritter.write(province + " ");
for(int i = 0; i < typeCount ; i++)
{
String type = typeMap.get(typePeople[i]);
fileWritter.write(type + statistic.get(province + type) + "人");
if(i != typeCount - 1) fileWritter.write(" "); //避免在最后多出一个空格
fileWritter.flush();
}
}
}
上述代码输出一个省份的信息,传入的参数province是省份,其中typePeople数组为空,说明用户没指定要输出什么类型,全部输出即可,如果非空,那么就按照数组的内容进行输出,将ip、sp转换为中文也是用Hash表完成,这样就能把对应类型的人都输出了,typeMap表如下
| key | value |
|---|---|
| sp | 疑似患者 |
| ip | 感染患者 |
| cure | 治愈 |
| dead | 死亡 |
单元测试
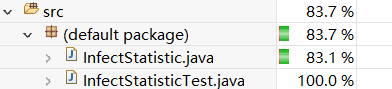
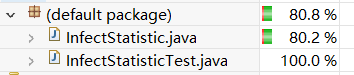
- 第一次测试 全部参数都使用,并且带有参数值,覆盖率85.4%
- 第二次测试 全部参数都使用,-date不带参数值,覆盖率85.0%
- 第三次测试 全部参数都使用,-date 和-province 都不带参数值,覆盖率83.1%
- 第四次测试 全部参数都使用,-date -province -type都不带参数值,覆盖率80.1%
- 第五次测试 只有基础命令,没有参数,覆盖率74.4%
- 第六次测试 参数使用-province,并且存在日志没涉及的省份黑龙江,覆盖率80.2%
- 第七次测试 参数使用-province,-type,-date没参数值,覆盖率85.0%
- 第八次测试 参数使用-province,-date,-type没参数值,覆盖率85.0%
- 第九次测试 参数使用-date,-type,-province没参数值,覆盖率83.5%
- 第十次测试 参数-date的超出日期,介于日志文件日期间,小于日志文件日期的测试
超出最迟日期
介于日期之间(因为22到27之间没数据,所以24的情况和22一样,输出24的结果)
早于最早日期






























性能测试
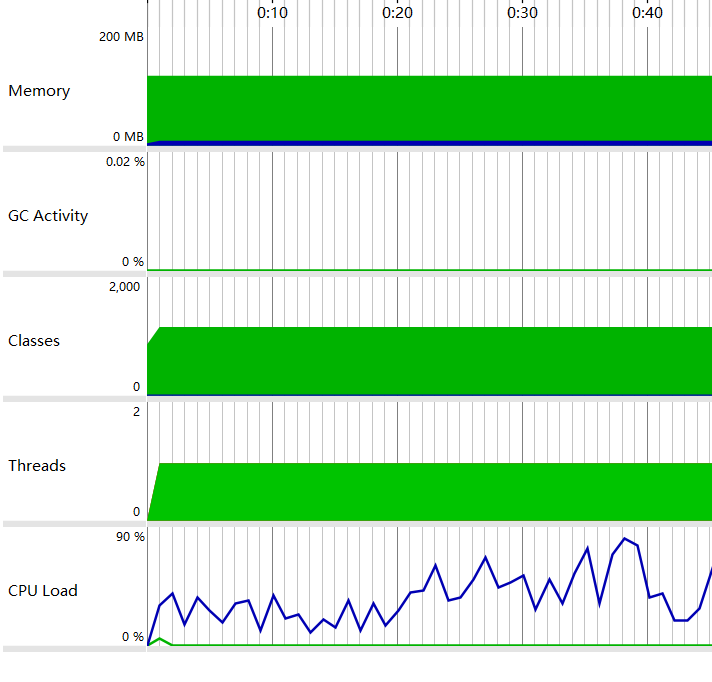
- 总览
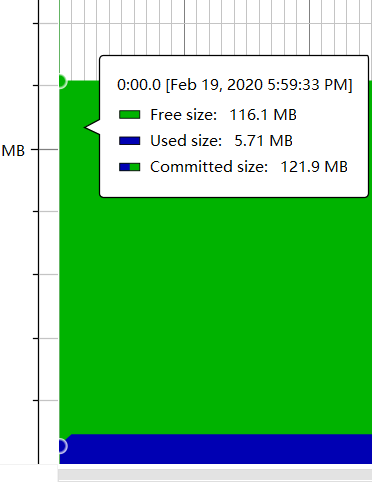
- 内存变化
- JAVA使用情况
- 优化方面,试着整合函数,试着优化后发现改变效果均不明显,可能需要用更好的数据类型才能让内存占用更少,然而这样我很多算法都要重写,甚至算不上优化了,因此我深感自己对优化方面能力的不足,希望在今后能多加学习优化的知识


心路历程和收获
- 这次项目开发,给我的感觉是茫然->苦恼->明朗->上头这么一个过程
- 起初,面对着作业那长长的要求,和一堆新食物,如GitHub,单元测试等等,让我非常的茫然,有种无从下手的感觉
- 之后我就为了完成作业而苦恼,一开始甚至想一蹴而就,但是,这么多的内容,也给了我们足够长的时间,我觉得需要计划好学习时间,合理学习新知识
- 计划好之后,我的学习逐渐明朗,能够通过教程去慢慢学习,也通过阅读知道了开发软件的构建步骤,如需求分析。项目开发稳步进行
- 计划有了,需求分析之类的也完成了,写代码给我的感觉就是上头了,越写越有劲,最终完成之后,也非常有成就感
- 收获
- GitHub的使用及作用
- 构建之法的构架知识还有PSP表格
- 能够做需求分析,合理计划开发程序
- 单元测试的相关知识
- JAVA程序的有关学习更加深入
相关GitHub仓库
- Modern Java - A Guide to Java 8
https://github.com/winterbe/java8-tutorial
- 值得一看的Java8指南、教程
- JAVA面试
https://github.com/kdn251/interviews
- Java面试题和答案(英文)
- Hutool
https://github.com/looly/hutool
- Hutool是一个小而全的Java工具类库,通过静态方法封装,降低相关API的学习成本,提高工作效率,使Java拥有函数式语言般的优雅,让Java语言也可以“甜甜的”。
- Swiss Java Knife (SJK)
https://github.com/aragozin/jvm-tools
- JVM诊断和分析工具
- MapDB: database engine
https://github.com/jankotek/mapdb
- 一个快速且易于使用的嵌入式Java数据库引擎