SparkStreaming
Spark Streaming类似于Apache Storm,用于流式数据的处理。Spark Streaming有高吞吐量和容错能力强等特点。Spark Streaming支持的数据源有很多,例如:Kafka、Flume、Twitter、ZeroMQ和简单的TCP套接字等等。数据输入后可以用Spark的高度抽象操作如:map、reduce、join、window等进行运算。而结果也能保存在很多地方,如HDFS,数据库等。

特性
1、易用性 可以像编写离线批处理一样去开发流式的处理程序,并且可以使用java/scala/Python语言进行代码开发 2、容错性 SparkStreaming在没有额外代码和配置的情况下可以恢复丢失的工作。 3、可以融合到spark生态系统 sparkStreaming流式处理可以跟批处理和交互式查询相结合
与storm对比
storm是来一条数据处理一条数据,SparkStreaming是以某一时间间隔批量处理数据。
SparkStreaming原理
Spark Streaming 是基于spark的流式批处理引擎,其基本原理是把输入数据以某一时间间隔批量的处理,当批处理间隔缩短到秒级时,便可以用于处理实时数据流。
计算流程
Spark Streaming是将流式计算分解成一系列短小的批处理作业。这里的批处理引擎是Spark Core,也就是把Spark Streaming的输入数据按照batch size(如1秒)分成一段一段的数据(Discretized Stream),
每一段数据都转换成Spark中的RDD(Resilient Distributed Dataset),然后将Spark Streaming中对DStream的Transformation操作变为针对Spark中对RDD的Transformation操作,
将RDD经过操作变成中间结果保存在内存中。整个流式计算根据业务的需求可以对中间的结果进行缓存或者存储到外部设备。下图显示了Spark Streaming的整个流程。
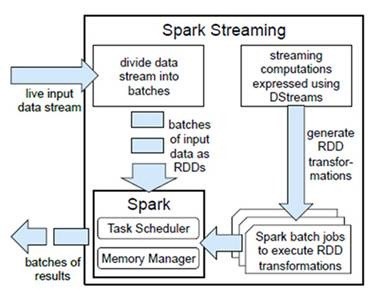
容错性
对于流式计算来说,容错性至关重要。首先我们要明确一下Spark中RDD的容错机制。每一个RDD都是一个不可变的分布式可重算的数据集,其记录着确定性的操作继承关系(lineage),
所以只要输入数据是可容错的,那么任意一个RDD的分区(Partition)出错或不可用,都是可以利用原始输入数据通过转换操作而重新算出的。
实时性
对于实时性的讨论,会牵涉到流式处理框架的应用场景。Spark Streaming将流式计算分解成多个Spark Job,对于每一段数据的处理都会经过Spark DAG图分解以及Spark的任务集的调度过程。
对于目前版本的Spark Streaming而言,其最小的Batch Size的选取在0.5~2秒钟之间(Storm目前最小的延迟是100ms左右),
所以Spark Streaming能够满足除对实时性要求非常高(如高频实时交易)之外的所有流式准实时计算场景。
DStream
Discretized Stream是Spark Streaming的基础抽象,代表持续性的数据流和经过各种Spark算子操作后的结果数据流。在内部实现上,DStream是一系列连续的RDD来表示。每个RDD含有一段时间间隔内的数据,如下图:
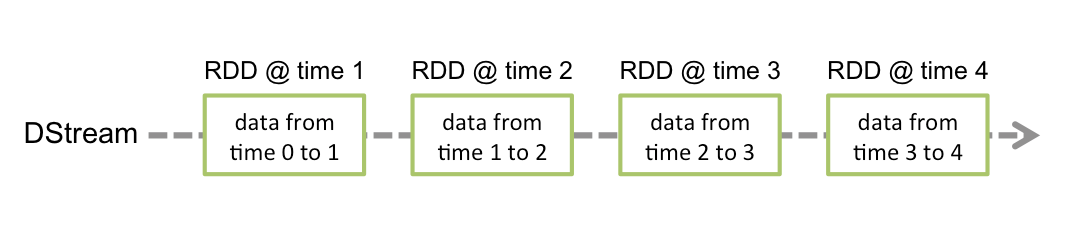
对数据的操作也是按照RDD为单位来进行的
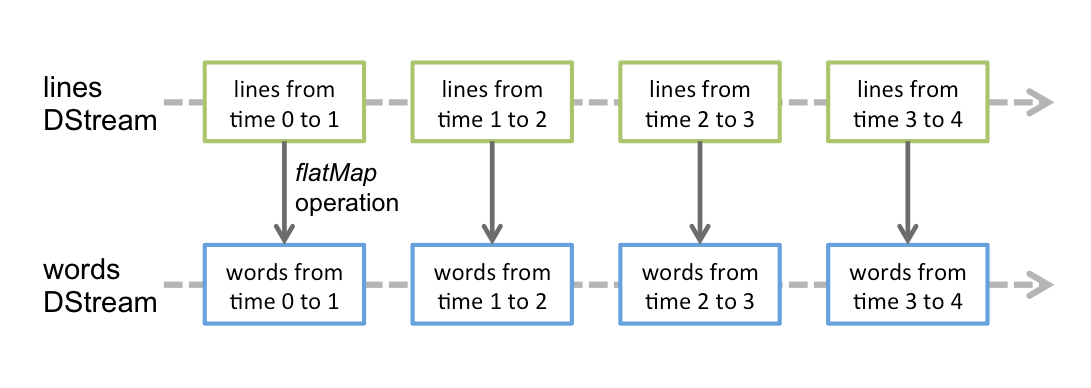
Spark Streaming使用数据源产生的数据流创建DStream,也可以在已有的DStream上使用一些操作来创建新的DStream。
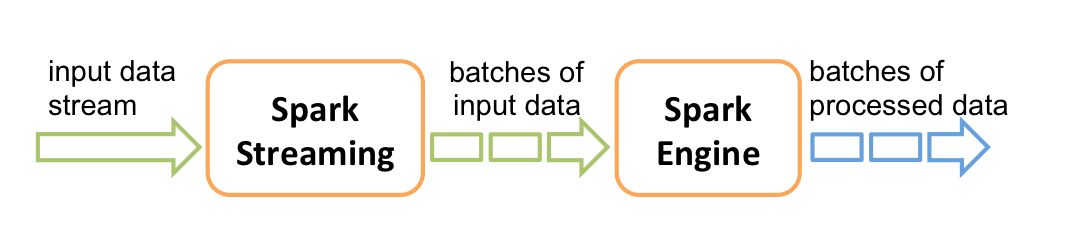
它的工作流程像下面的图所示一样,接受到实时数据后,给数据分批次,然后传给Spark Engine处理最后生成该批次的结果。
DStream相关操作
DStream上的操作与RDD的类似,分为Transformations(转换)和Output Operations(输出)两种,此外转换操作中还有一些比较特殊的操作,如:updateStateByKey()、transform()以及各种Window相关的操作。
Transformations on DStreams
|
Transformation |
Meaning |
|
map(func) |
对DStream中的各个元素进行func函数操作,然后返回一个新的DStream |
|
flatMap(func) |
与map方法类似,只不过各个输入项可以被输出为零个或多个输出项 |
|
filter(func) |
过滤出所有函数func返回值为true的DStream元素并返回一个新的DStream |
|
repartition(numPartitions) |
增加或减少DStream中的分区数,从而改变DStream的并行度 |
|
union(otherStream) |
将源DStream和输入参数为otherDStream的元素合并,并返回一个新的DStream. |
|
count() |
通过对DStream中的各个RDD中的元素进行计数,然后返回只有一个元素的RDD构成的DStream |
|
reduce(func) |
对源DStream中的各个RDD中的元素利用func进行聚合操作,然后返回只有一个元素的RDD构成的新的DStream. |
|
countByValue() |
对于元素类型为K的DStream,返回一个元素为(K,Long)键值对形式的新的DStream,Long对应的值为源DStream中各个RDD的key出现的次数 |
|
reduceByKey(func, [numTasks]) |
利用func函数对源DStream中的key进行聚合操作,然后返回新的(K,V)对构成的DStream |
|
join(otherStream, [numTasks]) |
输入为(K,V)、(K,W)类型的DStream,返回一个新的(K,(V,W))类型的DStream |
|
cogroup(otherStream, [numTasks]) |
输入为(K,V)、(K,W)类型的DStream,返回一个新的 (K, Seq[V], Seq[W]) 元组类型的DStream |
|
transform(func) |
通过RDD-to-RDD函数作用于DStream中的各个RDD,可以是任意的RDD操作,从而返回一个新的RDD |
|
updateStateByKey(func) |
根据key的之前状态值和key的新值,对key进行更新,返回一个新状态的DStream |
特殊的Transformations:
updateStateByKey 用于记录历史记录,保存上次的状态
reduceByKeyAndWindow 开窗函数
Output Operations on DStreams
相当于rdd的action的作用,transformation不会立即执行,到这才会执行
|
Output Operation |
Meaning |
|
print() |
打印到控制台 |
|
saveAsTextFiles(prefix, [suffix]) |
保存流的内容为文本文件,文件名为 "prefix-TIME_IN_MS[.suffix]". |
|
saveAsObjectFiles(prefix, [suffix]) |
保存流的内容为SequenceFile,文件名为 "prefix-TIME_IN_MS[.suffix]". |
|
saveAsHadoopFiles(prefix, [suffix]) |
保存流的内容为hadoop文件,文件名为 "prefix-TIME_IN_MS[.suffix]". |