文档操作
最后有几句很重要的话!hhhhhh
1、插入
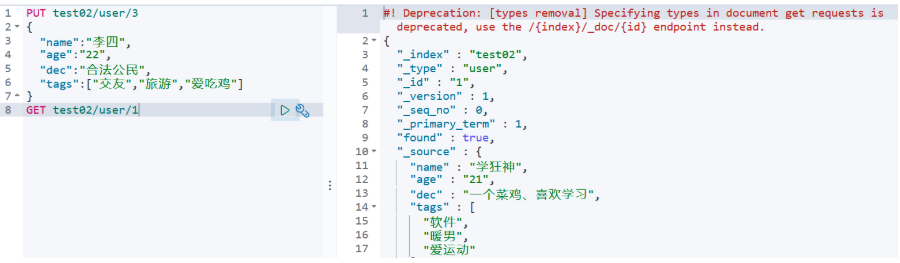
PUT test02/user/3
{
"name":"李四",
"age":"22",
"dec":"合法公民",
"tags":["交友","旅游","爱吃鸡"]
}
2、查询
1、简单查询
2、简单条件查询
GET test02/user/_search?q=name:学狂神
3、 花样查询
1、匹配查询:
GET test02/user/_search
{
"query": {
"match": {
"name": "学狂神"
}
}
}
2、结果过滤
GET test02/user/_search
{
"query": {
"match": {
"name": "学狂神"
}
},
"_source": ["name"]
}
3、排序
GET test02/user/_search
{
"query": {
"match": {
"name": "学狂神"
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
4、分页查询
GET test02/user/_search
{
"query": {
"match": {
"name": "学狂神"
}
},
"from": 0,//从哪开始
"size": 2//显示几条
}
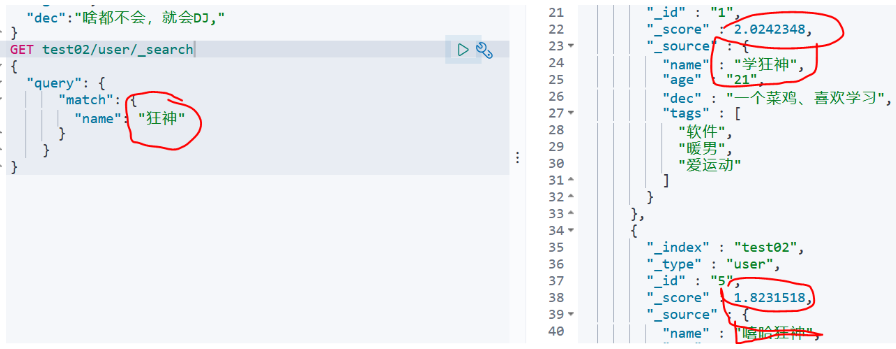
5、bool查询
must:必须都满足,相当于and
GET test02/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "狂神"
}
},
{
"match": {
"age":"21"
}
}
]
}
}
}
should:只需满足其一,相当于or
GET test02/user/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"name": "狂神"
}
},
{
"match": {
"age":"21"
}
}
]
}
}
}
must_not:必须不满足,相当于not
GET test02/user/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"name": "狂神"
}
},
{
"match": {
"age":"21"
}
}
]
}
}
}
6、结果过滤
GET test02/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "狂神"
}
}
],
"filter": {
"range": {
"age": {
"gte": 10,
"lte": 22
}
}
}
}
}
}
7、mach查询
1、有一个匹配都能查出来
GET test02/user/_search
{
"query": {
"match": {
"dec": "合法"//有一个字匹配都会被查到
}
}
}
查出来后他的得分不一样:
1.匹配的词越多越高,
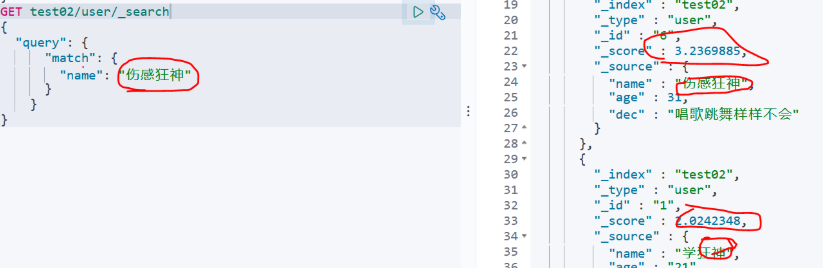
2.当匹配的词相同时,该词在整个字段值中所站比例越高得分越高
2、那么问题来了,有时候想要对text类型进行相对精确查询,怎么办呢?哈哈!方法肯定有:设置and关系
GET test02/_search
{
"query": {
"match": {
"name": {
"query": "伤感王五",
"operator": "and"
}
}
}
}
也就是说必须同时满足所有分词,
3、那么问题又来了!在 or 与 and 间二选一有点过于非黑即白。 如果用户给定的条件分词后有 5 个查询词项,想查找只包含其中 4 个词的文档,该如何处理?将 operator 操作符参数设置成 and 只会将此文档排除。
有时候这正是我们期望的,但在全文搜索的大多数应用场景下,我们既想包含那些可能相关的文档,同时又排除那些不太相关的。换句话说,我们想要处于中间某种结果。
match 查询支持 minimum_should_match 最小匹配参数, 这让我们可以指定必须匹配的词项数用来表示一个文档是否相关。我们可以将其设置为某个具体数字,更常用的做法是将其设置为一个百分数,因为我们无法控制用户搜索时输入的单词数量:
GET test02/_search
{
"query": {
"match": {
"name": {
"query": "伤感DJ舞曲",
"minimum_should_match": "70%"//匹配度
}
}
}
}
匹配算法:这里伤感DJ舞曲可划分为3个词,3*70% 约等于2。所以只要包含2个词条就算满足条件了。
8、精确查询(词条(term)查询)
term查询是直接通过到倒排索引指定的词条进行精确查询
term 查询被用于精确值 匹配,这些精确值可能是数字、时间、布尔或者那些未分词(keyword)的字符串
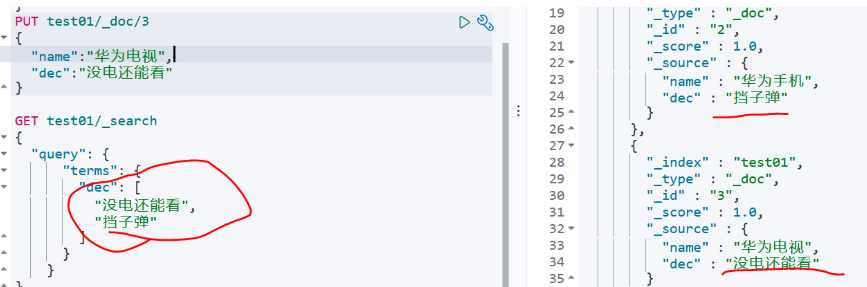
PUT test01/_doc/3
{
"name":"华为电视",
"dec":"没电还能看"
}
GET test01/_search
{
"query": {
"term": {
"dec": {
"value": "没电还能看"
}
}
}
}
terms:terms 查询和 term 查询一样,但它允许你指定多值进行匹配。如果这个字段包含了指定值中的任何一个值,那么这个文档满足条件:
关于字段类型:
核心数据类型
(1)字符串
text ⽤于全⽂索引,搜索时会自动使用分词器进⾏分词再匹配
keyword 不分词,搜索时需要匹配完整的值
(2)数值型
整型: byte,short,integer,long
浮点型: float, half_float, scaled_float,double
(3)日期类型
date
注意 只有text字段会被分词器解析
9、模糊查询
fuzzy 查询是 term 查询的模糊等价。它允许用户搜索词条与实际词条的拼写出现偏差,但是偏差的编辑距离不得超过2:
GET test01/_search
{
"query": {
"fuzzy": {
"dec": {
"value": "MAXDjSO",
"fuzziness": 1
}
}
}
}
10、高亮查询(可自定义高亮效果)
GET test02/_search
{
"query": {
"match": {
"name": "伤感"
}
},
"highlight":{
"pre_tags": "<p style='color:red'>",//前缀
"post_tags":"</p>", //后缀
"fields": {
"name": {}
}
}
}
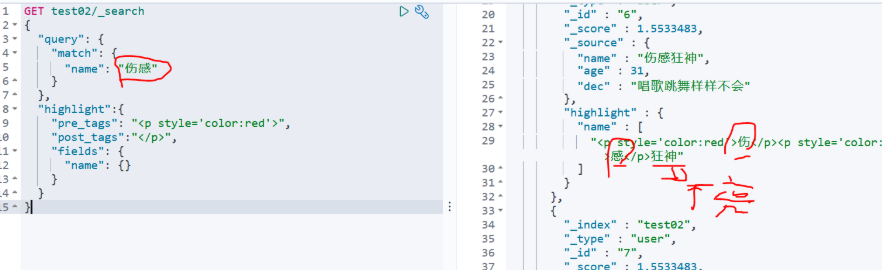
注意:有一个小细节,查询出来的东西,只有伤感这两个字会高亮 想想你在百度搜索,是不是也一样
3、更新
POST test02/user/2/_update
{
"doc":{
"name":"张三121"
}
}
4、删除
DELETE test02/user/1
最后总结一句话很重要的话:必须得自己练,必须得自己练、必须得自己练!只有自己练、自己实验 才会真的明白
如果你是看视频教学,你不自己敲代码可能会明白,但也一定记不住