按自己的意愿生活, 而且是::: 要敢于按自己的意志去活! 那是一种胆量和勇气!!
-
shell中的结构, 只有选择(实际上if条件也是一种选择结构)和循环, 都是用关键字来替代 大括号的。 如:
if 用 then ...fi来表示 代码段。 case 变量 in 1)....;; 2)....;; *)....;;
for 用 do... done. while也是用 do...done 来 表示代码段的。 -
shell 中的关键字比如do, done, then等, 都是单独一行的。遵守普通规则, 不要 放在一行什么的
-
for循环
shell中的for循环 跟其他任何编程语言中的for都不一样, 其他for循环都是一个连续范围, 如: 1《i《10等等。
shell中的for,后面是一个 枚举的, 分散的, 离散的 值(数字, 字符串)的列表, 因为他是用的 in 来引导取值列表。
后面的列表中的值, 可以有三种种类, 一是数字, 二是字符串, 三是文件。 数字用空格分开, 不是用逗号分隔的, 也不能用引号括起来:
而且循环变量的值, 就是后面列表中的一个一个的依次的取值, 在代码段中
1. for loop in 1 2 3 4 (数字列表, 直接用空格分隔)
echo $loop
2. for loop in 'this is a demo'
for循环有点像php等编程语言中的foreach. for后面的单词 就是循环体中将用到的循环变量: for i in ... then echo $i... fi
shell中的大括号
-
当shell中的大括号 来括 变量的时候, 一定要将大括号只括 "变量名", 不要括 $ 符合, 并且大括号在shell中就是一个普通字符,没有 转义的. 这个跟tp中的模板变量的输出不一样
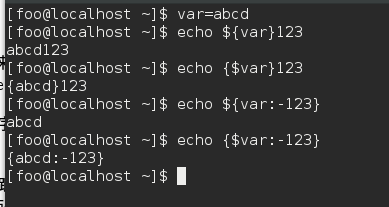
shell字符串中的冒号
echo ${var:Cstring}冒号表示替换. 将var用string来替换. C 表示条件condition. C 是必须的, 如果没有C将 忽略冒号后面的string的内容:echo ${var:string}将输出 var变量的值/(由此看来, md中的图片虽然另起一行, 但是并不影响后面的序号排序)

- C有+, -, =, ? 加号表示var为正, 即var不为空 的时候替换, -表示负, 即var为空的时候替换, =表示var为空的时候替换,而且var本身要被赋值为string. 前面的加号减号中, var本身的值都不会变
后来增加的内容
单括号和双括号都可以跟$结合使用, 前者括号中要跟命令, 表示命令执行结果, 而双括号是跟计算表达式.
x=y 在不同位置的含义?
当x=y单独在一个行, 表示一个命令的时候, 它表示是跟x变量赋值. 可以给"字符串", 也可以给"数字字符串"都是可以的, 默认的都是作为字符串看待的
但是当 x=y 在if条件判断中时, if [ x=y ], 此时的x=y是 表示 字符串相等判断, 而不是赋值了. 但是即使是逻辑判断, 等号两边仍然不能有空格! 如果有空格, 它就表示一个命令.
**等号 = , 要表示赋值 和 条件判断 的时候, 就一定要去掉等号两边的空格. 否则就表示一个命令, 而不是赋值和判断了 **

双中括号, 仅仅只是中括号的一个扩展, 表示两个方面的东西:
- 是可以直接使用关系运算符和逻辑运算符, 可以直接使用 && ||, > < >= <= == !=, 而不会出错. 比如: 用单括号:
if [ $a>$b ] && [ $a>$c ]或者if [ $a>$b -a $a>$c ]就可以直接时使用if [[ $a>$b && $a>$c ]] - 是在判断字符串相等的可以使用通配符
shell中的四则运算只能借助于let expr命令, 和 两个扩展 (( )) 和$[]
let命令, 是bash中用于计算 四则运算的命令, 首先, 它可以一次性的计算多个表达式的值, 而返回最后一个表达式的值, 而没有被赋值保存的表达式值将被丢弃; 其次, 如果表达式中有空格 等特殊符号 要用双引号括起来.

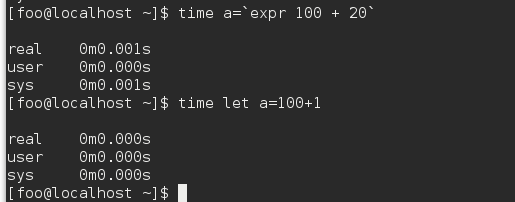
使用time来测试命令所使用的时间
可以知道 同样是赋值, let命令, 比expr的命令更快, 因为let命令, 只有一次操作, 而expr命令有两次操作, 首先要计算 , 然后再是赋值.
$* $@ "$*" "$@" 的区别
$*, 是表示所有的参数. 而且这些参数是分开的,独立的
"$*", 因为加了双引号, 就表示是一个, 只有一个 字符串, 是一个整体, 是由"$1,$2, ..."等组成的一个字符串.
$@ 和 "$@" 相等 , 都表示分割的, 多个独立的参数 . 因为这里的@ 不像, 星号有通配符, 全部的意思. 而@没有全部的意思*.
通过$* 和 "$*", 就给用户 提供了一种机会, 你即可以处理形参中的各个独立的参数, 也可以把形参当作一个整体的字符串来对待.


关于$0参数的理解? shell和awk中的 $0 的区别.
并不总是当前脚本的名称, 这种说法不是很准确.
应该说是: $0表示当前命令行的 第一个单词, 比如:
source foo.sh 中的echo $0, 则会输出 "bash"
如果是 ./foo.sh 脚本中的echo $0, 则会输出 "./foo.sh" , 就是这个 "第一个单词"
但是, 在shell脚本中的$0 和 awk脚本中的$0不一样"
awk中的$0 是一行, 一条记录, 当前行, 当前记录.
所以 awk -F: '{print $0;}' /etc/passwd | head -n5 则会输出前面5行的内容.

关于2>&1
在任何命令的后面都可以使用 重定向和管道 命令
要注意几个代表 "标准设备"的 文件描述符: 0, 1, 2, 也就是 深入理解"设备也是文件"的概念.
0: 标准输入设备"文件", 即键盘,
1: 标准输出设备"文件", 即屏幕
2: 标准错误输出设备"文件", 默认的也是屏幕
> 表示重定向, 其中, > 前面的表示来源设备, 可以不加&, 而 > 后面的表示输出设备, "重定向"设备, 但是, 要在数字前面加上&, 这个& 表示"文件描述符"
在/etc目录下, 只能放root用户的文件和东西.

字符串和数字的比较, 在于你采用什么比较操作符号. 作为数字来比较, 就用 -eq -gt等符号或者用 (( ))双括号. 作为字符串来比较, 就用= , ==, !=, -z -n等符号.
===============
2>&1, 为什么要在1前面加上&?
首先, 加&表示文件描述符.表示1这个设备作为一个文件看待, 就是"device is also file", 表示标准输出. 反之,如果不加&, 成为2>1, 这时候, 1就是一个文件看待, 就表示标准错误重定向到当前目录下的一个regular 文件1中.
2>&1, 为什么要放到最后?
这是由于不同的执行顺序会导致不同的结果,
如果是 比如: ls > file 2>&1, 则先执行ls, 结果重定向文件file中, 此时标准输出就被重新定义为file了. 然后, 再执行重定向命令 2>&1, 则&1就变为 file了,所以, 到最后, 命令的输出和错误都将输出到 file中.
但是, 如果 ls 2>&1 >file 则执行的顺序是: 首先ls命令的 错误2将输出到 &1,即标准输出设备"屏幕"上. 然后执行>file, 这时 并没有改变命令的输出设备, 将产生一个stdout的拷贝, 将命令ls 的正常输出内容, 输出到文件file中.
ls >&file 或者, ls &>file 都表示将命令的标准输出和标准错误都重定向到regular文件file中. >&file 就等于 &>file , 都等于 ">file 2>&1" 这里>和& 要连起来使用, 分开则没有意义.

