一、前言
MaxCompute中的python是2.7环境的,可以通过sys.version验证,话说Python社区都准备放弃2.7了,阿里云啥时候跟上时代的步伐升级到3.x哦。
我们测试一下:
| Executing user script with PyODPS 0.8.0 2.7.10 (default, Sep 18 2015, 16:43:46) [GCC 4.1.2 20080704 (Red Hat 4.1.2-51)] |
可以看到数据开发中的PyODPS版本号,以及Python的版本为2.7.10,机器的系统是Red Hat,一个Linux环境。
据官方文档称,Python代码以沙箱模式执行,在一个受限的环境中运行,部分模块是不可用的。所有纯Python实现(不依赖扩展模块)的模块都是可用的,以及部分C实现的模块,所以不要想当然把本地的一些代码直接挪上来,可能某些包是没有的哦。
二、UDF实战
2.1 指定参数和返回值类型
Python UDF目前支持的MaxCompute SQL数据类型包括Bigint、String、Double、Boolean和Datetime。SQL语句在执行之前,必须确定所有函数的参数类型和返回值类型。
参数与返回值的指定方式如下:
@odps.udf.annotate(signature)
很显然,是一个装饰器的写法。
合法的signature如下:
|
'bigint,double->string' # 参数为bigint、double,返回值为string 'bigint,boolean->string,datetime' # UDTF参数为bigint、boolean,返回值为string,datetime '*->string' # 变长参数,输入参数任意,返回值为string '->double' # 参数为空,返回值为double |
2.2 编写UDF函数
实现一个UDF非常简单,只需要定义一个 new-style class,并实现 evaluate方法。
我以一个使用正则表达式匹配方括号内的内容为例,写一个自定义函数:
|
# -*- coding: utf-8 -*-
|
解析1:第一行就是Python2.x版本的历史遗留问题,2.x版本原生对非ASCII字符编码支持很差,需要手动设定编码格式;
解析2:关键就是声明一个类,然后实现evaluate方法,返回结果值即可。
2.3 上传资源
写好的Python代码需要上传为odps资源,在数据开发 > 业务流程 > 资源下,新建资源,选择Python,然后在编辑框里贴入上述代码,提交即可。

2.4 注册函数
成功上传了资源后,在数据开发 > 业务流程 > 函数中右键新建自定义函数。
写一个函数名,资源列表填上刚刚上传的资源文件,类名以 资源名.类名 的格式填写,提交即可。

至此,自定义函数就注册完成了,可以去ODPS SQL节点里测试下这个UDF。
2.5 使用函数
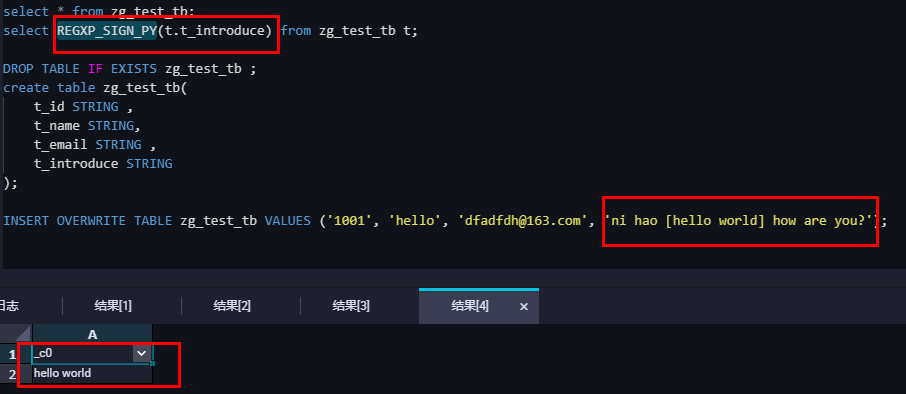
三、后话
除了这种最简单的UDF外,ODPS也支持UDTF和UDAF,详情见表格:
UDF分类 描述
UDF(User Defined Scalar Function) 用户自定义标量值函数(User Defined Scalar Function)。其输入与输出是一对一的关系,即读入一行数据,写出一条输出值 。
UDTF(User Defined Table Valued Function) 自定义表值函数,是用来解决一次函数调用输出多行数据场景的,也是唯一能返回多个字段的自定义函数。而UDF只能一次计算输出一条返回值。
UDAF(User Defined Aggregation Function) 自定义聚合函数,其输入与输出是多对一的关系, 即将多条输入记录聚合成一条输出值。可以与SQL中的Group By语句联用。
如果之后有需求,可以尝试写写UDTF和UDAF,这次到这里就结束啦。
————————————————
原文链接:https://blog.csdn.net/zhchs2012/article/details/89712537