实验要求
1. 对源文件(*.txt,*.cpp,*.h,*.cs,*.html,*.js,*.java,*.py,*.php等,文件夹内的所有文件)统计字符数、单词数、行数、词频,统计结果以指定格式输出到默认文件中,以及其他扩展功能,并能够快速地处理多个文件。
2. 使用性能测试工具进行分析,找到性能的瓶颈并改进
3. 对代码进行质量分析,消除所有警告
4. 设计10个测试样例用于测试,确保程序正常运行(例如:空文件,只包含一个词的文件,只有一行的文件,典型文件等等)
5. 使用Github进行代码管理
6. 撰写博客
需求分析
PSP表格:
|
PSP2.1 |
任务内容 |
计划完成需要的时间(min) |
实际完成需要的时间(min) |
|
Planning |
计划 |
15 |
15 |
|
Estimate |
估计这个任务需要多少时间,并规划大致工作步骤 |
15 |
15 |
|
Development |
开发 |
1140 |
1880 |
|
Analysis |
需求分析 (包括学习新技术) |
20 |
20 |
|
Design Spec |
生成设计文档 |
30 |
- |
|
Design Review |
设计复审 (和同事审核设计文档) |
10 |
- |
|
Coding Standard |
代码规范 (为目前的开发制定合适的规范) |
20 |
20 |
|
Design |
具体设计 |
20 |
20 |
|
Coding |
具体编码 |
400 |
700 |
|
Code Review |
代码复审 |
40 |
20 |
|
est |
测试(自我测试,修改代码,提交修改) |
600 |
1100 |
|
Reporting |
报告 |
60 |
60 |
|
Test Report |
测试报告 |
20 |
20 |
|
Size Measurement |
计算工作量 |
10 |
10 |
|
Postmortem & Process Improvement Plan |
事后总结 ,并提出过程改进计划 |
30 |
30 |
|
Summary |
合计 |
780 |
- |
设计思路
在开始写程序前,与周围同学进行了讨论,初步形成了以下的思路:
1.因为文件数目多,单词量巨大,使用静态数组储存单词和词组不合适,决定因此建立两个哈希表来储存。
2.对于判断单词是否相同的复杂标准,考虑专门写个函数。
3.对于词组,因为要记录两个单词,因此考虑将这两个单词用一个空格号隔开,记录在一个字符串数组中。
4.读两遍文件,第一遍只考虑单词的记录与重复性的检测,第二遍是对词组的记录以及重复性检测。
5.全部记录好后,对各单词及词组频率进行统计。
代码质量及性能分析
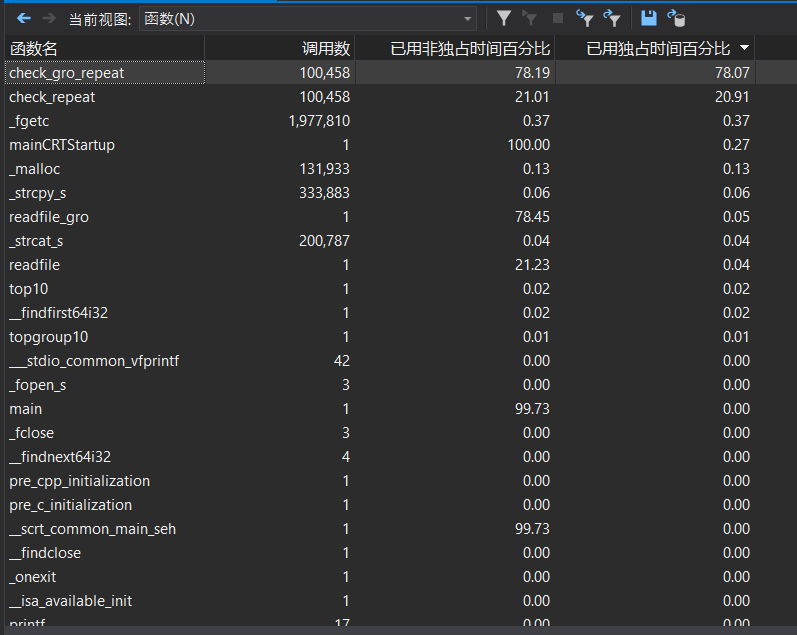
从中可以看出 check_gro_repeat 和 check_repeat 占用时间最长,而这两个函数的功能就是查找是否有重复的词组和单词,需要重新遍历哈希表,因此占用时间最长可以理解。
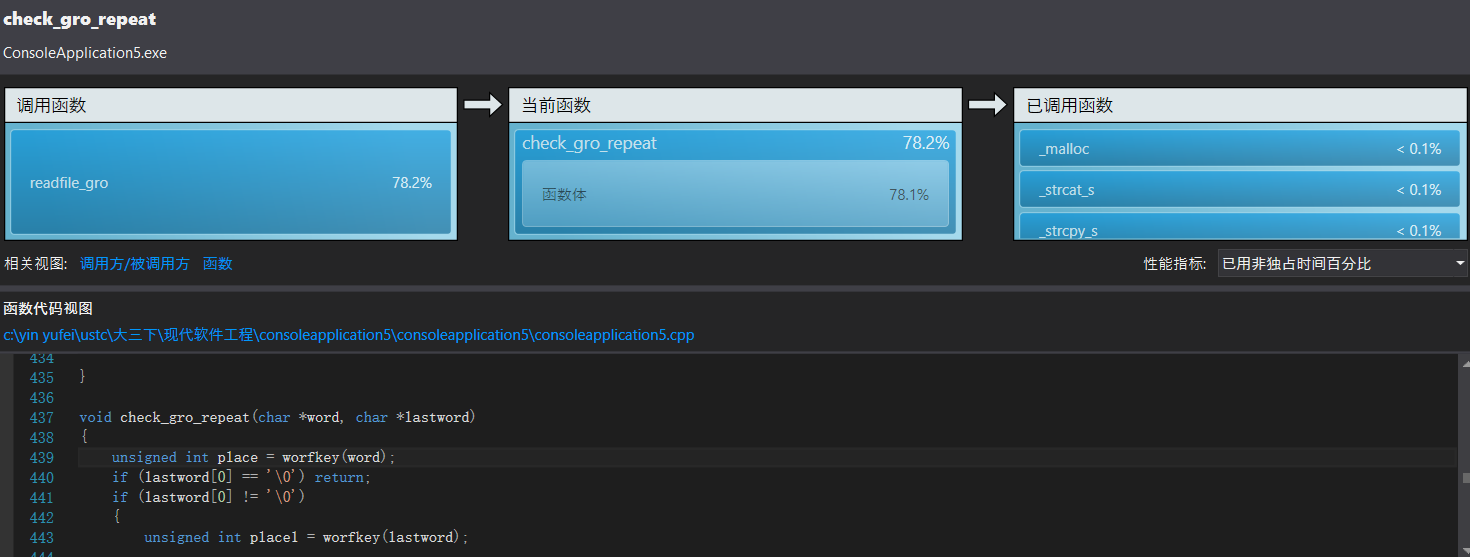
在check_gro_repeat这个函数中,函数体占了最大的比重(其实就是遍历所花的时间),因此为了降低遍历的时间,考虑多增加哈希表的关键码数量。
性能分析的时候,用小文件进行了操作,于是有了这个结果:
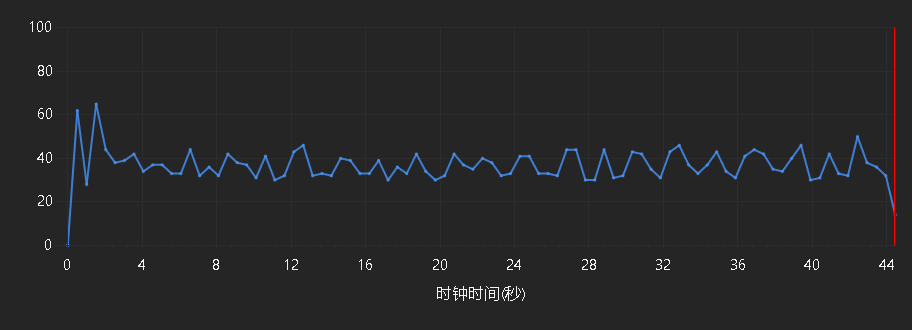
可以看出,处理每个文件的时间基本平均
用例分析和分析过程
和同学一起测试了十多个样例,测试的样例包括了空文件,只包含一个词的文件,只有一行的文件,典型文件等等。一开始出现了一些错误比如显示结果为小写字母,在检查程序后发现是strcmp的判断条件反了,修改后后结果正确。
获取的经验
这次个人作业是我第一次编写一个大程序,从开始着手到最终跑完,我整整花了6个晚上的时间。作为一个新手,面对各种Bug层出不穷的状况有些措手不及,有时就连吃饭、上课的时候也在想代码可能出错的原因。当然,在饱受代码折磨的同时,我也获取了很多宝贵的经验,吃一堑长一智,这些经验的积累必将使我受益。
关于程序之外的:
1.写程序前,一定要统观大局。
说实话,在拿到这个题目时,我并没有意识到这个任务的困难程度。出于早做完早收工的想法,我在稍微思考后,就开始着手写程序。我一开始用的是结构体+静态数组来记录单词和词组,然后花了两个晚上用小文件来调试,在当我好不容易修补完所有的bug后,我跃跃欲试地打开了给的测试文件夹——然后就傻眼了。里面的文件个数与单词数目完完全全超出了我的预计,以至于我能使用的数组数目完全不够。这就意味着我之前的成果只能付之东流。于是,在百般无奈之下,我只能重新编写程序,这大大消耗我花在编程上的时间。
2.多与周围同学交流
“要是你能早点和我们交流,就不至于这样了”,在我第二遍代码运行失败后,我去找我同学帮忙,发现问题后,他意味深长地说了这句话。正如之前所述,第一遍代码是因为低估了单词的数量而偏离了方向,第二遍代码则是因为对于一个模块的运行方式考虑地不够周全而最终流产。一个人的思维能力是有限的,特别对于我这种新手来说,有些地方考虑不周全也在情理之中。但我的身边有许多编程高手,要是我能早点把我的思路与周围同学分享与交流,而不是一个人埋头苦干,我也许就能早点发现漏洞,从而避免再一次地花费无用的精力。
3.CSDN是个好东西
这个就不多说了,很多bug的解决方法以及新学的知识,都是从这上面找到的。
关于程序的:
1.赋初值,赋初值,赋初值!
重要的话要说三遍。代码一半的Bug都是因为没赋初值造成的,忘记赋初值的错误一度让我苦不堪言,也让我花费了大量的时间在这上面。对于数组,如果数组号对应的变量没有赋初值,很容易就会产生越界;对于字符串,如果没赋初值,那就在尾巴处会出现一堆乱码。还有其他许许多多没赋初值造成的问题,不说了,以后定义一个变量随手就赋个初值……
学到的Tip:对于字符串的赋初值 char word[10]={0};
2.永远不要相信%s的打印结果
说实话,对于为什么要这样,我也不知道具体原因,但事实就是如此。在调试代码时,我好几次用%s打印字符串来检查,但发现根本没有问题。但当我使用了for+ %c 输出的时候,一切真相大白了,我字符串中储存的字符远不止%s所显示的结果,这恰恰就是Bug所在。
3.学会利用网络上的一些框架
当我决定用哈希表的时候,我一瞬间有点束手无策,尽管我知道大致的流程,但还是有些无从着手。在想了一段时间后,我决定上网搜搜看建立哈希表的框架,在看完他们的代码后,我庆幸还好没有自己去写,因为有很多细节我估计自己不会想得到的。虽然利用成熟的框架看似有一些“抄袭”的成分,但是其实并不是这样。这也是一种学习的过程。利用好这些框架,不但能省下大把的时间用来优化程序,还能学习一下高手的编程方式,当然有个前提——利用并不等于“抄就完事了”,还需要读懂并理解透它的思路,甚至还可以对它进行适当的优化,这才是真正的利用好框架。
虽然经验看似并不多,但是却是我与代码一星期斗争的缩影。长风破浪会有时,直挂云帆济沧海。以此文献给我的第一次大程序的编写,以及我这难以忘记的一星期时光。